如题,存在不一致的情况,例如python推理结果经过NMS后的置信度为0.92,但板端的置信度可能为0.89,且板端检测框尺寸和中心点相比python存在一些偏差。
继续调试,在NMS之前,置信度最高的目标框从尺寸特征图(40*40)的w=16,h=15的网格中的第二个anchor解码得到,在python中的结果不对应。
其次,直接对比了特征图的前10行结果,发现与python的结果也不一致。
请问这可能是由于在模型量化过程中导致的误差吗?

如题,存在不一致的情况,例如python推理结果经过NMS后的置信度为0.92,但板端的置信度可能为0.89,且板端检测框尺寸和中心点相比python存在一些偏差。
继续调试,在NMS之前,置信度最高的目标框从尺寸特征图(40*40)的w=16,h=15的网格中的第二个anchor解码得到,在python中的结果不对应。
其次,直接对比了特征图的前10行结果,发现与python的结果也不一致。
请问这可能是由于在模型量化过程中导致的误差吗?



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.5
Lv.5
我在X86用hb_verifier工具导出了模型的输出,发现使用X86的quantized.onnx和bin的输出是一致的,这里bin用的x86的libdnn推理的。这是不是说明是由于板端和x86差异造成的?
可以再用hb_verifier比较下quantized.onnx和板端运行bin的输出一致性
我在板端用hrt_model_exec工具dump了结果,肉眼看了看也几乎是能对上,现在怀疑是不是特征图出来之后的遍历循环取值有问题。
另外有个小问题,我在x86中用hb_verifier工具 -b的选项会报错,导致我只能打开-s:
并且在板端我需要通过/userdata/.horizon/hrt_model_exec才能执行工具,如果直接hrt_model_exec是找不到的。我是按照OE中直接bash install.sh $ip$安装的。我怀疑这个-b报错和这个问题有关,导致无法检测到板端的dnn工具。
如果板端的bin和x86的quantized.onnx输出的数值是完全一致的,那么造成检测结果不一致的原因就只能是后处理了
发现问题出在输出不一致
用hb_verfier和hrt_model_exec工具dump的结果都是一致的,但是我直接在python里把特征图存成npy看就不一致了,且各自的后处理都没问题
请问使用工具验证的onnx模型和python中推理的图像预处理是否有不同?
"直接在python里把特征图存成npy看就不一致了",这句话没太理解,可以详细说一下么
最开始的问题是板端和x86的检出不一致,然后通过 hb_verfier和hrt_model_exec工具对比了输出特征图发现是一致的。
但是这样就没法解释为什么检测框会不同。因此分别找到了x86和板端的输出检测框对应的特征图是model_output[1],也就是40*40大小的特征图
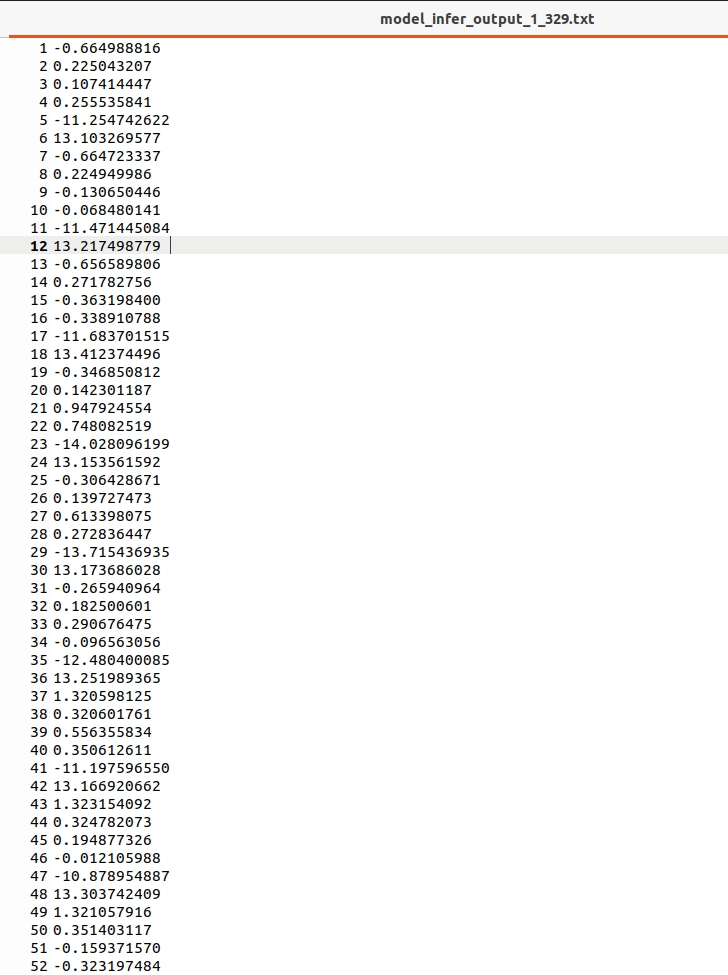
板端对应的特征图结果是:
然后在python中通过np.save直接保存model_output[1],根据检出的置信度0.92找到了对应的输出:
根据confidence=sigmoid(2.4454216957092285)*sigmoid(13.594114303588867)=0.92
证明python端的检出结果是正确的。
但是在输出的板端特征图中是找不到对应的python的特征图结果,也就是结果并不一致!但这和工具得到的结果矛盾。所以怀疑hb_verfier工具是否使用了和ai_benchmark示例中不同的preprocess导致了输入不同?
x86端保存结果和bin模型输出不一致:
在这里存的output。
x86:

板端:
看起来确实不一致,你的input_type_rt和input_type_train是什么?最近发现有个BUG,在这两个参数都是rgb或者bgr的情况下,quantized.onnx和bin可能会出现不一致的情况,但如果rt是nv12,train是bgr/rgb,结果就一致了。
是转模型用的配置文件吗?应该是没问题的:
那我就不明白了,按理说J5上不应该有这个问题。你能确认输入数据是按我说的准备的吗,quantized.onnx用的是bgr转的nv12转的yuv444再转的yuv444-128,bin用的是bgr转的nv12?
在python的preprocess是:
在C++里应该是在tensor_utils.cc里,image_data_type== HB_DNN_IMG_TYPE_NV12:
Lv.3这个有可能是量化过程中的误差。对比过输入的数据吗?是不是完全一样的。也可能输入的数据不一样导致的。
输入的图像是一样的,C++的预处理和python版本的预处理会导致输入数据产生变化吗?
图像是一样的,那图像经过预处理之后还是一样的吗? 有没有对比一下输入推理之前的数据?
Lv.2我用x86的hb_verfier工具可以看到bin和quantized.onnx是一致的,在板端直接用hrt_model_exec直接输出output也是一致的,但是在C++里直接打印出来就对不上。