
在自动驾驶应用中,除了在2D图像中检测目标之外,还必须在3D空间中检测某些目标的类别,如汽车、行人、自行车等。LiDAR通过构建3D空间的点云,可以提供一种精确、高空间维度、高分辨率的数据,可以弥补对3D空间的距离信息。随着深度学习架构的进步逐渐出现了许多基于LiDAR的3D目标检测器。本文在Nuscenes数据集下基于pillar-based的lidar MultiTask算法的介绍和使用说明。
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
0 性能精度指标
数据集 input_shape NDS infer 帧率(J5/双核) Nuscenes [1, 5, 40000, 20][40000, 4] 0.5753 24.51ms 98.72 模型配置:
点云数量 点云范围 Voxel 尺寸 最大点数 最大pillar数 检测类别 分割类别 300000x5(注1) [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0] [0.2, 0.2, 8] 20 40000 10类(注2) 二分类(注2) 注
1:维度为(x,y,z,r,t),即:3维坐标、强度和时间
2:检测任务:["car","truck","construction_vehicle","bus","trailer","barrier","motorcycle","bicycle","pedestrian","traffic_cone"]
分割任务: ["others", "driveable_surface"]
1 模型介绍
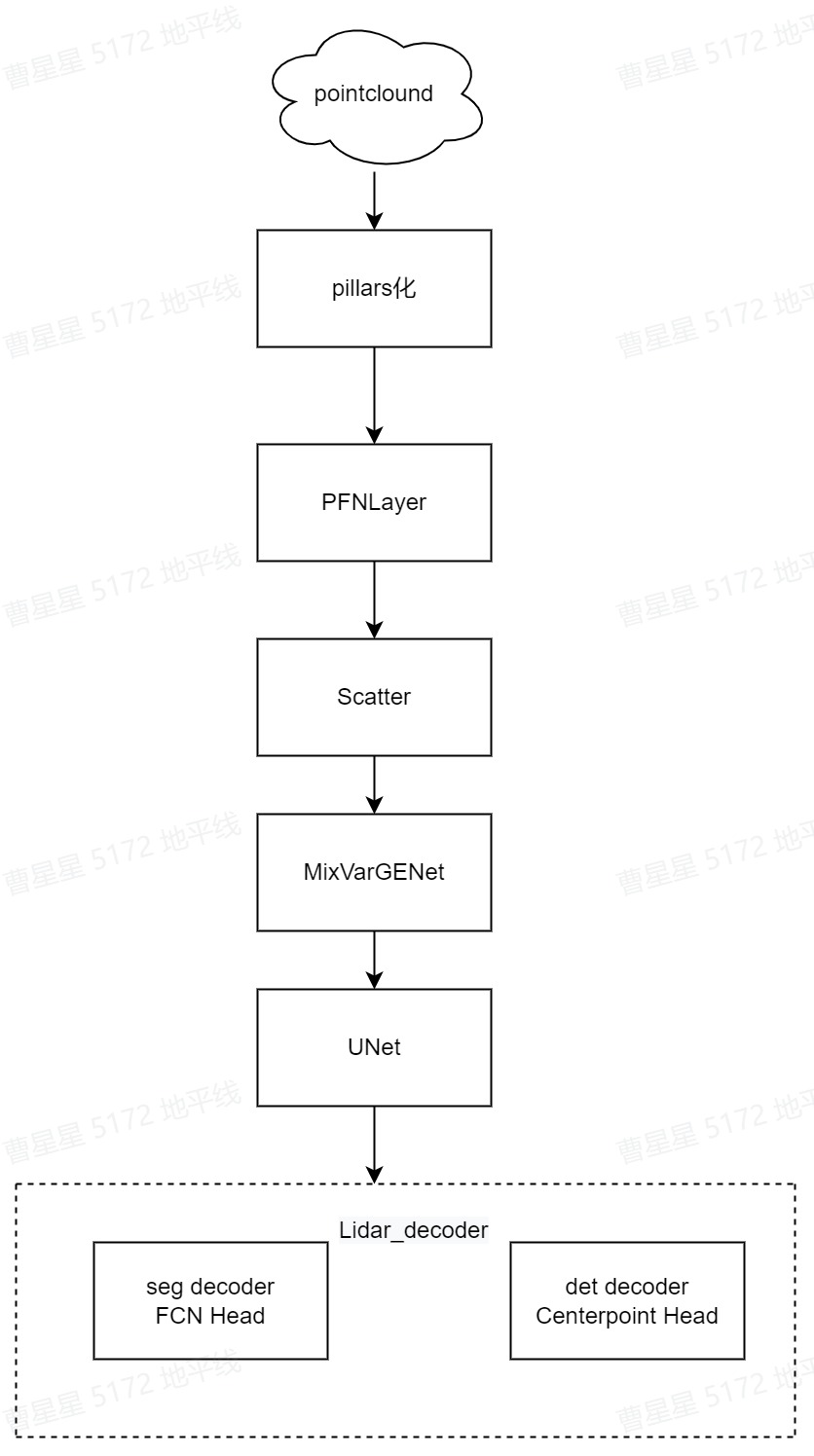
Lidar多任务网络结构分为三个部分: - 体素化(pillar 化):将输入的5维原始点云转换为pillars特征; - PFN层:对pillars特征做特征提取,将C维提升至64维; - Scetter层:完成pillars特征到伪图像化的转换; - 深层特征提取和融合:将PFN层后的特征经过MixVarGENet+UNET提取高层语义特征; - 检测和分割任务:做多类别的3D目标检测(DepthwiseSeparableCenterPointHead)和二分类的分割任务(DepthwiseSeparableFCNHead),区分可行驶的区域。
1.1 模型改动点
在网络结构上,相比于官方实现,我们做了如下更改:
前处理 point encoder部分,仅使用5维点云特征(x,y,z,r,t),并做归一化处理, 浮点相比官方9维轻微掉点,对量化训练更友好;
PillarFeatutreNet 中的 PFNLayer 使用 Conv2d + BatchNorm2d + ReLU,替换原有的 Linear + BatchNorm1d + ReLU,使该结构可在BPU上高效支持,性能提升;
