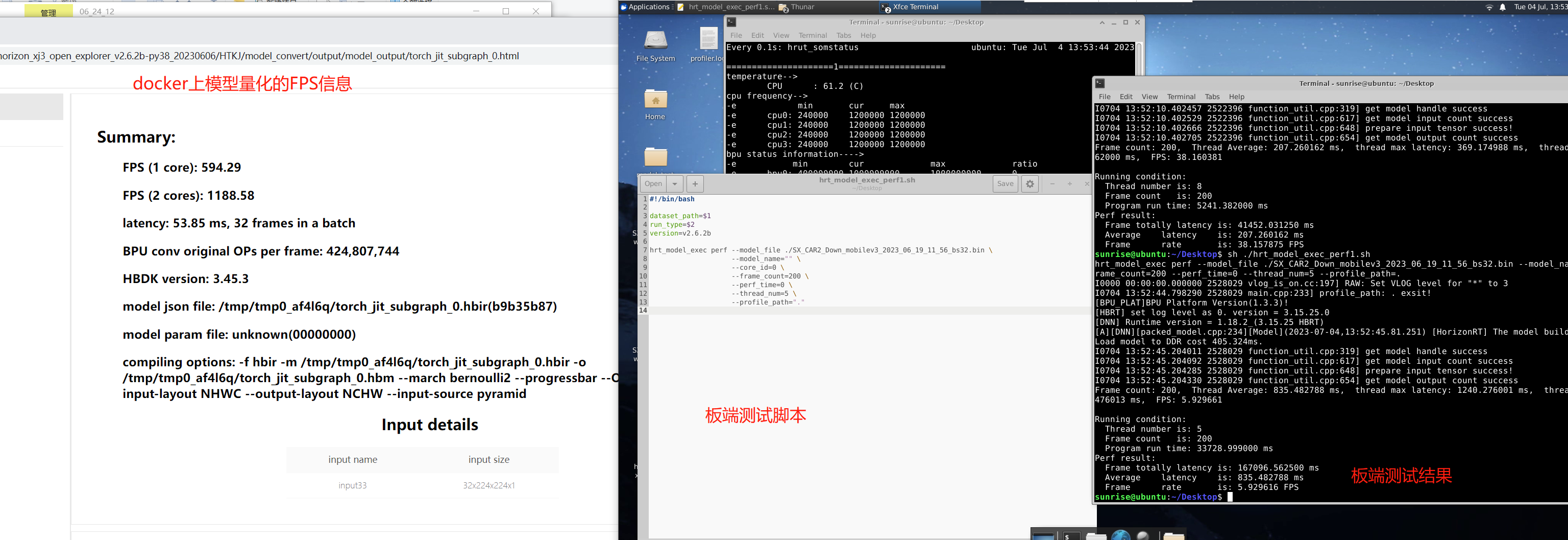
如图所示,在模型量化阶段数据显示模型的fps可以达到1000+,但在板端用脚本测试却只有5fps,差距太大了,请问可能有哪些原因,
文件里面有原始onnx文件,bin,yaml文件
文件链接:链接:https://pan.baidu.com/s/1vuS30cQlQ1sBlSrJVPI49w?pwd=1234
提取码:1234
--来自百度网盘超级会员V4的分享

如图所示,在模型量化阶段数据显示模型的fps可以达到1000+,但在板端用脚本测试却只有5fps,差距太大了,请问可能有哪些原因,
文件里面有原始onnx文件,bin,yaml文件
文件链接:链接:https://pan.baidu.com/s/1vuS30cQlQ1sBlSrJVPI49w?pwd=1234
提取码:1234
--来自百度网盘超级会员V4的分享

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.2
Lv.2您好,在模型量化阶段显示的模型性能数据是编译器对模型的性能预估,只考虑了运行在BPU上的节点,没有考虑运行在CPU上的节点。在docker中使用命令hb_perf xxx.bin即可生成对bin模型的性能分析信息,您看到的1000+ FPS的数据统计自如下红框部分,除此以外灰色框表示运行在CPU上的节点
运行在CPU上的节点也会大大降低模型性能。此外,您使用的是batch数为32的模型,在板端实际的FPS是5*batch,约为160FPS
您好,您可以在yaml文件中开启layer_out_dump,查看各节点耗时,用这种方法可以定位到耗时较大的节点。节点耗时较大一般是因为该节点存在大量的数据搬运操作。
抱歉写错了,这里是yaml文件里的debug参数
好的,谢谢
你好,这四个CPU节点除了softmax之外,其他三个好像都是编译时软件自己加上去的把,可以有办法去掉吗,另外有没有在板端C++运行多线程多核的代码案例可以学习一下