
1. 背景
以前从0开始学习过地平线的PTQ(后量化)方案,写了一些基础知识文章,后来发现地平线的用户手册关于PTQ方面其实挺完善的,东西很多很全,就没再想着写。
最近想着学QAT(量化感知训练)玩玩,大体看了一下地平线的用户手册,不说精度调优、性能调优之类比较复杂的,光一个QAT上手,就感觉对我这种小白不是很友好,比如我这种小白,捣鼓了好久,感觉在用户手册中很多基础概念都没写,不同模块之间的关联性也没有详细地介绍,直到我“精读”用户手册 4.2量化感知训练(QAT) ,发现了这么一句话,

那针对只使用过Pytorch在服务器上训练过一些分类、检测模型,没接触过QAT的小白,又不想读PyTorch官方文档,只想简单入个门,怎么办嘞?欢迎看看这篇文章,提供实操代码和运行步骤,如果文章对你有点作用的话,麻烦收藏+点个赞再走~
该文章参考自J5 OE1.1.52中对应的示例以及用户手册,为啥不是用的XJ3 OE,请看第5节吐槽部分
2. 基础理论知识
量化可以分为PTQ与QAT,
PTQ:Post-training Quantization,训练后量化,指浮点模型训练完成后,基于一些校准数据,直接通过工具自动进行模型量化的过程,相比QAT,PTQ更简单一些,这篇文章不介绍PTQ。
- QAT:Quantization aware training,量化感知训练,指浮点模型训练完成后,在模型中插入伪量化节点再进行量化训练的过程,大体过程如下图所示,相比PTQ,QAT精度更有保障一些,这篇文章介绍QAT。
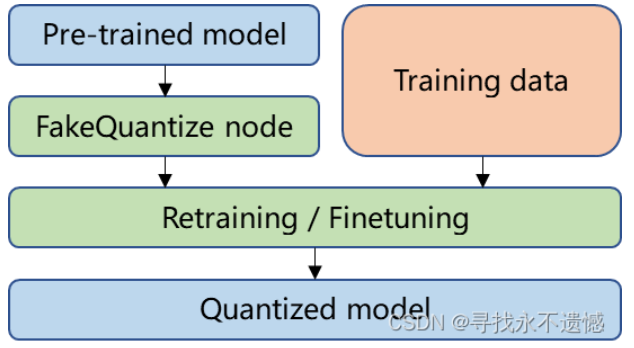
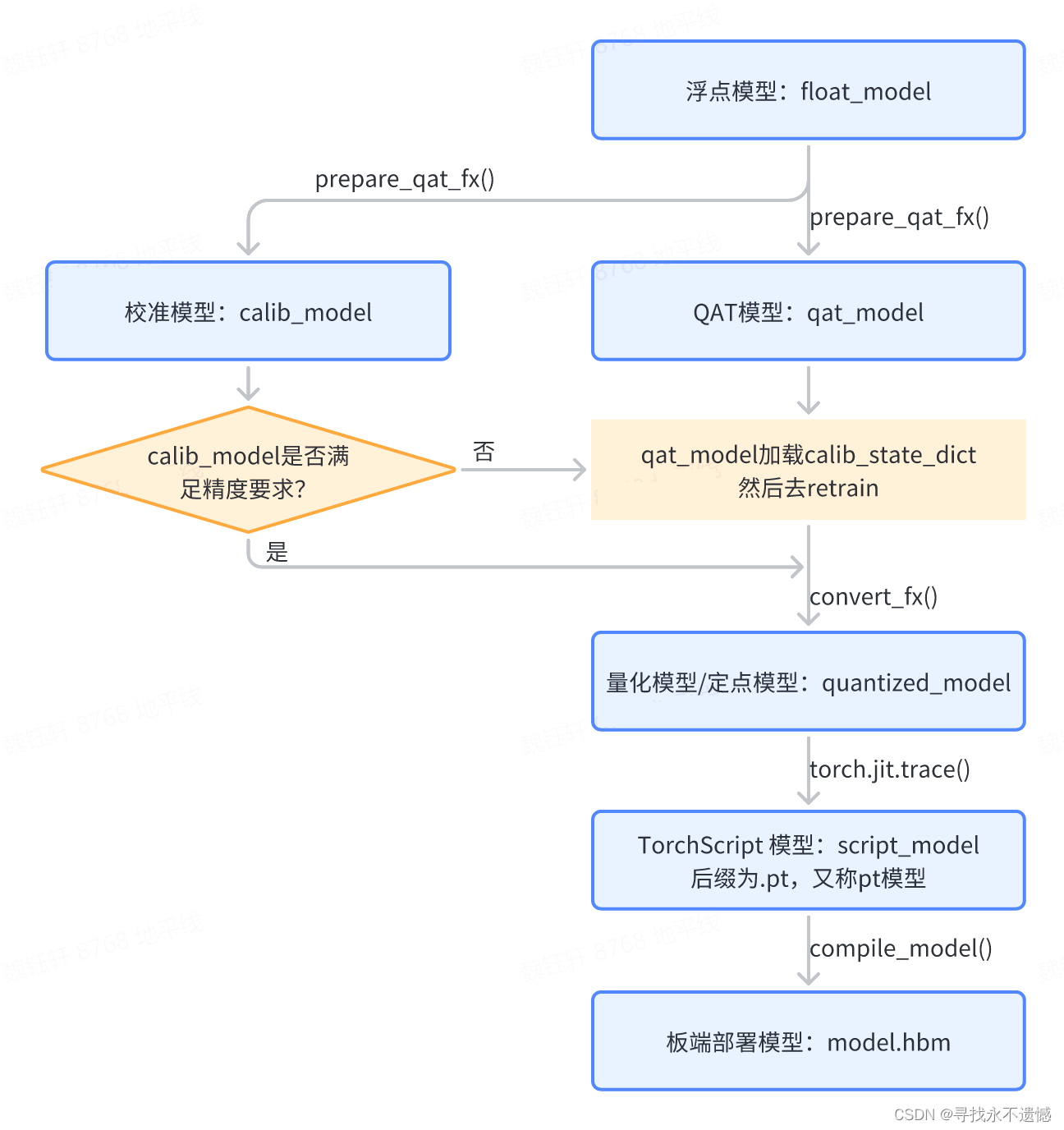
在每个阶段,还有一些需要注意的地方,比如...
- float_model和我直接用pytorch搭建的有什么不同吗?
这里float_model浮点模型,其实就是在pytorch搭建的常规网络输入处插入QuantStub节点、输出处插入DeQuantstub节点,在PyTorch中,QuantStub/DequantStub 是一种用于量化的辅助工具,用于标记量化过程中需要量化/反量化的层或操作,前期浮点训练时可以当它不存在,在量化时会自动被替换为对应的量化操作。从普遍意义上说,每个分支都要对应插入QuantStub,别再追问为什么了,问就是甲鱼的臀部——“规定”。
- fx是什么?
pytorch中量化方式有两种,分别是Eager Mode Quantization和FX Graph Mode Quantization,它俩各有优劣。对于初学者,Eager模式需要手工修改网络代码,并对很多节点进行替换,比较复杂,而 FX模式不需要这种操作,使用起来比较简单,因此,推荐使用fx模式。