PillarFeatutreNet 中的 PFNLayer 使用 MaxPool2d,替换原有的 torch.max,便于性能的提升;
Scatter过程使用horizon_plugin_pytorch实现的point_pillars_scatter,便于模型推理优化,逻辑与公版相同;
为遵循硬件对齐规则,减少padding造成无效的算力浪费,对于耗时严重的OP,采用H W维度转换的方式,将大数据放到W维度,比如1x5x40000x20 转换为 1x5x20x40000;
unet 结构使用SeparableGroupConv2d代替conv2d,增加了多尺度的特征提取与融合,便于精度和性能的提升。
Head部分,使用SeparableConvModule2d替换ConvModule2d,便于性能的提升。
1.2 源码说明
Config文件
configs/lidar_multi_task/centerpoint_mixvargnet_multitask_nuscenes.py 为 lidarMultiTask 的配置文件,定义了模型结构、数据集加载,和整套训练流程,所需参数的说明在算子定义中会给出。配置文件主要内容包括:
注: 如果需要复现精度,config中的训练策略最好不要修改。否则可能会有意外的训练情况出现。
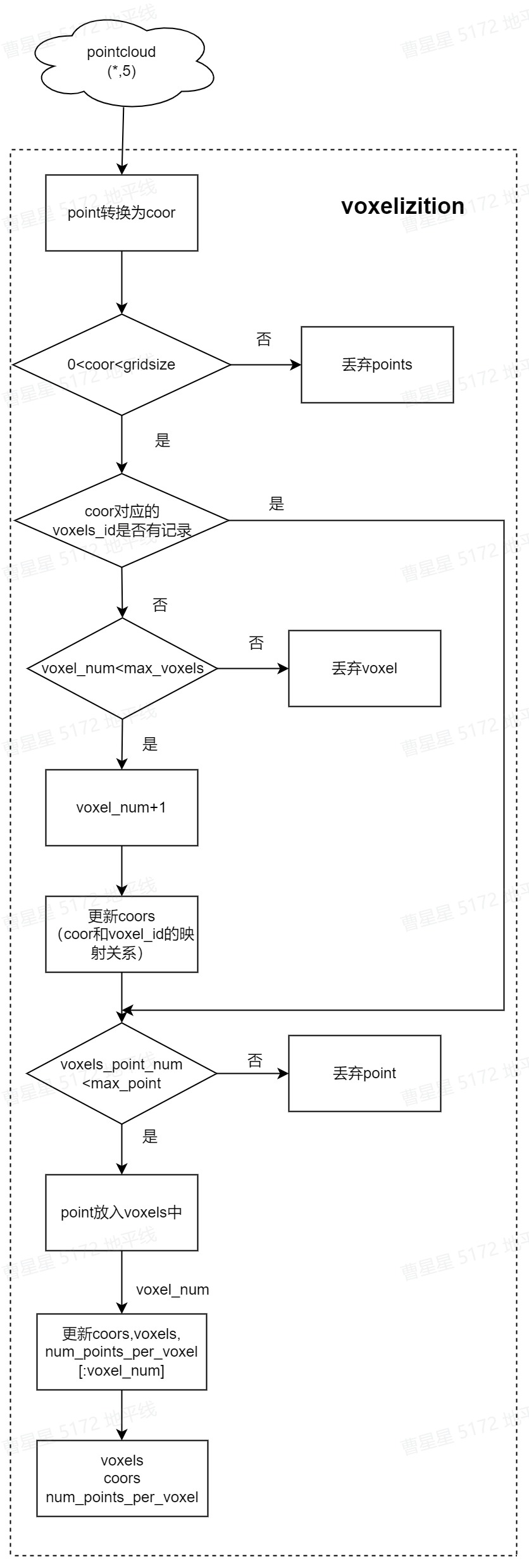
Voxelization
该接口是在horizon-plugin中实现,preprocess实现voxelization过程,主要是将点云数据根据预设size划分为一个个的网格。凡是落入到一个网格的点云数据被视为其处在一个 voxel里,或者理解为它们构成了一个 voxel。voxelization的实现流程见下图:
对pillar特征归一化,可通过指定维度和范围值做归一化,有助于量化训练:
PillarFeatureNet
为了应用 2D 卷积架构,最终要实现将点云(P,N,5)转换为伪图像,整体步骤如下图:
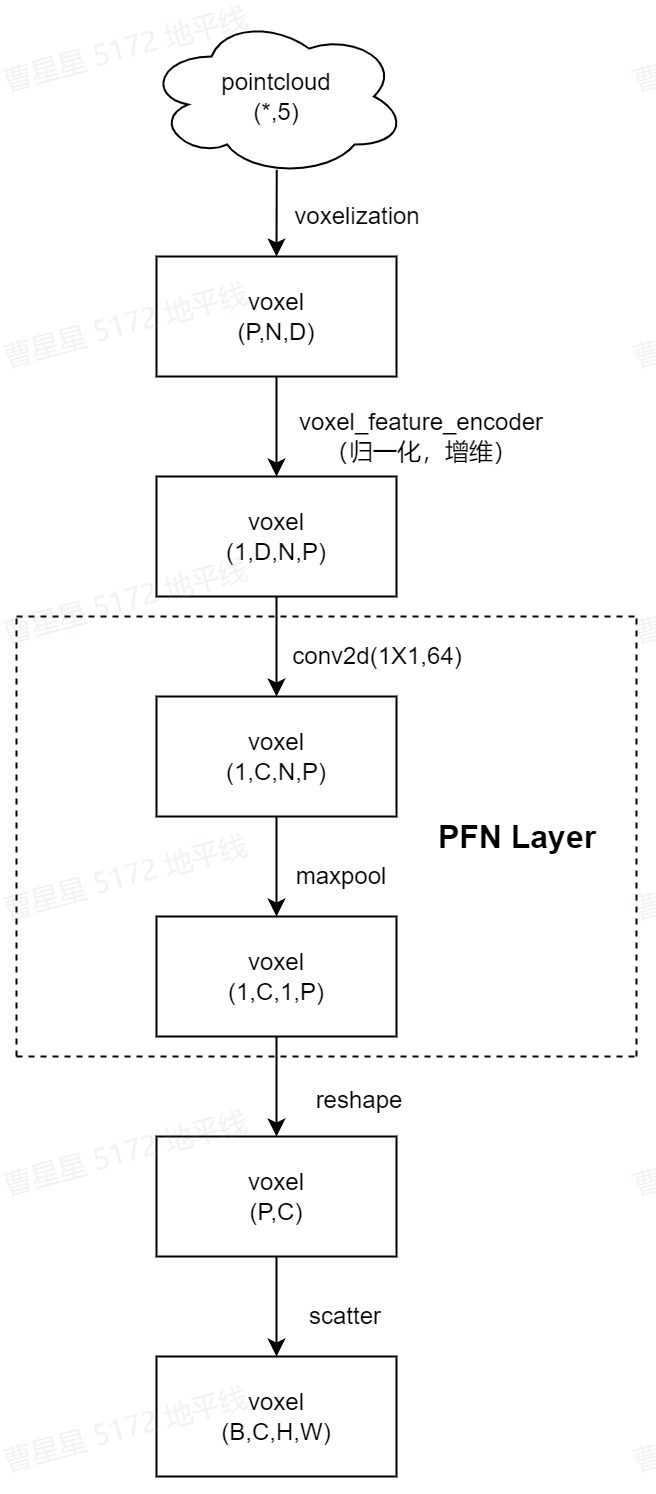
该算法主要实现将点云数据的shape (1,D,N,P)经过pfn_layers后变换为(1,C,1,P)该算法主要实现将点云数据的shape (1,D,N,P)经过pfn_layers后变换为(1,C,1,P)-->(1,1,P,C)
PointPillarScatter
该层实现伪图像转换的最后一个步骤。为了获得伪图片特征,将 P 转化为(W, H),由于预先设定pillar最大值以及去除了一些空pillar,因此P
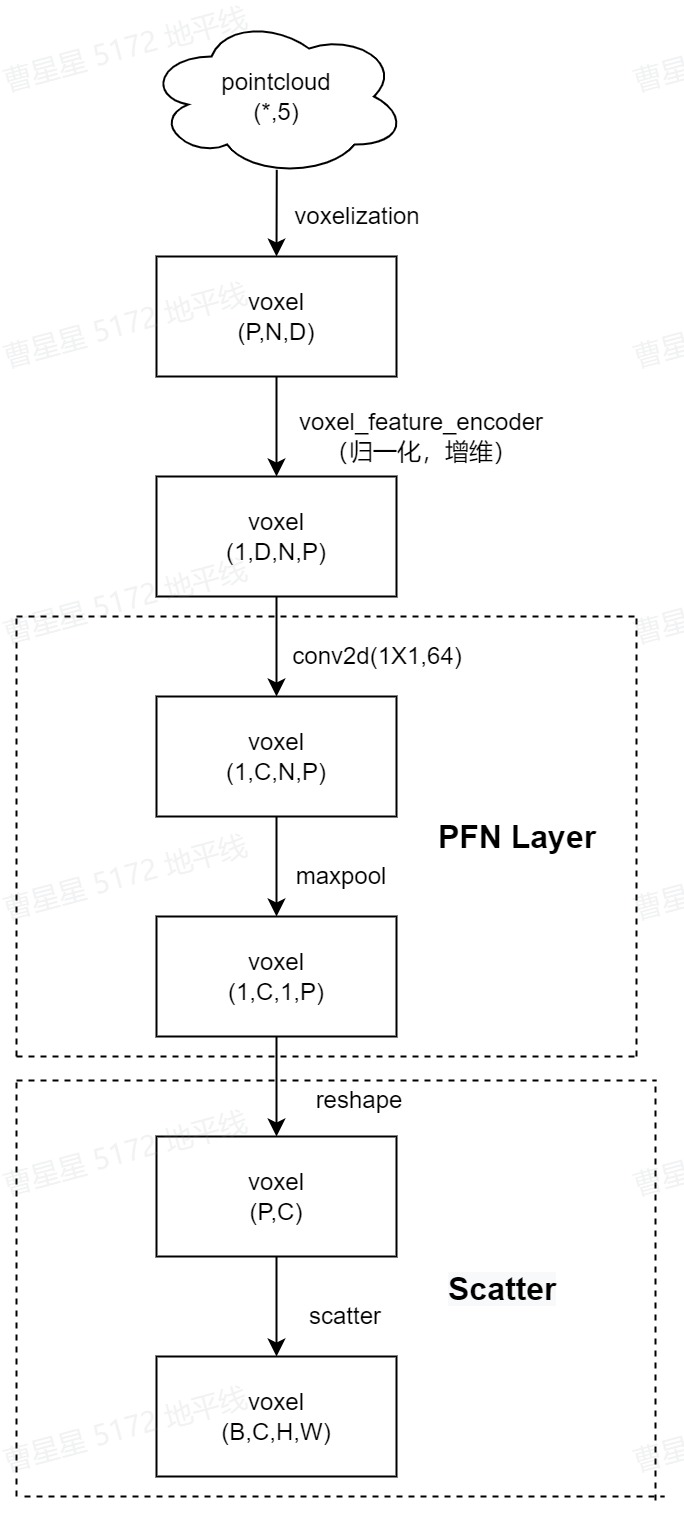
