
2.3 阶段3 模型上板:Python推理部署与校验
但代码跨平台很容易出现问题,因此安全起见,也要规范一下校验流程来定位问题,因此,构建流程部分没有得到正确结果的话,请参考本部分的校验流程。
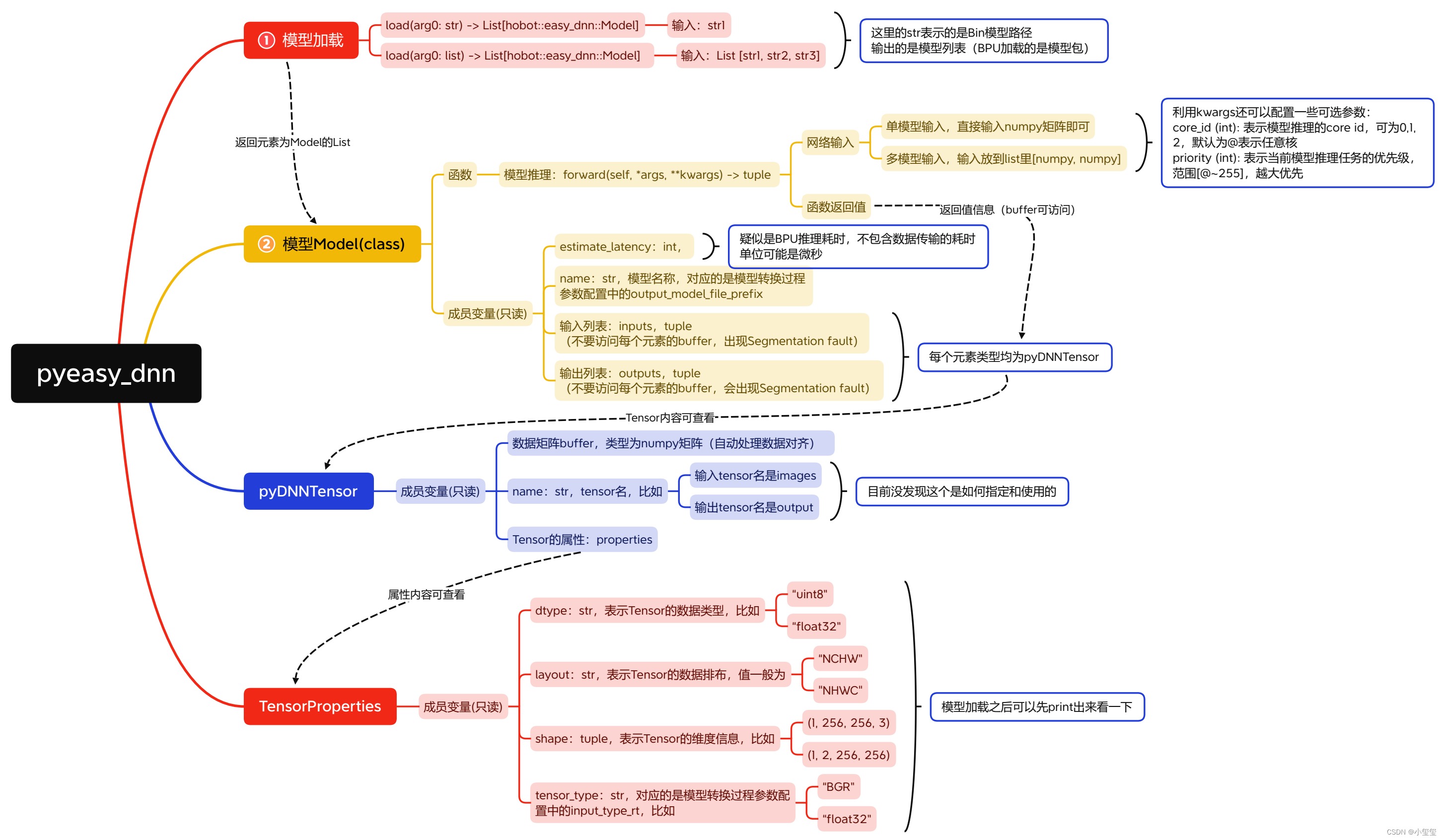
基于Python的部署主要调用的是pyeasy_dnn,这个包里面的一些函数/类/数据类型的用法我会在后面详细解释。
2.3.1 构建流程
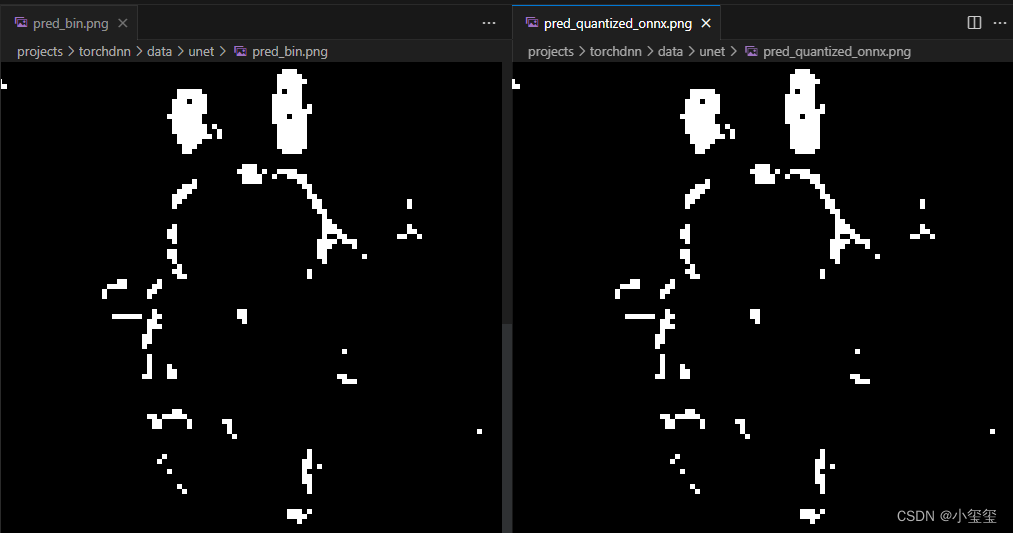
2.3.2 校验流程
PS:如果校验都通过,那就认真检查下推理的前后处理吧,肯定是某个细节写错了→_→。
① BIN量化模型上板校验
2.3.3 pyeasy_dnn内容分析
2.4 阶段4 模型上板:C++推理部署与校验
此外,考虑到部署的不安全性,我自己在C接口的基础上,补充了一个C++的API,以减少学习成本,提高部署安全性,这个会在下一章节(wdr::BPU部署)介绍。
2.4.1 编译配置
大部分Linux的代码都通过CMake进行编译,C++推理依赖项整理如下:
- 头文件:BPU部署相关的头文件存放在/usr/include/dnn/,配置时候不需要利用include_directories指定头文件目录,大部分的BPU部署直接在代码中添加下面两行代码即可#include <dnn/hb_dnn.h>和#include <dnn/hb_sys.h>。若有函数找不到,就去dnn根目录下查找对应的函数头文件。
