
专栏算法工具链关于征程6的几个问题2
关于征程6的几个问题2
已解决
快乐的打工人2024-06-04
99
9
算法工具链
征程6


+5
评论9
0/600
 gaoh
gaoh'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.1
Lv.11.征程6提供专用硬件加速IP例如pym、resizer和gdc等来提高图像处理的速度;
3.征程6算法工具链原生支持pytorch,通过支持onnx来支持其他DL框架;
4.征程6为端侧部署平台,只有量化训练涉及模型训练,训练策略和DL框架下的浮点保持相同
2024-06-0400 wawaLv.1
wawaLv.1J6集成有BPU/GPU/VDSP/ISP等硬件加速器来提升图像处理的速度。
2024-06-0400- 费小财Lv.5
2,远程监控和调试是可以支持的,但是需要自己去实现对应的协议
2024-06-0400 - 费小财Lv.5
>征程6在未来会有哪些升级或改进的计划,以满足不断变化的自动驾驶需求?
可参考征程J6P的参数规格
2024-06-0400  DR_KANLv.5
DR_KANLv.5J6的BPU升级到了纳什架构,针对各种视觉Transformer,以及端到端的自动驾驶方案做出优化,并且J6家族全面覆盖低算力到大算力,为从低阶到高阶的智驾方案落地和差异化的市场需求提供更全面的基础支撑。
Transformer高效支持
J6的BPU提供了VAE(Vector Acceleration Engine)计算单元用于vector计算加速,DTE(Data Transformer Engine)计算单元提供灵活高效的数据排布变换,AAE(Auxiliary Acceleration Engine)计算单元处理Transformer中的部分特定计算,因此相比于J5和J3,J6对Transformer的推理性能有了显著的提升。
浮点计算支持
J6的BPU提供了一个针对浮点数据的VPU(Vector Processing Unit)计算单元,支持FP16和FP32,可高效处理vector数据。
分支能力支持
J6的BPU还提供了SPU(Scaler Processing Unit)计算单元用于标量计算,支持处理if条件判断、loop循环等,从而减少了J5上必须要拆图(放在CPU上处理)的数据换入换出性能开销。
更强的CPU算力
J6E和J6M均使用了6个A78,J6E的CPU主频为1.5GHz,J6M的CPU主频为2GHz,因此对于模型中存在的CPU算子,J6的计算会更加高效。
更大的带宽支持
J6计算平台分配给模型推理的DDR带宽有显著的提升,因此模型编译时可以专注在延时的优化而非带宽占用。
多batch模型
对于J5等中高计算能力平台,小分辨率输入或者小计算量的模型往往不能获取高效的计算效率,针对这种情况,可以通过多batch模式来部署模型。
大分辨率输入
除了多batch模式外,增大模型的输入分辨率也可以获取更加高效的计算效率,如采用720P、1080P等更贴合实际业务落地场景的分辨率进行评测。
GroupConv结构
J5计算平台针对GroupConv以及DepthwiseConv都做了针对性的优化,所以更推荐使用MobileNet、EfficienNet等结构作为模型的Backbone。
批量推理小模型
推理任务每执行一次,系统底层都需要响应一次中断,如果每个小模型都放在一个单独的推理任务中,那么中断出现的频率会升高,导致耗时增加。如果将多个小模型绑定到一个推理任务中,就会减少系统底层中断次数,从而降低系统开销,减少耗时。
2024-06-0400 Damon_GuLv.2
Damon_GuLv.22、远程监控和调试,目前J6上可以通过远程推流将本地需要回传的监控信息:如CPU负载,DDR占用等系统资源和异常信息回传至云端进行监控,通常需要根据需求具体应用实现该功能
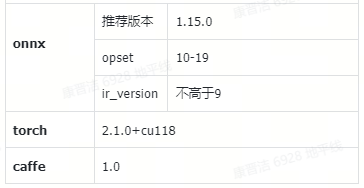
2024-06-0400- 默Lv.1Pytorch框架支持导出为onnx进行模型转换编译,也提供了量化插件用于直接转换编译torch module;支持直接转换caffe模型;其他框架导出为onnx即可。DL框架支持版本如表所示:
 2024-06-1300
2024-06-1300 - 遥看瀑布挂前川Lv.2
问:在征程6上进行模型训练时,有哪些推荐的超参数优化策略?
答:征程6是做部署的,是基于训好的浮点模型做量化,然后编译生成二进制文件,部署到板端做推理。浮点训练和J6部署问题不想管,如果想咨询QAT训练的超参数配置,可以参考建议1:QAT模型训练上,训练策略选择建议使用以下方式:建议1:QAT模型训练上,训练策略选择建议使用以下方式: 建议2:QAT模型量化上,建议将输出的conv配置int32量化,如果 BPU 性能等原因需要量化输出,建议使用 int16 量化,保证量化精度。建议3:在qat前做calib,calib尝试代价较低,可以为QAT提供更好的初始参数,缩短QAT训练时长,加速收敛。甚至对部分模型仅做calib就可以达到预期量化精度。2024-06-1300
建议2:QAT模型量化上,建议将输出的conv配置int32量化,如果 BPU 性能等原因需要量化输出,建议使用 int16 量化,保证量化精度。建议3:在qat前做calib,calib尝试代价较低,可以为QAT提供更好的初始参数,缩短QAT训练时长,加速收敛。甚至对部分模型仅做calib就可以达到预期量化精度。2024-06-1300 - 加格德尔Lv.1
> 征程6在未来会有哪些升级或改进的计划,以满足不断变化的自动驾驶需求?
在后续J6P/J6H/J7可能会支持更大的内存容量,更高的访存带宽,以及可能尝试不同类型的内存
2024-06-1400
目录