
用户您好,请详细描述您所遇到的问题。
1.硬件获取渠道:
2.当前系统镜像版本:x3j3_lnx_db_20220407
3.当前天工开物版本:ai_toolchain_centos_7_xj3: v2.2.3a
4.问题定位:模型转化优化-乘积实现方式优化
5.开发的demo/案例:
6.需要提供的解决方案:
搭建了一个深度学习模型,这个模型中间的部分需要求解两个Featuremap的不同行像素位置之间的点乘,如图所示
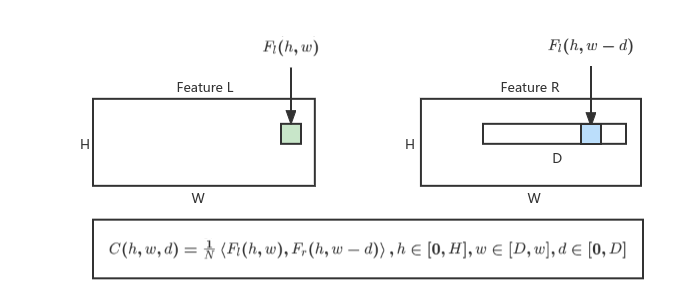 算法示意图
算法示意图
1.硬件获取渠道:
2.当前系统镜像版本:x3j3_lnx_db_20220407
3.当前天工开物版本:ai_toolchain_centos_7_xj3: v2.2.3a
4.问题定位:模型转化优化-乘积实现方式优化
5.开发的demo/案例:
6.需要提供的解决方案:
搭建了一个深度学习模型,这个模型中间的部分需要求解两个Featuremap的不同行像素位置之间的点乘,如图所示
算法示意图实现方法尝试
实现方法1
早期的实现方法如下所示
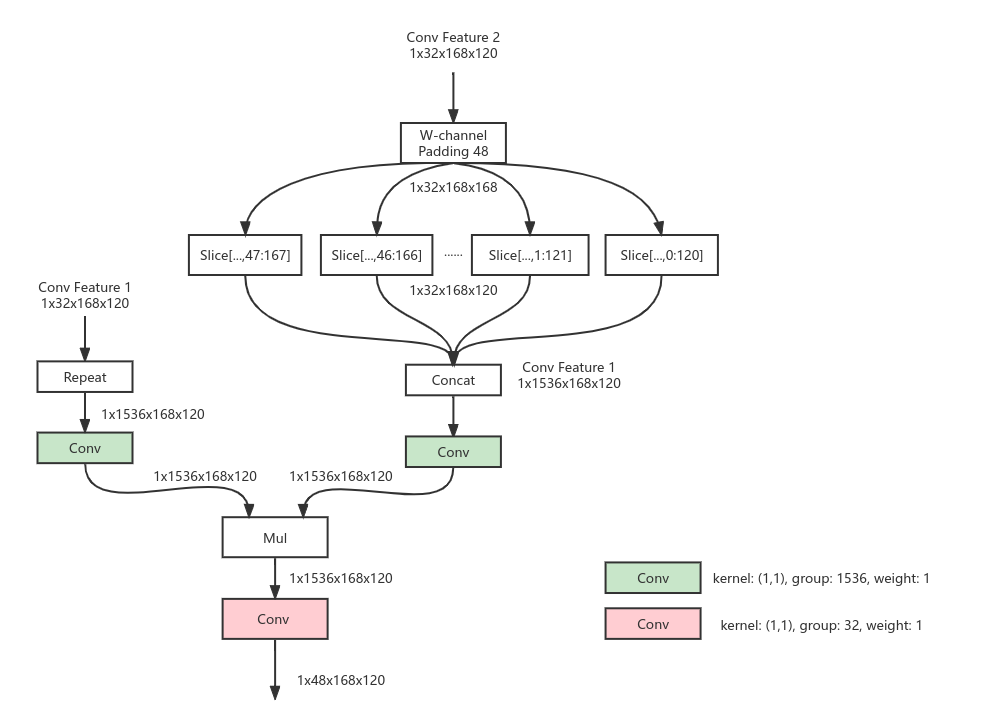 实现方法1
实现方法1
即将一个Featuremap重复,另一个Featuremap拼接,使两个很大的Tensors进行相乘。猜测太大的Mul使得推理变得很慢,且内存相关的操作使得后续的模型不能继续,从而使得整个模型变成两个子图,最终使得模型推理1次在core为2的情况下花费2.2s!
实现方法1即将一个Featuremap重复,另一个Featuremap拼接,使两个很大的Tensors进行相乘。猜测太大的Mul使得推理变得很慢,且内存相关的操作使得后续的模型不能继续,从而使得整个模型变成两个子图,最终使得模型推理1次在core为2的情况下花费2.2s!