- 库文件:BPU相关的库文件存放在/usr/lib/hbbpu/中,因此需要在CMakeList.txt中补充库目录link_directories(/usr/lib/hbbpu/),编译最终可执行文件时,在target_link_libraries中补充相关库-ldnn -lcnn_intf -lhbrt_bernoulli_aarch64。(PS:除了这个还有libhlog.so,这个就是打印日志用的,我觉得可以用glog替代,就不使用这个了。)
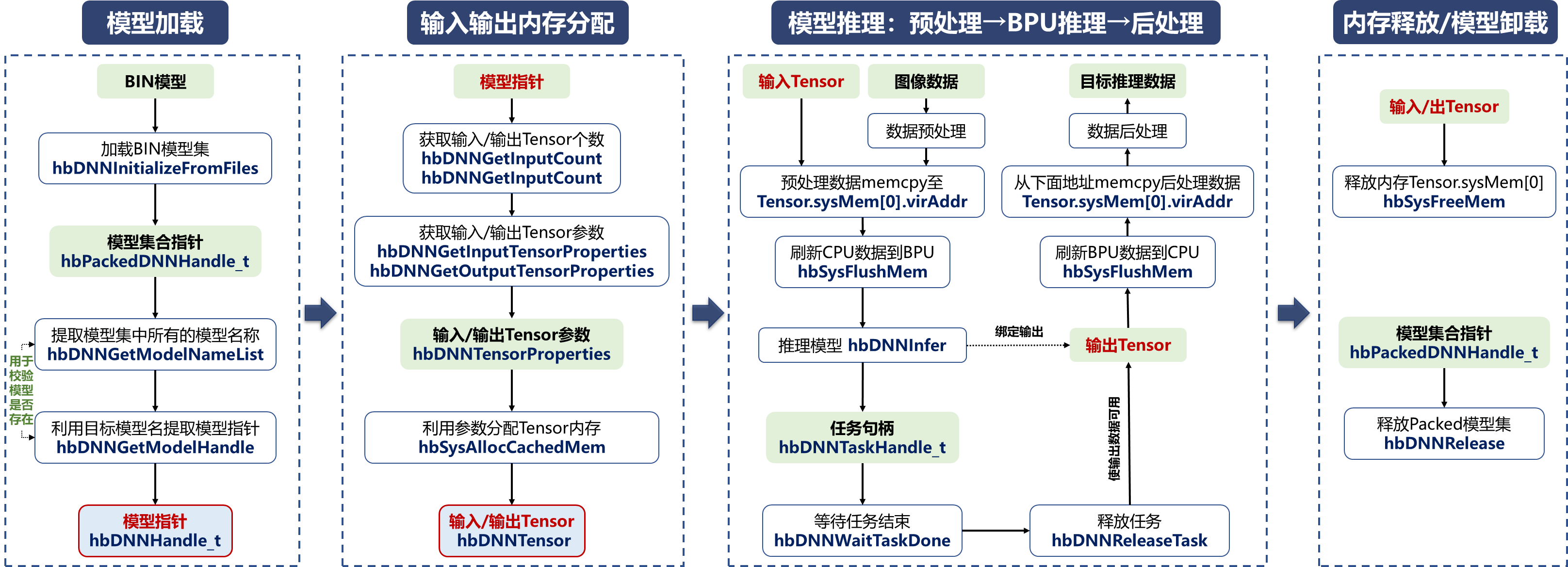
2.4.2 构建流程
下面对代码中的一些关键内容进行讲解。
如果用了这种方式构建矩阵,有一些地方需要注意下:
- datain.rows和datain.cols的值均为-1,维度个数可通过datain.size.dims()获取,其第k维大小可通过datain.size[k]获取。
- datain.at<float>(i,j)这种访问元素的形式失效。只能利用数据指针(float*)datain.data来访问元素。
在给出代码细节之前,我先说几个注意点:
流程图中模型推理这一过程,绑定输出表示输出的Tensor作为参数输入到hbDNNInfer中。
- 在推理代码中,BPU推理API操作的是硬件,这里应该对每个BPU函数套用一个HB_CHECK_SUCCESS来检查是否成功执行,比如HB_CHECK_SUCCESS(hbDNNInitializeFromFiles(&pPackedNets, cpaths, pathnum), "hbDNNInitializeFromFiles failed");,为了方便理解流程,下面的代码省去了HB_CHECK_SUCCESS。下面这个代码片给出的定义。
