我模型训练的时候输入图片格式是:bgr格式,并且向像素值都除了255,做了归一化。
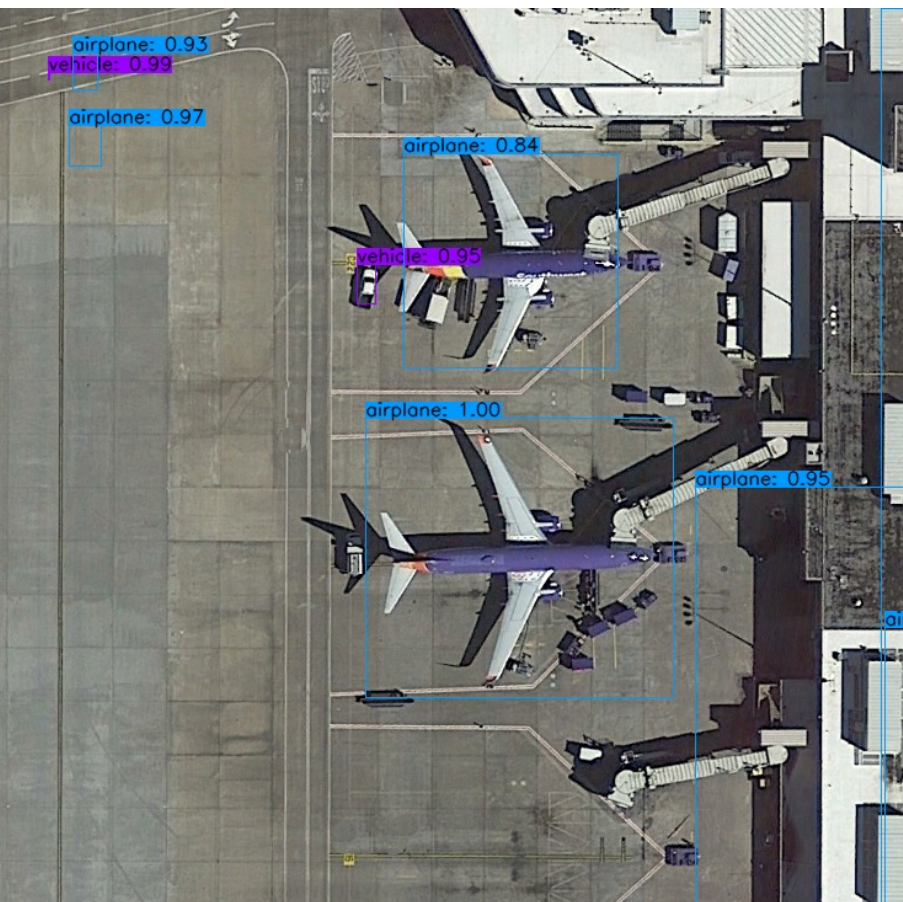
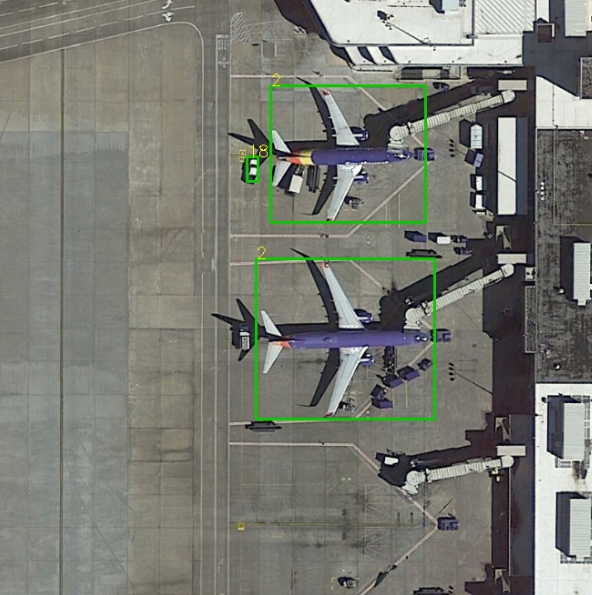
在工具链里面的mapper做 inference.sh的时候一个目标也输不出来,我看了一下置信度都是0.000及的级别,请问这是什么原因呢?
