
1 前言
对于J5这样的中高计算能力平台,小分辨率输入或者小计算量的模型往往不能达到较高的计算效率,对此可以通过batch模式部署模型(batch>1),一次推理多张图片,从而提高计算/访存比。J5支持在模型转换时配置yaml文件中的input_shape或者input_batch参数编译batch模型。J5也支持在板端部署时对batch模型做推理,本文将会对batch模型的编译和部署做详细说明。
2 Batch模型编译
对于动态输入模型,比如输入为?x3x224x224,必须使用input_shape参数指定模型输入信息。当配置input_shape为1x3x224x224且是单输入模型时, 想编译得到多batch的模型,可以使用 input_batch 参数,当配置input_shape的第一维为大于1的整数时,原模型本身将会认定为多batch模型,将无法使用 input_batch 参数。
对于非动态输入的模型,当输入的input shape[0]为1 且是单输入模型时,可以使用 input_batch 参数,当输入的input shape[0]不为1,则不支持使用 input_batch 参数。换句话说,input_batch 参数仅在单输入且 input_shape 第一维为1的时候可以使用。如果想以batch方式编译多输入模型,需要在原本的开源框架(pytorch,tensorflow等)导出onnx时就设定好模型不同输入分支的batch参数,地平线工具链支持多个输入分支有相同batch和不同batch的情况。
此外,对于动态输入的模型,如果配置input_shape的第一维为大于1的整数时,那么校准数据的shape需要和此时的input_shape对齐。在其他情况下,校准数据的shape不需要特殊处理,为1x3x224x224即可。
3 Batch模型部署
3.1 示例介绍
OE包的ddk/samples/ai_toolchain/horizon_runtime_sample目录包含了板端部署的大量基础示例,该目录的文件结构如下:
本文示例位于02_advanced_samples目录下的nv12_batch,该示例会运行一个batch为4的googlenet_4x224x224_nv12.bin分类模型,读取4张jpg图片进行两次前向推理,两次前向推理的区别在于内存分配的方式不同,最终经过后处理得到两组Top5分类结果。
在正式学习代码前,希望开发者已经熟悉地平线提供的板端部署API,这部分可以查看工具链手册的BPU SDK API章节,这个章节除了详细介绍API接口,还全面介绍了板端部署有关的数据类型、数据接口等信息,以及数据排布与对齐规则、错误码等等。您也可以一边阅读示例代码,一边翻看API手册进行学习。
此外,建议刚开始接触工具链的开发者优先阅读《模型推理快速上手》一文,该文对horizon_runtime_sample的示例代码00_quick_start做了细致的解读,由于nv12_batch的代码结构与00_quick_start相近,因此本篇教程的重点会放在batch模型相关的部分。
3.2 程序结构
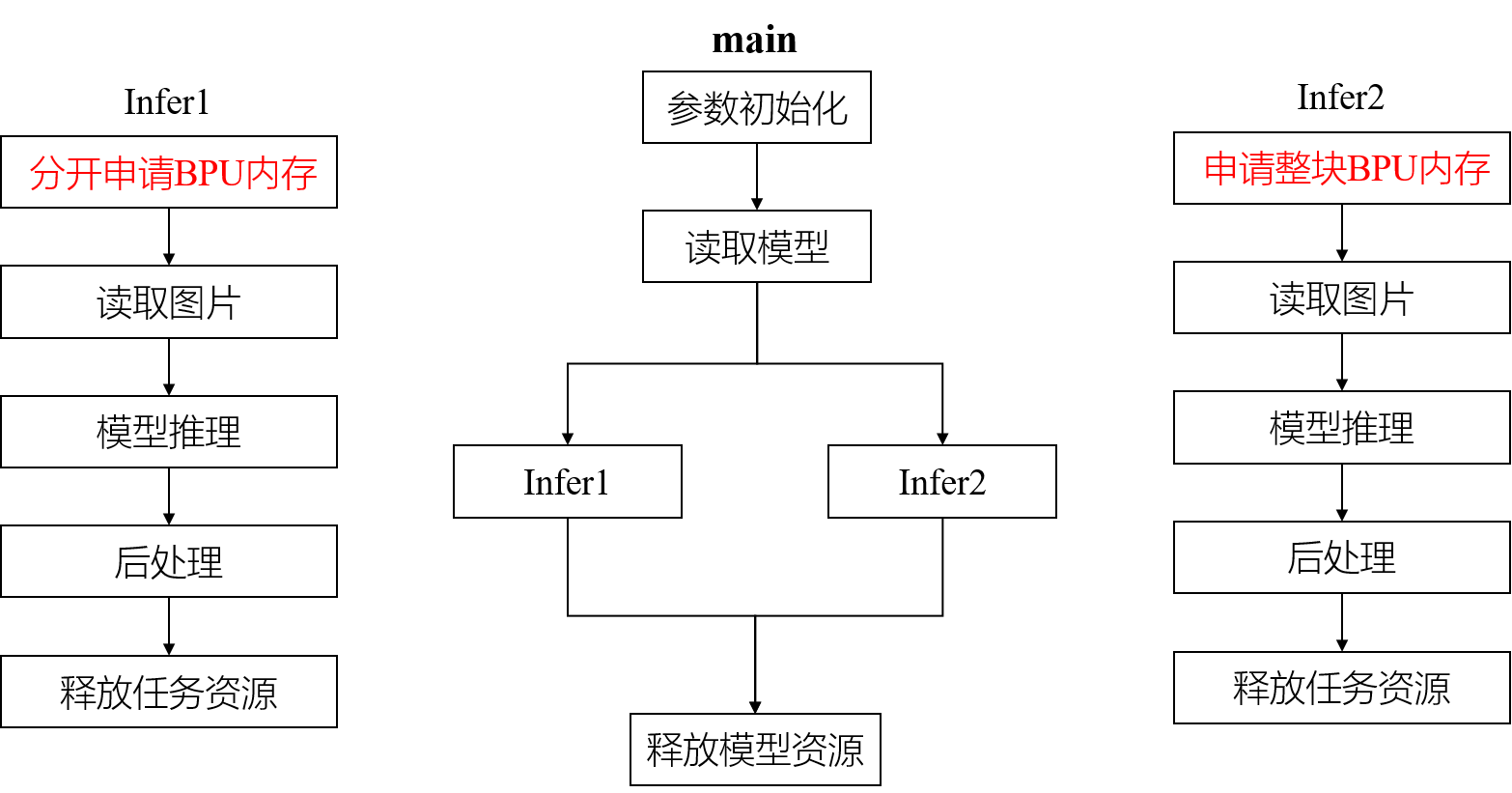
两种方法都属于batch模型推理,开发者可以针对不同的使用场景选择不同的内存分配方法。比方说,如果在J5上部署了一个batch为4的模型,用于处理4个摄像头采集的数据,那么考虑到1帧数据的4张图会存放在不连续的4块内存上,因此需要使用Infer1的方法做batch模型的推理。再比方说,如果只是做回灌,读取本地已有图片做推理,那么就可以使用Infer2的方式,将4张图存在一整片连续的内存空间中再进行batch模型的推理。
接下来,分别对Infer1和Infer2的关键代码进行分析。
3.3 Infer1代码解读
对于Infer1,核心代码是自定义函数prepare_tensor_batch_separate和read_image_2_tensor_as_nv12_batch_separate。