详细BPU的C++推理代码如下所示,执行之后会保存推理结果,推理结果跟Python版本推理结果是一样的,这里就不再展示了。
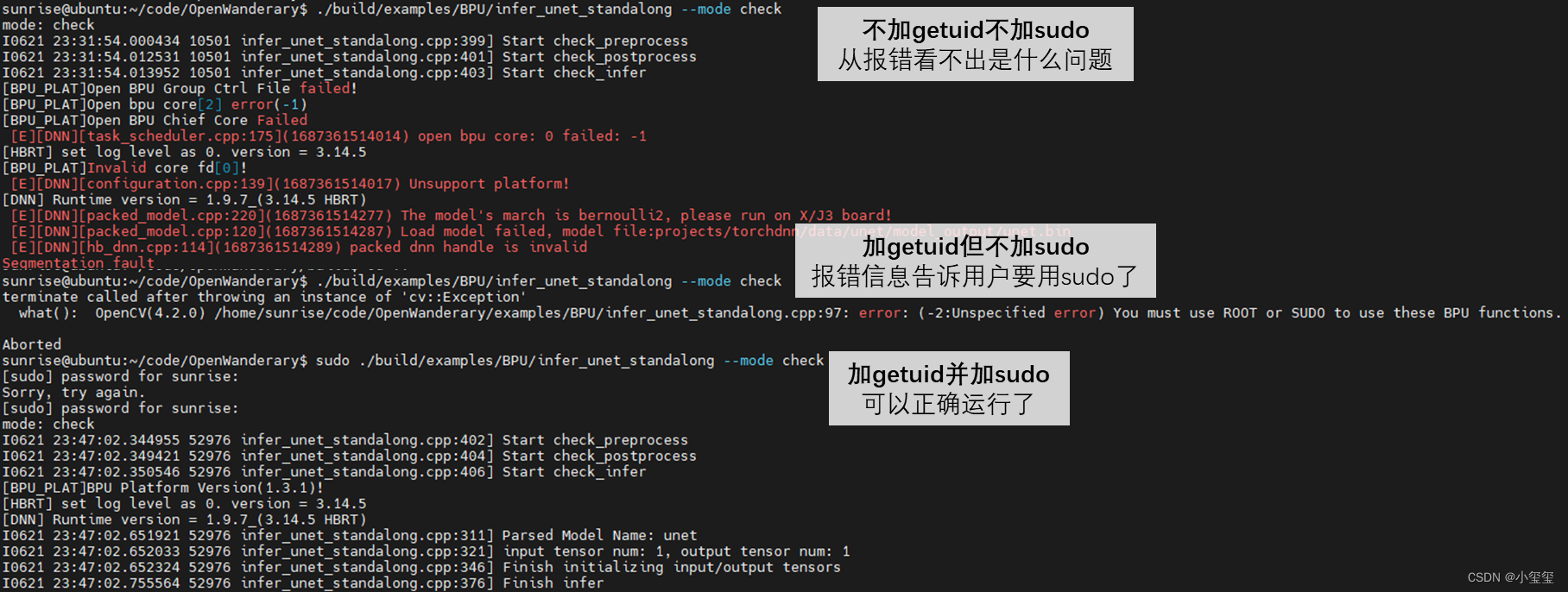
2.4.3 校验流程
从Python代码转C++代码,一下次就成功是很难的,这里的校验就非常关键了。这阶段的校验过程包含三个阶段:预处理、后处理、BIN模型校验,相比于其他几个阶段,这里的校验相互独立。

① C++板端预处理校验
预处理函数校验的代码细节如下所示:
② C++板端后处理校验
我们已经预先知道了后处理输入是一个4维float的矩阵,因此数据类型指定为CV_32FC1即可,后处理函数校验的代码细节如下所示:
③ C++板端推理校验
这个校验过程的代码包含一堆BPU模型加载/初始化/释放相关的代码,为了减少冗余,我只放上不一样的地方。
三 基于wdr::BPU的模型部署方案
从上面内容的介绍,我们可以了解了整体BPU的部署方案,整个方案是比较长的,特别是C++部署。
- 官方提供的BPU函数接口是C语言的。C语言是面向过程的语言,因此对于开发者来说,就存在很多不安全地方:操作是指针,内存分配和释放由用户指定,因此需要较多的学习和Debug成本。
- C++是面向对象的。既然是面向对象,就要考虑到开发者可能面临的一些错误,也就意味着C语言中存在的一些不安全性要从工具/代码的角度主动避免。
这套工具具有以下几个优点:
- 不需要开发者特意去学习更多的数据类型。数据操作以OpenCV的Mat为主,只要OpenCV用的比较熟,就很容易理解这个框架的使用方法。
- 大量重载运算符来意会功能。
- 比如访问第i个网络,直接用net[i]即可。