实现方法2
目前的实现方法如下所示
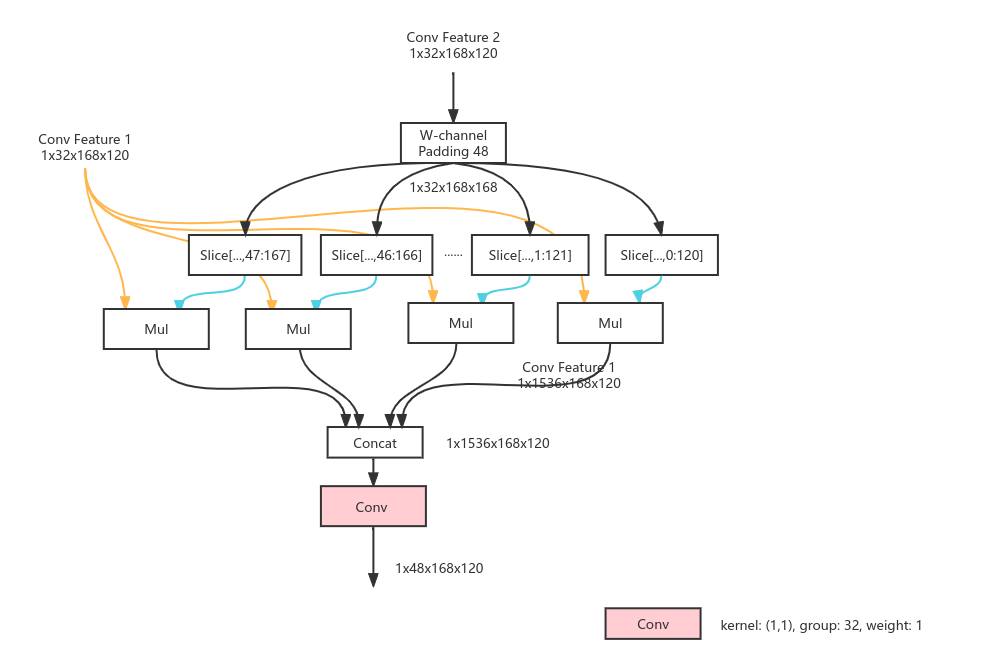 实现方法2
实现方法2
即多次调用Mul算子,在较小的Tensor上进行计算和内存存取
此方法使得模型从两个子图变为1个,使得模型推理1次在core为2的情况变成80ms(仅BPU),有了不小提升。
实现方法2即多次调用Mul算子,在较小的Tensor上进行计算和内存存取
此方法使得模型从两个子图变为1个,使得模型推理1次在core为2的情况变成80ms(仅BPU),有了不小提升。
但是此时发现一个问题,每个Mul算子乘积和存取的时间花费5.2ms左右,多个Mul算子占了整个推理时间的大部分,如下图所示
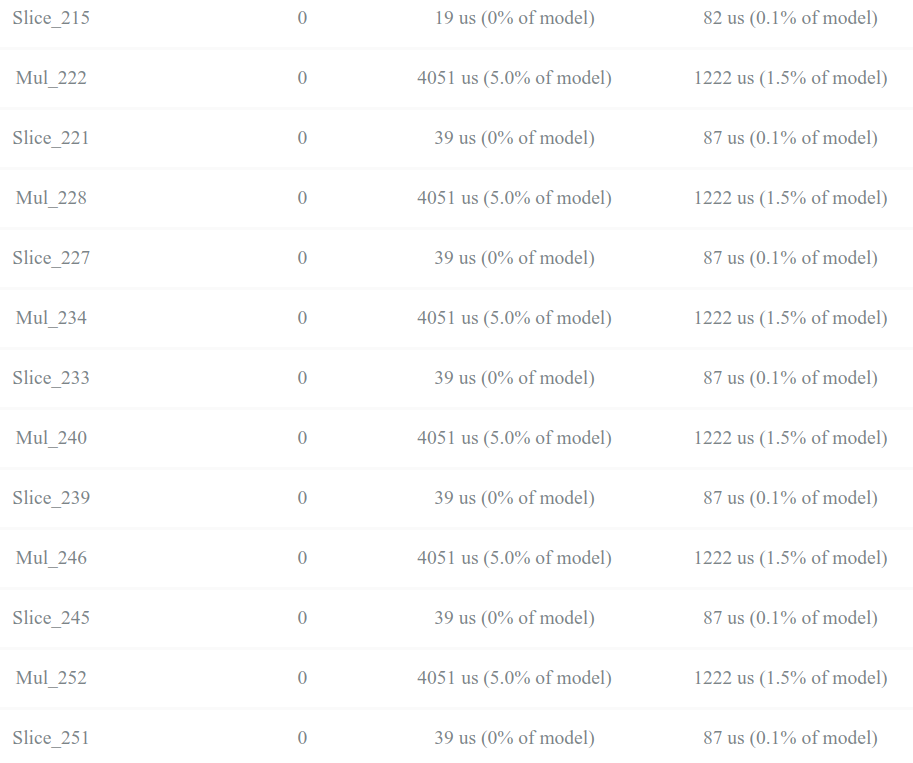 部分算子推理耗时
部分算子推理耗时
且如果Mul算子的耗时线性,则为了最终20Hz实时运行,得裁剪Mul次数,只能在小范围或者低精度上求解点积,最终会影响模型性能
部分算子推理耗时且如果Mul算子的耗时线性,则为了最终20Hz实时运行,得裁剪Mul次数,只能在小范围或者低精度上求解点积,最终会影响模型性能
想请问对于乘积实现方式优化,在模型设计和模型转化环节有没有优化之处

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
