
用户您好,请详细描述您所遇到的问题。
1.硬件获取渠道:
2.当前系统镜像版本:x3j3_lnx_db_20220407
3.当前天工开物版本:ai_toolchain_centos_7_xj3: v2.2.3a
4.问题定位:模型转化优化-卷积算子偏慢问题
5.开发的demo/案例:
6.需要提供的解决方案:
1.硬件获取渠道:
2.当前系统镜像版本:x3j3_lnx_db_20220407
3.当前天工开物版本:ai_toolchain_centos_7_xj3: v2.2.3a
4.问题定位:模型转化优化-卷积算子偏慢问题
5.开发的demo/案例:
6.需要提供的解决方案:
搭建了一个深度学习模型,这个模型最后的部分是由多个卷积构成的重复结构的残差块构成的。如图所示
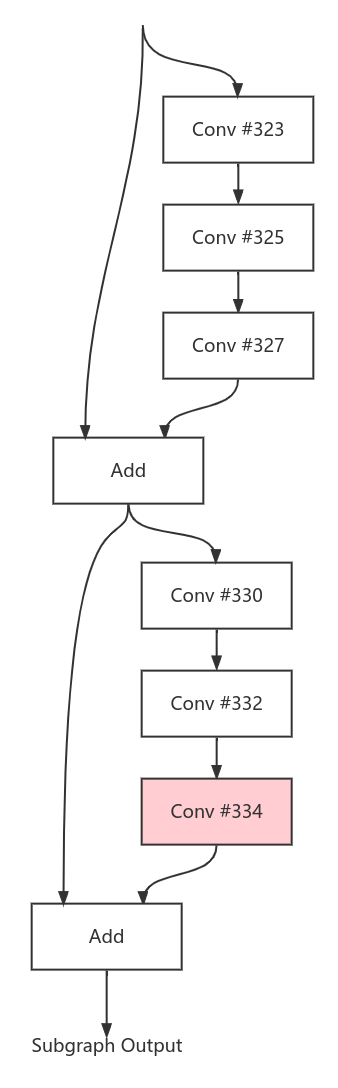 模型结构
模型结构
但是,在编译完成后发现,Conv #334花费的计算时间和存取时间远比其他卷积多,花费的时间如表所示
模型结构但是,在编译完成后发现,Conv #334花费的计算时间和存取时间远比其他卷积多,花费的时间如表所示
layer | ops | computing cost (no DDR) | load/store cost |
|---|---|---|---|
Conv_323-conv | 66,355,200 | 134 us (0.1% of model) | 1 us (0% of model) |
Conv_325-conv | 597,196,800 | 1184 us (1.4% of model) | 3 us (0% of model) |
Conv_327-conv | 66,355,200 | 132 us (0.1% of model) | 120 us (0.1% of model) |
Conv_330-conv | 66,355,200 | 132 us (0.1% of model) | 2 us (0% of model) |
Conv_332-conv | 597,196,800 | 1167 us (1.4% of model) | 122 us (0.1% of model) |
Conv_334 | 66,355,200 | 3646 us (4.5% of model) | 761 us (0.9% of model) |
请问同样的结构下Conv #334为啥会偏慢,是因为是树池之前的最后一个卷积吗?请问有没有规避方法

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