- 若想将推理输入Mat矩阵datain输入到第i个tensor中,则bpumats[i] << datain即可。将第i个tensor数据输出到Mat矩阵dataout中,则bpumats[i] >> dataout即可。这样极大降低用户操作成本。
- 规避了大量潜在的用户操作成本。
- 代码中大量使用CV_Error来判断用户的输入是否合法,不合法的输入将会给出详细的报错信息。
代码中也补充了大量开发者可能需要的API,矩阵/推理的基本操作都已经实现了。输入Tensor存在数据对齐问题,用户通过指定某个变量维true,交给工具完成自动对齐。
- Mode和Tensor的内存是自动释放的。在使用时,我们只需要初始化一下Tensor即可,在代码结束后,释放工作由库自动调用析构函数完成。
- 提供了多个功能的独立API函数,方便做更灵活的二次开发(目前还在测试中,后续会根据自己的需求不断完善)。
- BpuNets:多模型加载,初始化Tensor,以及推理。
- BpuMats:模型的输入/输出组,用于推理。
- BpuMat:每个Tensor的数据交互,BpuMats[idx]返回的就是BpuMat类型。
这个工具目前还在不断优化中,这里会给出一些demo来展示开发的库的方便性,文档之类的,待经过大量验证, 成熟了之后会单独发版,如果各位在使用时候出现Bug,欢迎反馈,一起调试。(业余时间开发的,时间很紧张,使用时候出现的问题求各位轻喷 ? )
下面基于WDR工具,给出两种C++部署功能。
3.1 利用WDR打印模型参数信息
3.2 利用WDR实现UNet推理
四 总结
