用户您好,请详细描述您所遇到的问题,详细的描述有助于帮助我们快速定位,解决问题~Thanks♪(・ω・)ノ
1. 芯片型号:J5
2. 天工开物开发包 OpenExplorer 版本:8 J5_OE_1.1.68
3. 问题定位:板端部署等
参考这个教程,可以生成数据类型为float32的pos_embed.npy文件,此文件就是板端非图像的输入信息吗。但hbm模型的输入信息如下:
input[1]:
name: arg0[pos_embed]
input source: HB_DNN_INPUT_FROM_DDR
valid shape: (1,256,60,20,)
aligned shape: (1,256,60,32,)
aligned byte size: 491520
tensor type: HB_DNN_TENSOR_TYPE_S8
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: SCALE
stride: (491520,1920,32,1,)
scale data: 0.296522,0.296522.......(256个相同的scale)
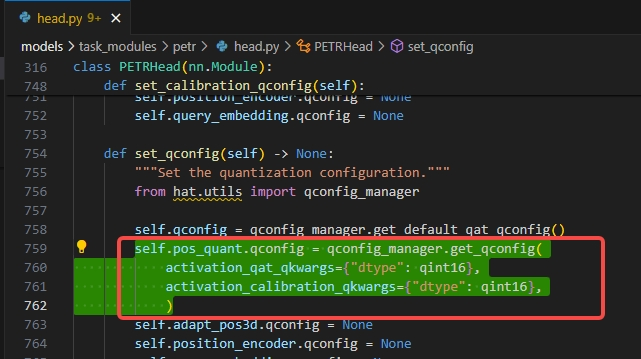
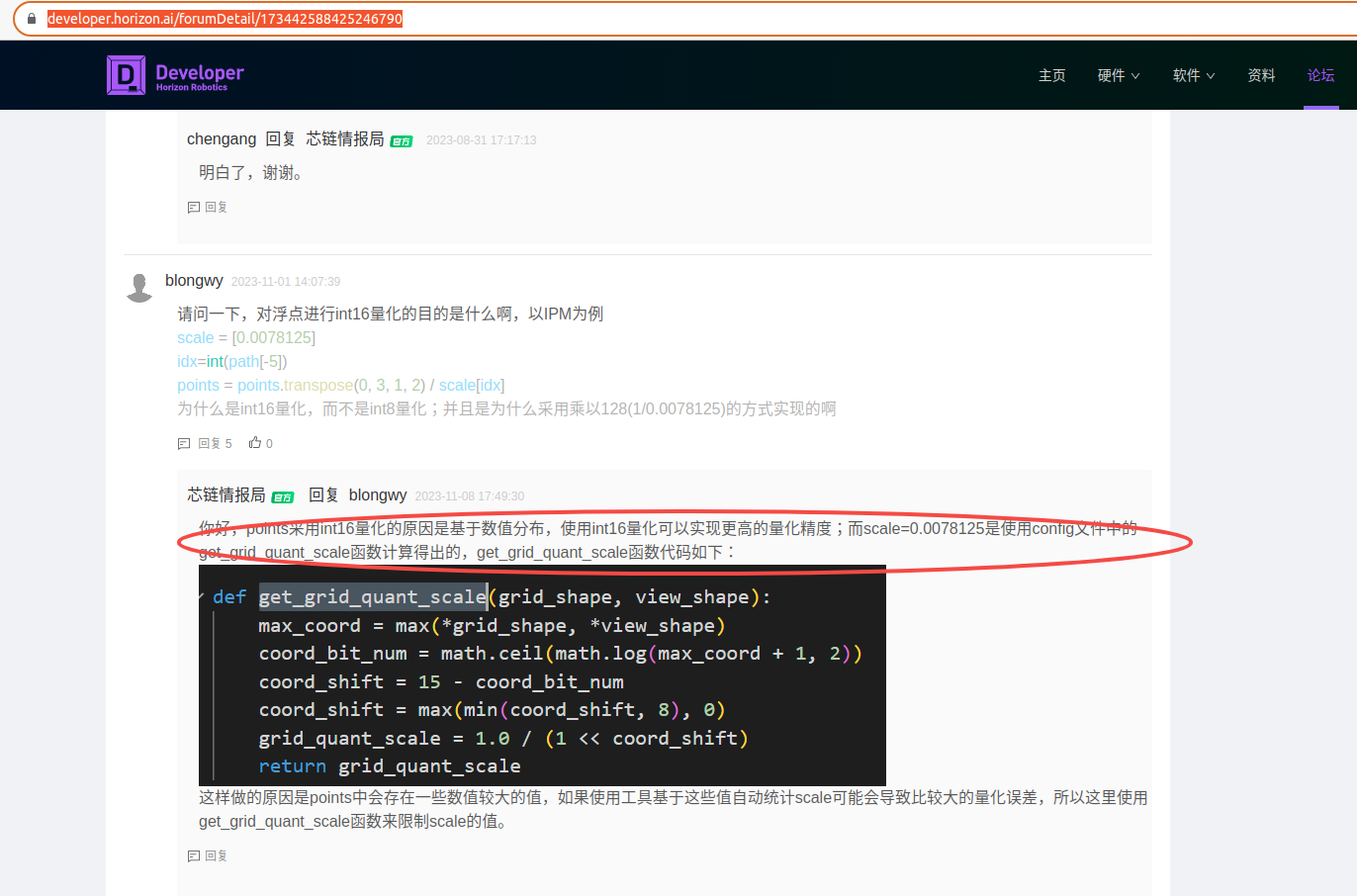
也就是数据类型要求int8,上述输入准备教程中也有对浮点Points做量化的过程,量化的scale就是hbm模型中读出来的 0.296522吗?我这样对参考点量化成int8,这个过程哪里有问题吗?与教程中量化成int16比较,主要就改了clip的范围从int16变成int8,数据类型从int16变成int8。
(qat量化后的pth模型pc端推理正确,pc端推理的未经过post_progress的输出和板端hbm模型的原始输出不一致,所以我们怀疑是板端hbm模型的输入不对)
麻烦帮忙看一下,谢谢
scale = [0.296522]
points = np.load(path)
idx=int(path[-5])
points = points.transpose(0, 3, 1, 2) / scale[idx]
points = np.floor(points + 0.5)
points = np.clip(points, -128, 127)
points = points.astype(np.int8)
points.tofile(save_name+".bin")



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
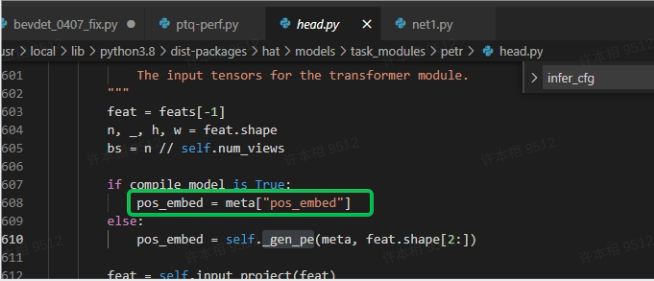 到文件中,上面保存数据时
到文件中,上面保存数据时