Scatter实现代码在horizon_plugin_pytorch下实现,见代码:
Backbone
Lidar多任务模型的backbone采用地平线基于J5硬件特性自研的MixVarGENet,该结构的基本单元为MixVarGEBlock。如下为MixVarGEBlock的结构图:
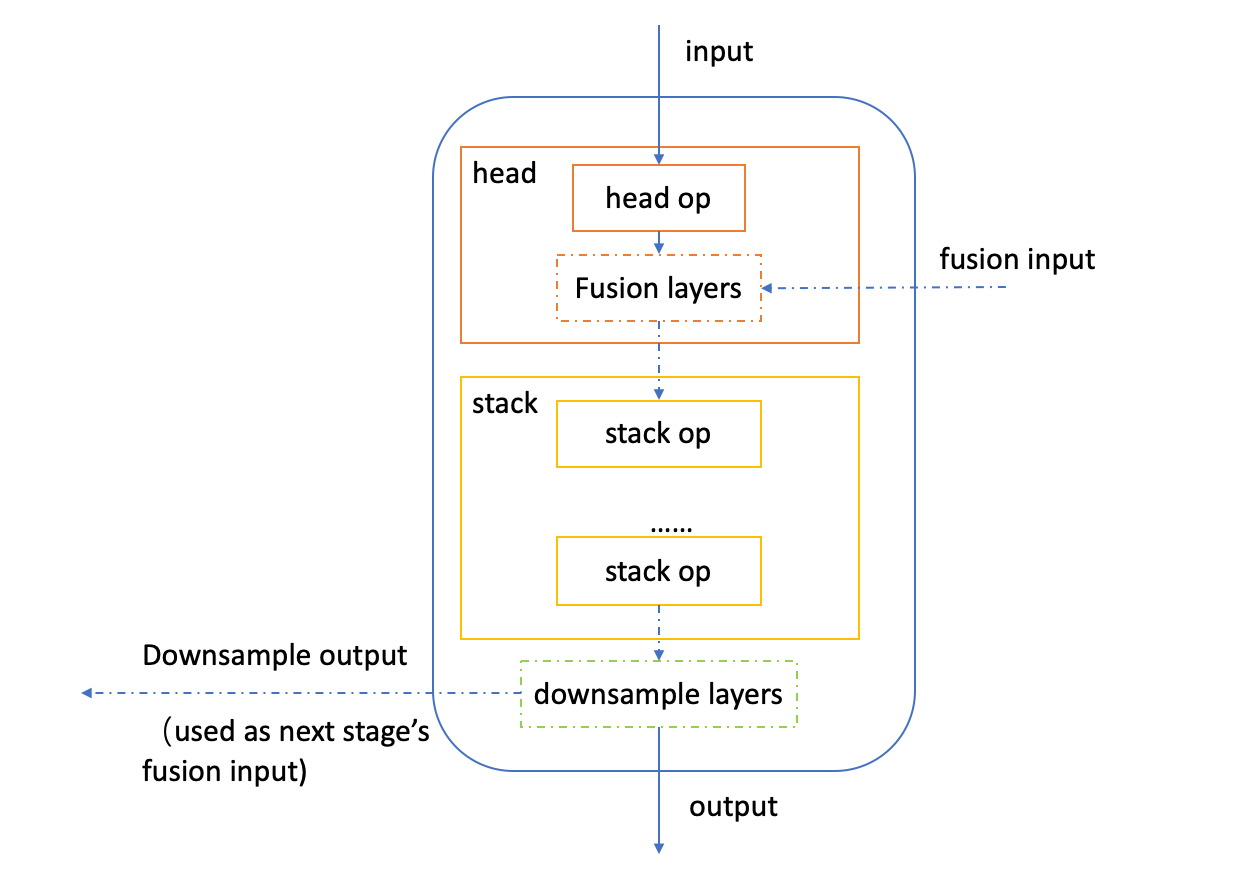
Neck
特征融合部分采用了Unet结构,该结构为编码器-解码器结构,如下图所示:
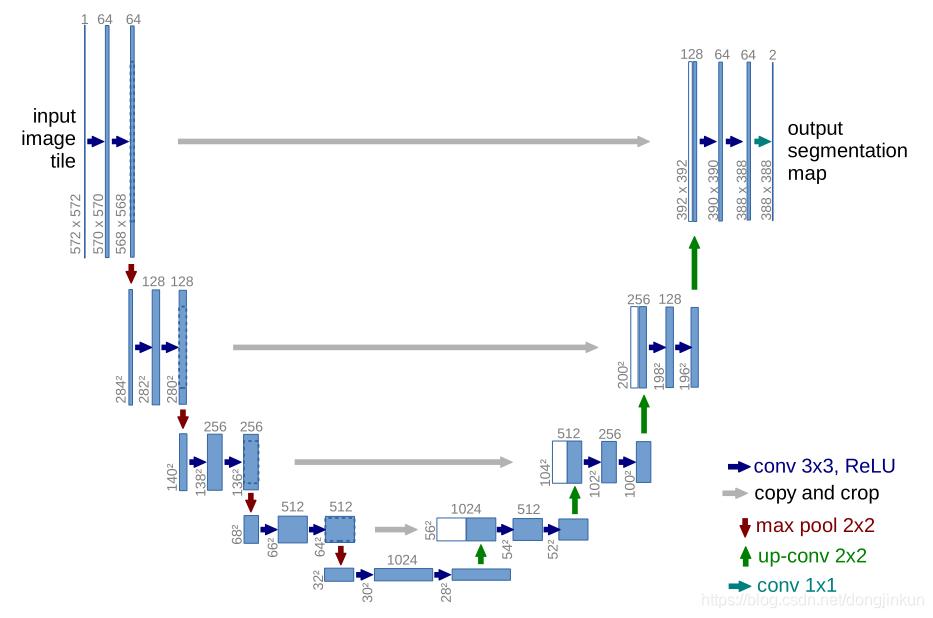
上图为公版模型结构,地平线实现版本与公版逻辑上相同,实现上有差异,详见代码实现
Head
seg_head
det_head
在nuscenes数据集中,目标的类别一共被分为了6个大类,网络给每一个类都分配了一个head,装在headlist中,而每个head内部都为预测的参数。
forward时,经过共享的SeparableConv后,将feature再分别传入task_heads做task_pred。
Loss
seg_loss
det_loss
对应代码:hat/models/task_modules/centerpoint/loss.py
2 浮点模型训练
2.1 Before Start
2.1.1 环境部署