去年11月-6月,历时8月,凝练出这个博客。创作空间统计的字数是4w+,预估阅读时间超过1个小时,哈哈哈。为了讲明白一件事,我自己不断的优化文案,废弃的文案也大概1w了。不断在打磨,就是在想办法提供给读者干货,删了一堆,最开始我想讲怎么配置cmake,vscode插件,C接口api也要想写个文档。后来发现,这没意义,我需要提供个各位的是部署意识,而不是字典类型的博客。从表达上也可能直接说清楚。
个人认为BPU部署三部曲,足够让不了解BPU的人能够踏入开发的大门。本系列的结束,是另一个内容的开始。这段时间内的整理,也发现BPU部署工具中存在一些地方可以优化,优化后可以让每个开发者轻松上阵,优化点整理如下:
- 从pytorch到bin模型这个阶段应该有一个可靠的工具。最终的目标就是谁都可以用,不需要了解太多,类似GPT一样,我需要什么就能给我什么。
- 要不断打磨底层API接口。目前用起来还行,除了数据对齐这个问题坑了一段时间。文档手册每个函数最好都能提供一个example来讲清楚用法。
- 模型转换过程存在不完备的验证。量化的onnx和板端的bin文件能确保结果一致吗,最好在开发板上也能安装horizon_nn。
- 简化部署/校验流程。流程多那就补充个可视化界面,每个工具,把明确输入+明确差异,写清楚,就几段话的事情。我开发时候经常面临问都不知道咋问的情况。
对于部署的未来工作:
不断打磨WDR库,修复其中的bug,而且对于工具链的更新也会尽可能做好适配。
将历史博客部署的一些算法的预处理和后处理用wdr实现推理。
博客内容较多,可能会存在一些错误,错误修复后我会及时更新在WDR仓库里,希望各位多多关注。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)