关于fx与eager两种模式体现在地平线量化训练以及部署层面的差异,大家感兴趣的话,可参考地平线开发者社区专业介绍:QAT - 异构与非异构方案使用简介。
地平线同时支持fx和eager两种模式,fx模式体现在地平线封装的各种函数中,例如prepare_qat_fx(),就是在函数最后有fx字样。 - calib是什么?
calib是校准calibration的缩写,主要作用是确定量化参数,我们知道,合理的初始量化参数能够显著提升模型精度并加快模型的收敛速度。calibration 就是在浮点模型中插入 Observer,使用少量训练数据,在模型 forward 过程中统计各处的数据分布,以确定合理的量化参数的过程。虽然不做 Calibration 也可以进行量化训练,但一般来说,它对量化训练有益无害,所以推荐大家将此步骤作为必选项。 - qat_model和quantized_model还不是一个意思?
不一样的。
qat_model是一种插入了伪量化节点的伪量化模型,简单理解为:它是为了量化训练而存在的模型,里面还“流淌”着浮点的参数,伪量化节点在模拟量化而已。
quantized_model:模型中的浮点参数转换为定点参数,且把浮点算子转换成定点算子,这种转换后的模型称之为quantized_model /定点模型 / 量化模型。 - script_model又是哪儿冒出来的?
scipt_model是一种可以序列化的Torch脚本(TorchScript),方便在不需要Python解释器的环境中使用模型,例如C++应用程序、移动端应用等。scipt_model的获取通过torch.jit.trace实现。torch.jit.trace是PyTorch中的一个静态图转换工具,用于将一个PyTorch模型转换成一个可以序列化的Torch脚本(TorchScript)。其工作流程是,首先使用输入张量对模型进行前向计算,然后将计算图转换为Torch脚本。在这个过程中,PyTorch会执行所有与输入相关的计算,从而记录下计算图的结构和参数的值。
以下是torch.jit.trace方法的基本语法:script_model = torch.jit.trace(model, example_inputs, optimize=True),其中,model是待转换的PyTorch模型,并不一定需要是quantized_model,普通的也可以,这里是QAT场景,因此是quantized_model。example_inputs是一个输入张量或元组,用于为模型执行前向计算,并记录计算图的结构和参数的值。optimize是一个布尔值,用于指定是否对转换后的计算图进行优化。默认情况下,optimize为True,将对计算图进行常量折叠、运算融合等优化。 - 板端部署hbm模型我知道,就是可以在板子上推理的模型,类似于PTQ里的bin模型对吧?
