
目录
- 1. 必要步骤速览
- 2. 各步骤详解
- 2.1 浮点模型准备
- 2.2 数据校准
- 2.3 量化训练
- 2.4 定点转换
- 2.5 模型编译
- 3. 常见问题
理论多说无益,那浮点模型到 QAT模型的“最后一公里”该如何快速抵达呢?Pytorch 1.8之后推出的torch.fx(官方文档)可以自动跟踪模型forward过程,能大大降低QAT的使用难度,对应的量化方案:FX Graph Mode Quantization,相较于 Eager Mode Quantization 其自动化程度会高很多,相应地操作复杂度也低一些,但也需要用户适当的调整模型以使得模型满足“symbolically traceable”。下面我们就直接来看一下具体步骤吧:
1. 必要步骤速览
强烈建议在量化训练前(甚至是浮点模型设计阶段)先跳过训练过程完整走完prepare->convert->check步骤,确保模型可被硬件支持。
2. 各步骤详解
2.1 浮点模型准备
a. 请使用足够的数据量将浮点模型正常训练至收敛后再进行量化训练。 b. 强烈建议对输入数据进行归一化处理,有利于浮点收敛的同时也可使得模型对量化更友好。 c. 建议您在浮点模型设计阶段对照算子支持列表,避免使用不支持的算子导致后续prepare qat或者编译报错。 d. 若模型中使用了cpu算子,且您确认需要将其编译进模型中,可参考用户手册 4.2.4.4. 异构模型指南进行转换编译。 e. 更多关于如何搭建量化友好模型的说明可参考用户手册 4.2.4.1浮点模型的要求 |
虽然fx mode相较于eager mode对原始浮点模型代码侵入较小,但仍然需要对浮点模型做一些必要的改造以支持后续量化操作。
在模型输入前插入 QuantStub节点,在模型输出后插入 DequantStub节点。有如下注意事项:
多个输入仅在 scale 相同时可以共享 QuantStub,否则请为每个输入定义单独的 QuantStub
建议使用horizon_plugin_pytorch.quantization.QuantStub 默认动态统计输入scale,若是可提前计算出scale的场景建议手动设置scale(例如bev模型的homo矩阵),对应的公版接口torch.quantization.QuantStub不支持手动设置。
建议模型前后处理、loss等不需要量化的部分不要写在模型forward函数里,避免被误插入伪量化节点,进而影响模型精度。
- 对于动态控制流以及一些python内置函数等symbolic trace不支持的操作(可查看官方说明),需要单独定义并使用 wrap 修饰,推荐写法如下:
def test(self, x):
if self.training:
pass
···
x = self.test(x)
return x
2.2 数据校准
2.3 量化训练
量化训练一些推荐的超参配置如下表所示:
超参 | 推荐配置 | 高级配置(如果推荐配置无效请尝试) |
LR |
从0.001开始,搭配StepLR做2次scale=0.1的lr decay
2. LR 更新策略也可以尝试把 StepLR 替换为 CosLR。
3. QAT使用AMP,适当调小lr,过大导致nan。 Epoch 浮点epoch的10% 1. 根据loss和metric的收敛情况,考虑是否需要适当延长epoch。 Weight decay
与浮点一致 1. 建议在4e-5附近做适当调整。weight decay过小导致weight方差过大,过大导致输出较大的任务输出层weight方差过大。 optimizer 与浮点一致 1. 如果浮点训练采用的是 OneCycle 等会影响 LR 设置的优化器,建议不要与浮点保持一致,使用 SGD 替换。 transforms(数据增强)
与浮点一致
1. QAT阶段可以适当减弱,比如分类的颜色转换可以去掉,RandomResizeCrop的比例范围可以适当缩小 averaging_constant(qconfig_params)
weight averaging_constant=1.0
activation averaging_constant=0.0
2. weight averaging_constant一般不需要设置成0.0,实际情况可以在(0,1.0]之间调整
量化训练阶段的调参建议可以参考用户手册 量化训练精度调优建议。
2.4 定点转换
请注意,定点模型和伪量化模型之间无法做到完全数值一致,所以请以定点模型的精度为准。若定点精度不达标,仍需要继续进行量化训练,建议多保留几个epoch的qat模型权重,便于寻找最优的定点精度。(qat或者calibrate精度高并不一定代表定点精度高,可以考虑进行一些回退,平衡最终的定点精度)
在正常情况下,定点模型的精度与板端部署精度是可以保持完全一致的,因此可使用该模型来评测最终部署精度。
2.5 模型编译
模型编译阶段包括以下三个步骤:
compile_model()更多配置项请参考 用户手册-模型编译
若使用了rgb/bgr格式训练模型,部署时设置input_souce为pyramid或resizer,需要在trace之前手动插入预处理节点centered_yuv2rgb和centered_yuv2bgr ,具体可参考用户手册-RGB888 数据部署。
3. 常见问题
答:prepare_qat_fx以及convert_fx接口均不支持 inplace 参数,因此这两个接口的输入和输出模型会共享几乎所有属性,因此建议使用deepcopy复制一份,确保不改变原始输入模型。若无需保留输入模型,且未使用deepcopy,请不要对输入的模型做任何修改。
2. 为何要设置高精度输出?
答:依据神经网络量化背景中的介绍可知乘法累加器计算得到的激活值是int32的,为了让下一层op可以继续计算,会经过requantization的操作转为int8/int16,因此若最后一层是conv/linear节点的话,建议设置高精度输出,使得模型可以以int32格式直接输出,对精度保持情况大有裨益。
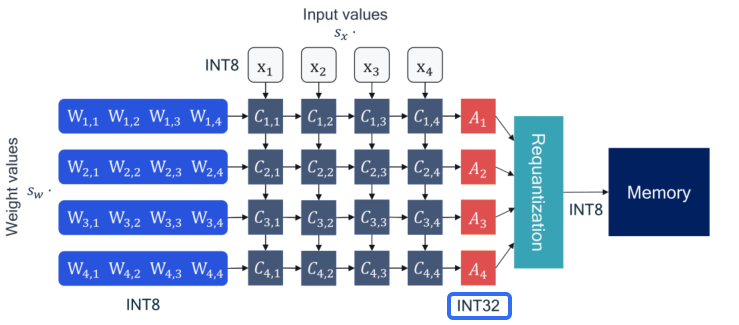
此外,在prepare qat之前通过`model.classifier.qconfig = default_qat_8bit_weight_32bit_out_fake_quant_qconfig`配置高精度输出也是可以的,且该方式优先级高于prepare时通过dict传入qconfig配置。 > plugin ≤ v1.6.2 配置高精度输出需使用 default_calib_out_8bit_fake_quant_qconfig ,但该参数将在后续版本中被废弃
fake quantize 一共有三种状态,分别需要在 QAT 、 calibration 、 validation 前使用set_fake_quantize将模型的 fake quantize 设置为对应的状态。在 calibration 状态下,仅观测各算子输入输出的统计量。在 QAT 状态下,除观测统计量外还会进行伪量化操作。而在 validation 状态下,不会观测统计量,仅进行伪量化操作。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)