用户您好,请详细描述您所遇到的问题,这会帮助我们快速定位问题~
1.芯片型号:J5
2.天工开物开发包OpenExplorer版本:J5_OE_1.1.40
3.问题定位:板端部署等
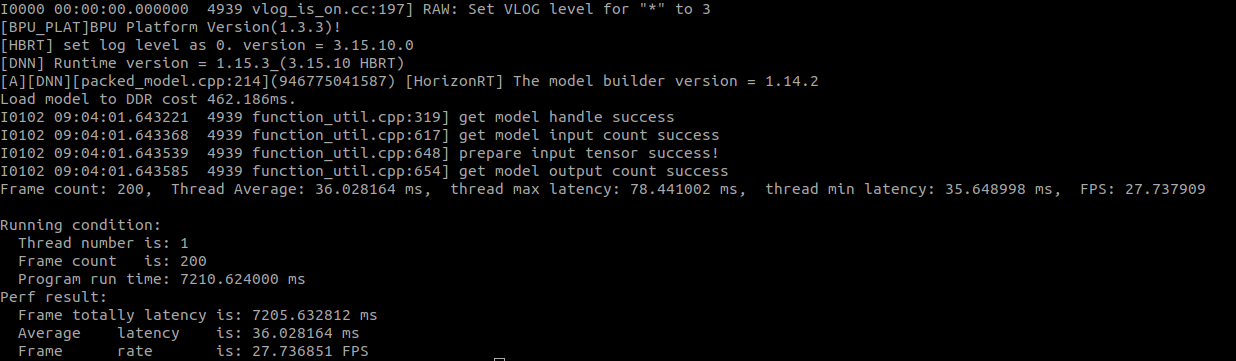
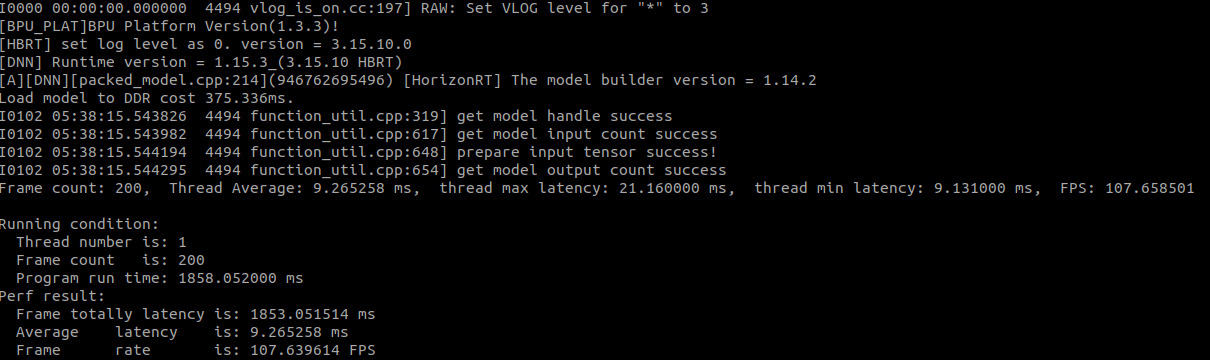
4.问题具体描述:PTQ模型导出yaml配置中,若设置了input_batch: 4, 板端hrt_model_exec perf 耗时36ms; 若不设置batch默认为1,板端耗时9.26ms。差不多就是四倍耗时,batch维度没有并行吗?

用户您好,请详细描述您所遇到的问题,这会帮助我们快速定位问题~

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.2
Lv.2设置--thread_num 1,耗时和上面一样,尝试设置1-8,线程数越大,耗时反而越大?这里模型输入为704×960
model batch :4 --thread_num 8
还是这个模型,batch为4,当我把模型结尾的三个算子强制运行在BPU上,开发机hb_perf 工具统计的耗时为什么减少而不是增多?我理解hb_perf统计BPU耗时,现在BPU上执行多三个Node,耗时要增多啊。
那这个较大模型,输入batch为4,从模型导出、板端执行的角度看有什么措施降低latency?
方便看一下尾部算子的结构图吗,那三个算子之前是哪个BPU算子?
concat 算子
hb_perf只是一个参考,实际还是要看上板实测的数据哈,如果确实很在意,可以在编译的时候将编译参数组的debug设置为true,那么hb_perf之后就可以看到每一个BPU算子的耗时了(不过debug设置true之后整体耗时会增加)
HzSQuantizedConv 之后这个HzRequantize是什么作用?
你可以点开onnx模型的这个算子,看一下经过这个算子前后,数据有什么变化。
Lv.2