release_models获取路径见:scripts/configs/lidar_multi_task//README.md
拉取docker环境
如需本地离线安装HAT,我们提供了训练环境的whl包,路径在ddk/package/host/ai_toolchain
2.1.2 数据下载
将下载的文件进行解压,lidar_seg/v1.0-trainval下的category.json 与 lidarseg.json 分别复制到nuscenes/v1.0-trainval 文件夹下,解压后的目录如下所示:
2.1.3 数据打包
为了提升训练的速度,需要对数据信息文件做了一个打包,将其转换成lmdb格式的数据集。其中, lidarMultiTask 模型只使用了 nuscenes 数据集的点云部分文件。只需要运行下面的脚本,就可以成功实现格式转换:
--src-data-dir为解压后的nuscenes数据集目录;
--target-data为打包后数据集的存储目录;
--version 选项为["v1.0-trainval", "v1.0-test", "v1.0-mini"],如果进行全量训练和验证设置为v1.0-trainval,如果仅想了解模型的训练和验证过程,则可以使用v1.0-mini数据集; v1.0-test数据集仅为测试场景,未提供注释
2.1.4 meta文件夹构建
2.1.5 数据生成
为了训练 nuscenes 点云数据,还需为 nuscenes 数据集生成每个单独的训练目标的点云数据,以及需要为这部分数据生成 .pkl 格式的包含数据信息的文件。通过运行下面的命令来创建:
执行上述命令后,生成的文件目录如下:
2.1.6 config配置
在进行模型训练和验证之前,需要对configs文件中的部分参数进行配置,一般情况下,我们需要配置以下参数:
device_ids、batch_size_per_gpu:根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
ckpt_dir:浮点、calib、量化训练的权重路径配置,权重下载链接在config文件夹下的README中;
data_rootdir:打包的lmdb数据集路径配置;
meta_rootdir :meta文件夹的路径配置;
gt_data_root:nuscenes_gt_database的上一层路径
infer_cfg:input_points为点云输入,做结果可视化时需要配置
2.2 浮点模型训练
2.3 浮点模型精度验证
验证完成后,会在终端输出float模型在验证集上的检测精度。
3 模型量化和编译
3.1 Calibration
3.2 量化模型训练
通过运行下面的脚本就可以开启模型的qat训练:
3.3 量化模型精度验证
量化模型的精度验证,只需要运行以下命令:
qat模型的精度验证对象为插入伪量化节点后的模型(float32);quantized模型的精度验证对象为定点模型(int8),验证的精度是最终的int8模型的真正精度,这两个精度应该是十分接近的。
3.4 仿真上板精度验证
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
3.5 量化模型编译
opt为优化等级,取值范围为0~3,数字越大优化等级越高,运行时间越长;
compile_perf脚本将生成.html文件和.hbm文件(compile文件目录下),.html文件为BPU上的运行性能,.hbm文件为上板实测文件。
4 其他工具
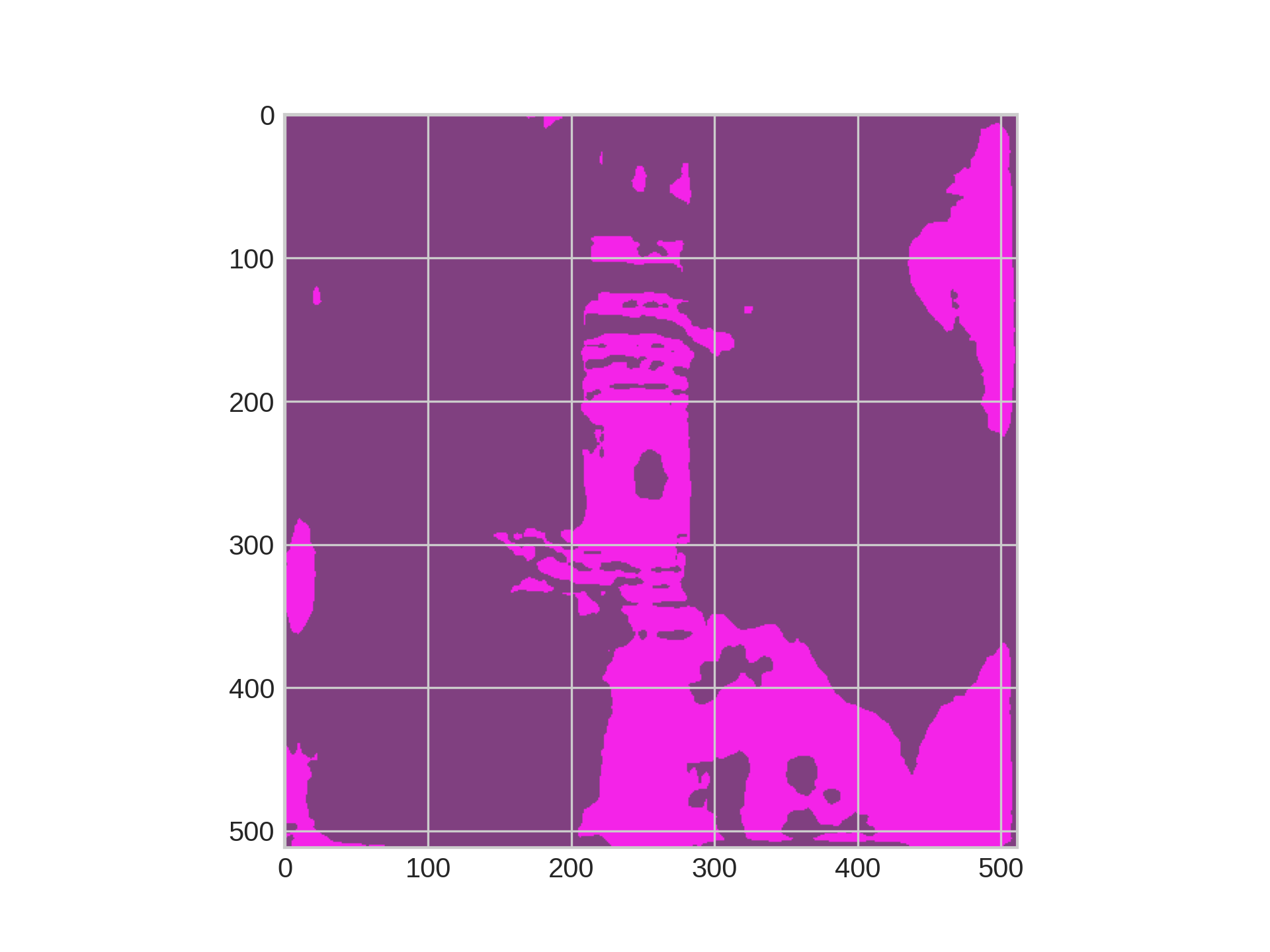
4.1 结果可视化
如果你希望可以看到训练出来的模型对于雷达点云的检测效果,我们的tools文件夹下面同样提供了点云预测及可视化的脚本,你只需要运行以下脚本即可:
注:需在config文件中配置infer_cfg字段。
可视化示例:

5 板端部署
5.1 上板性能实测
雷达点云模型板端验证请务必使用真实点云输入!
5.2 AI Benchmark示例
可在板端使用以下命令执行做模型评测:

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)