非常对。
大黑:是的。
3. 文件准备与程序运行
一共就需要3个文件
为了方便大家获取,以上文件均存放在网盘链接中:
代码运行,建议在地平线提供的docker里运行,当然,如果大家自己会配置本地环境的话,也可以不用docker,我两种都试了,都是ok的。
运行过程
特别是在stage=compile,产出物有点多,在这儿具体介绍一下
模型名称 | 模型解读 |
|---|---|
int_model.pt | torch.jit.save(script_model, "int_model.pt")生成的,指 torchscript 模型 |
model.pt | compile_model函数产出的中间产物,和int_model.pt是一回事,指 torchscript 模型 |
model.hbir | compile_model函数产出的中间产物,用于出现问题时提供给地平线技术支持分析,我们不需要关注 |
model.hbm | compile_model函数产出的最终产物,即板端可部署模型 |
xxx.html | perf_model函数的产物,一个html文件,里面提供一些编译器层面分析出的性能信息 |
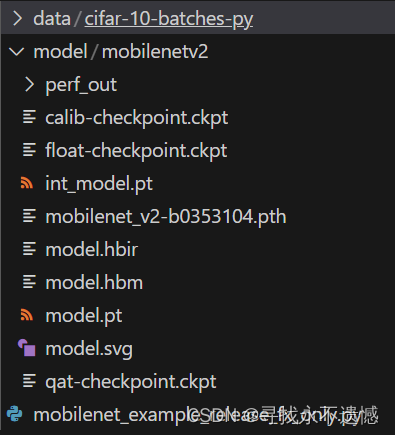
跑起来很简单,下面再和大家一起看看代码层面的情况。
4. 代码详解
4.1 导入必要依赖
之所以写这一节,主要是希望大家可以从注释中,简单了解各个函数的作用,像torch、os这种导入就省略没写,全部的依赖可以看提供的代码。其中,horizon_plugin_pytorch是地平线基于 PyTorch 开发的 的量化训练工具,可以理解成numpy这种库,里面有很多用于量化训练的的依赖,我们直接用就好了。
4.2 主函数
看了第2节理论知识部分,主函数部分的代码就是严格执行那几个阶段stage(详见第2节),很easy,关于内部细节,在后面几个小节挨个介绍。
parser = argparse.ArgumentParser(description="Run mobilenet example.")
parser.add_argument(
"--stage",
type=str,
choices=("float", "calib", "qat", "int_infer", "compile"),
help=(
"Pipeline stage, must be executed in following order: "
"float -> calib(optional) -> qat(optional) -> int_infer -> compile"
),
)
parser.add_argument(
"--data_path",
type=str,
default="data",
help="Path to the cifar-10 dataset",
)
parser.add_argument(
"--model_path",
type=str,
default="model/mobilenetv2",
help="Where to save the model and other results",
)
parser.add_argument(
"--train_batch_size",
type=int,
default=256,
help="Batch size for training",
)
parser.add_argument(
"--eval_batch_size",
type=int,
default=256,
help="Batch size for evaluation",
)
parser.add_argument(
"--epoch_num",
type=int,
default=None,
help=(
"Rewrite the default training epoch number, pass 0 to skip "
"training and only do evaluation (in stage 'float' or 'qat')"
),
)
parser.add_argument(
"--device_id",
type=int,
default=2,
help="Specify which device to use, pass a negative value to use cpu",
)
parser.add_argument(
"--quant_method",
type=str,
choices=["fx"],
default="fx",
help=(
"Specify fx mode quantization."
" Please do not change quant method "
"between different stages, or the model may fail to load"
),
)
parser.add_argument(
"--opt",
type=str,
choices=["0", "1", "2", "3", "ddr", "fast", "balance"],
default=0,
help="Specity optimization level for compilation",
)
args = parser.parse_args()
print(args)
4.3 构建fx模式所需要的float_model
从torchvision.models中继承MobileNetV2,微调一下,以支持量化相关操作。模型改造必要的操作有:
在模型所有输入分支前插入 QuantStub
在模型所有输出分支后插入 DequantStub
这部分具体实现过程解读可见代码注释。
关于如何加载预训练权重部分的代码在函数load_pretrain里,详细内容可以看Python文件,这里不再呈现。
4.4 不同阶段模型的获取
在代码运行时,有个输入参数stage必须配置,表示拿到哪个model去整后面的事,当stage参数传入("float", "calib", "qat", "int_infer")中某一个时,会通过如下函数去获取,具体实现过程解读可见代码注释。
4.5 定义常规模型训练与验证的函数
具体实现,看py代码就行,很常规。
) -> Tuple[data.DataLoader, data.DataLoader]:
"""Computes and stores the average and current value"""
"""Computes the accuracy over the k top predictions for the specified values of k"""
optimizer: torch.optim.Optimizer,
scheduler: Optional[torch.optim.lr_scheduler._LRScheduler],
data_loader: data.DataLoader,
device: torch.device,
) -> None:
4.6 float与qat训练代码解读——float_model/qat_model
针对float_model和qat_model的参数训练,代码解读如下,
def train(data_path: str,
model_path: str,
train_batch_size: int,
eval_batch_size: int,
epoch_num: int,
device: torch.device,
optim_config: Callable,
stage: str,
march=March.BAYES,
quant_method="fx",
):