对于Infer1这种分开申请内存的推理方法,需要重新配置当前tensor的对齐后字节大小和有效shape第一维的数值,前者需要将input.properties.alignedByteSize配置为batch_size,即单个输入数据的对齐后字节大小,后者需要将input.properties.validShape.dimensionSize[0]设置为1。这样在实际推理的时候,板端推理库才能正确解析输入tensor的信息。
在j和batch的for循环中,每次循环都会使用地平线封装的内存分配接口hbSysAllocCachedMem为输入tensor分配batch_size大小的内存空间,循环的次数为batch。也就是说,prepare_tensor_batch_separate函数用于循环和batch相同的次数为每个输入数据分别申请内存。
函数read_image_2_tensor_as_nv12_batch_separate使用循环的方式,重复batch次数依次读取该batch内每个张量的长宽信息(input_tensor.size()和batch相等),之后再依次将每份输入数据拷贝进对应的内存空间。
3.4 Infer2代码解读
对于Infer2,核心代码是自定义函数prepare_tensor_batch_combine和read_image_2_tensor_as_nv12_batch_combine。
prepare_tensor_batch_combine函数用于一次为batch内所有输入数据申请整块的连续内存,变量input.properties.alignedByteSize为所有输入数据对齐后在内存上占用的字节大小的总和。
函数read_image_2_tensor_as_nv12_batch_combine使用循环的方式,循环batch次,依次将每份输入数据存进整块连续的内存空间中,其中变量data表示每份数据在内存中的首地址,batch_size表示每份数据占有的对齐后的字节大小。
3.5 板端运行
这个示例在J5开发板上运行的终端打印信息如下:
可以看到,终端打印了两次推理的Top5分类结果,并且结果是完全一致的。
4 性能对比
为了直观展示J5上batch模式对小模型带来的性能提升,这里提供几组实验数据以供参考。
4.1 实验条件
J5系统软件版本:LNX5.10_REL_PL3.0_20221128-161022 release
J5工具链版本:1.1.49b
模型来源:horizon_model_convert_sample/03_classification/02_googlenet
模型输入排布:NCHW
模型输入尺寸:1x3x224x224、8x3x224x224
性能测试工具:hrt_model_exec
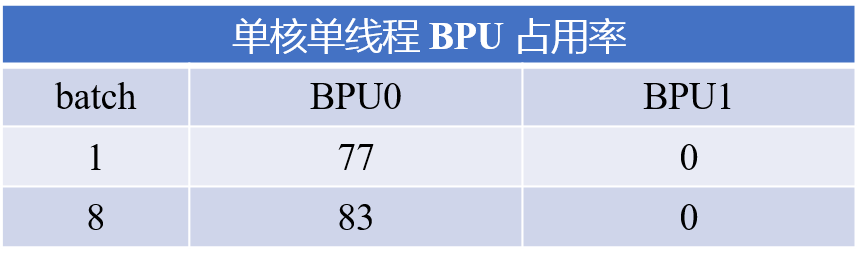
4.2 单核单线程BPU占用率对比
使用hrt_model_exec工具的perf功能,以单核单线程方式运行,并使用hrut_bpuprofile -b 2 -r 0指令查看BPU占用率。可以看到在batch=8的情况下,单核BPU占用率相比batch=1有明显提升。
4.3 单核单线程Latency对比

如果同样基于8张图对比,那么batch=1时,模型推理8张图的Latency为1.13ms * 8 = 9.04ms,时间显著长于batch=8的3.05ms。
4.4 双核八线程FPS对比

由于batch=8时,模型1帧会推理8张图,因此FPS实际为790*8=6320,远超batch=1的2703。
4.5 实验结论
对于小模型来说,batch模式能提升BPU占用率,降低算力浪费,同时Latency和FPS都显著优于单batch模型。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)