J5 J5_OE_1.1.74
在calibration和QAT量化感知训练过程中都有以下这一相似操作,如果引用了自己的模型,这一部分该如何修改呢

J5 J5_OE_1.1.74
在calibration和QAT量化感知训练过程中都有以下这一相似操作,如果引用了自己的模型,这一部分该如何修改呢


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.3
Lv.3那就把自己的模型,按照要求递归地处理所有层级。
Lv.5对这部分的代码进行一下说明吧,有了下面的说明,你应该就知道了:
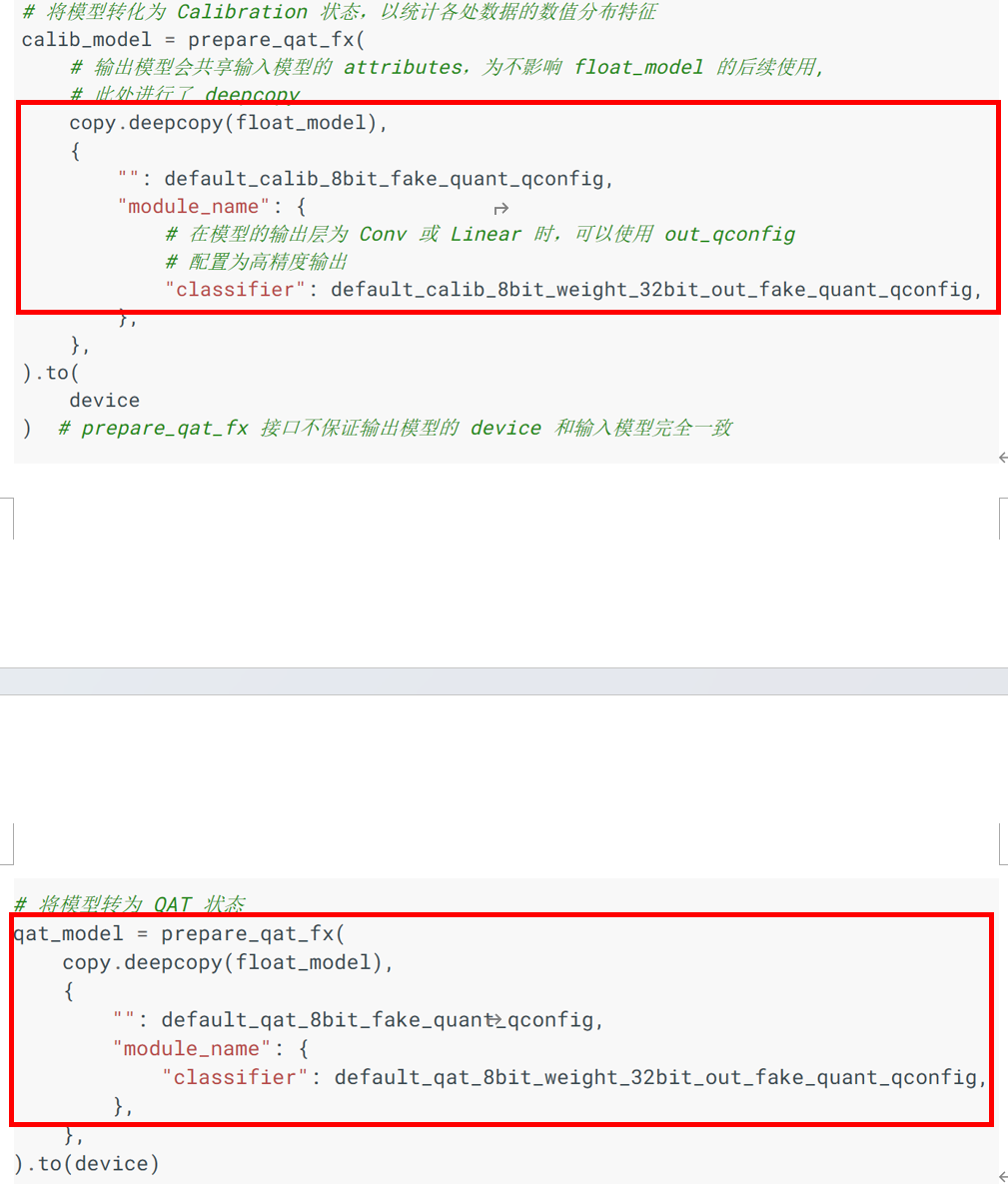
copy.deepcopy(float_model): prepare_qat_fx内部对于模型参数的使用类似于C++中的指针引用,对模型是就地修改的,为了不影响引用的float_model,对模型进行了深度拷贝。
下面的部分是量化配置信息,如下为注释部分:
自己的模型,如果输出部分是conv或linear, 可以按照上面这个这设置,如果不是,使用常规的 {"": get_default_qat_qconfig()}就OK
Lv.3鉴于您长时间未回复,此问题就先关闭了,如还有问题,可再发帖求助。