# --------------------------------------------#
# qat模型训练和普通浮点模型训练的不同之处!
# --------------------------------------------#
model = get_model(stage, model_path, device, march, quant_method)
4.7 模型校准部分的代码解读——calib_model
float模型训练完成后,需要进行参数校准,得到calib_model,如果calib_model精度满足要求,qat训练就不需要了,即使calib_model精度不行,calib_model_state_dict(校准后的权重)对qat训练收敛也非常有帮助。
4.8 定点模型评测精度 代码解读——quantized_model
定点模型/quantized模型/量化模型 eval推理一下看看精度
4.9 编译生成上板模型——script_model/model.hbm
编译生成上板模型model.hbm,同时针对script_model预估模型性能,并进行可视化
5. 建议or吐槽
提供用户手册、提供上手示例,很棒!只是说好的快速上手示例,能麻烦大佬们写的基础一点嘛~
- 一定要善于看源码,里面有函数的作用和使用方法的介绍,很有用!可惜我用vscode在docker里总是无法跳转,馋哭了,其实可以有个笨方法,如下图
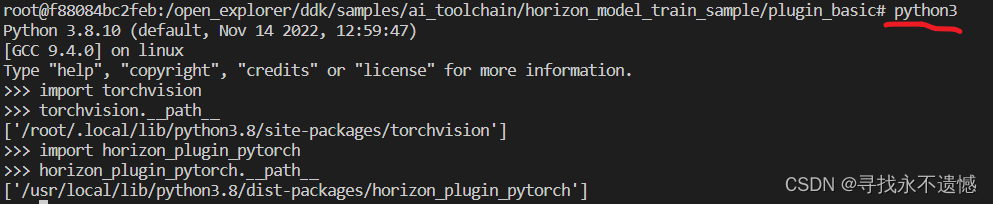

初次上手的例子,建议和我们说一个最标准的流程就好了,像float_model到底选用origin_float_model更好还是FxQATReadyModel更好?calib这一步到底要不要?qat_model到底加载float_state_dict更合适还是calib_state_dict更合适?这些问题在我初次看代码时产生了一些疑惑~
X3的OE包里,能否像J5 OE包里一样提供plugin_basic的例子?要不是J5 OE包也对外释放了,都学不到这种好东西,偏心了啊!
J5 OE包里提供的plugin_basic例子,能否把fx和eager拆开成两个py文件?放到一起,刚开始学的时候总搞混...(当然,也可能是我水平问题)
- 用户手册中把快速上手部分全部可执行代码放出来,感觉还挺好的,适合我这种小白,当然,在OE包里还有一份全面的代码,感觉在手册里告诉我它在OE包里的位置,这样也可以接受。其实我想说:手册中更建议多放点需要跟着操作的步骤,或者理论介绍,或者代码多点注释,不是很理解为啥把全部log日志都贴出来了(4.2.3 快速上手)!输出日志部分,放点开头、结尾、关键部分说明意思就行,想看全部的话,我自己会去跑跑试一下的,难道手册有最低字数限制?
想让尾部conv以高精度int32输出,竟然配置的是default_qat_out_8bit_fake_quant_qconfig,大大问号脸?明明是out_8bit啊!后来咨询技术支持,原来这里的8bit是weight的量化方式为8bit。感觉这个命名有点容易造成误解,不知道能否修改为qat_out_int32_weight_8bit_fake_quant_qconfig?(反正都已经很长了...,哦在最新发的版本中已修改为default_qat_8bit_weight_32bit_act_fake_quant_qconfig,这里的act应该是activation的缩写,表示节点输出)
OE包中看着提供了很多例子,但例子之间又有很多共用的代码,造成非常多的嵌套,我就参考其中一个,还得下载整个OE包,不知道能否拆开例子,放到github或者gitee上,想参考哪个我就下载哪个多好!
能否给点从浮点训练 到 量化转换编译 到 上板部署(python/c++) 到 可视化 的全流程示例仓库,本来生态就不如英伟达,支持国产总得让我们用起来很顺溜才好吧!建议搞点全流程例子给我们!(理直气不壮)
都看到这儿了,如果对您有帮助的话,麻烦给点个赞呀~



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)