---------------------------------------------------------------------------------------------------------------------------------------------------------
我在工具链里的配置
def data_transformer(input_shape=(672, 672)):
transformers = [
PadResizeTransformer(input_shape),
TransposeTransformer((2, 0, 1)),
ScaleTransformer(1 / 255),
]
return transformers
transformers = [
PadResizeTransformer(input_shape),
TransposeTransformer((2, 0, 1)),
ScaleTransformer(1 / 255),
]
return transformers
************************************************************************************************
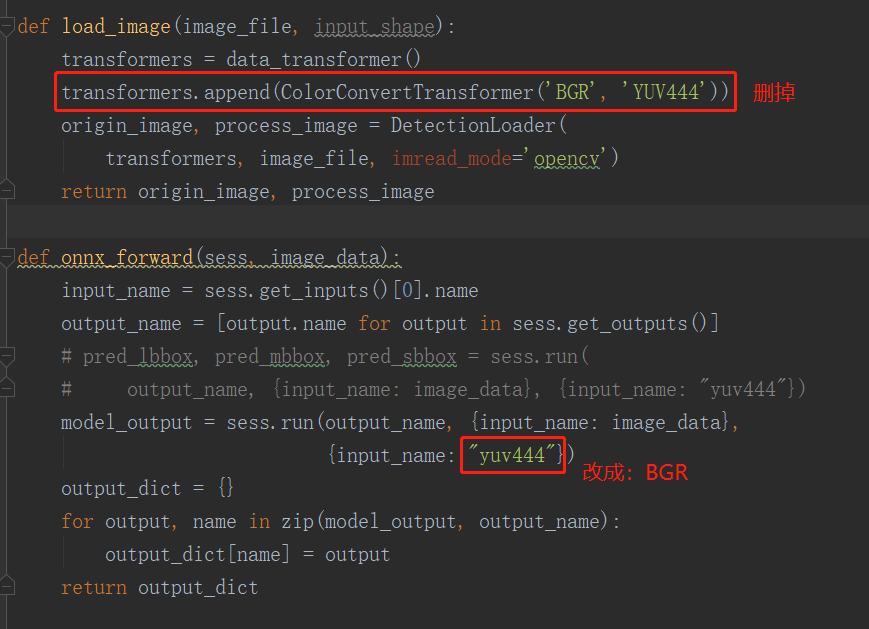
def load_image(image_file, input_shape):
transformers = data_transformer()
transformers.append(ColorConvertTransformer('BGR', 'YUV444'))
origin_image, process_image = DetectionLoader(
transformers, image_file, imread_mode='opencv')
return origin_image, process_image
transformers = data_transformer()
transformers.append(ColorConvertTransformer('BGR', 'YUV444'))
origin_image, process_image = DetectionLoader(
transformers, image_file, imread_mode='opencv')
return origin_image, process_image
************************************************************************************************
yolov3配置文件
model_parameters:
# Caffe浮点网络数据模型文件
onnx_model: './yolov3_wn.onnx'
# Caffe网络描述文件
prototxt: './yolov3_wn.onnx'
# 指定模型转换过程中是否输出各层的中间结果,如果为True,则输出所有层的中间输出结果,
layer_out_dump: False
# 用于设置上板模型输出的layout, 支持NHWC和NCHW, 输入None则使用模型默认格式
output_layout: NHWC
# 日志文件的输出控制参数,
# debug输出模型转换的详细信息
# info只输出关键信息
# warn输出警告和错误级别以上的信息
log_level: 'debug'
# 模型转换输出的结果的存放目录
working_dir: 'model_output'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'yolov3'
# 模型输入相关参数, 若输入多个节点, 则应使用';'进行分隔, 使用默认缺省设置则写None
input_parameters:
# (可不填) 模型输入的节点名称, 此名称应与模型文件中的名称一致, 否则会报错, 不填则会使用模型文件中的节点名称
input_name: 'data'
# 网络实际执行时,输入给网络的数据格式,包括 nv12/rgbp/bgrp/yuv444_128/gray/featuremap,
# 如果输入的数据为yuv444_128, 模型训练用的是rgbp,则hb_mapper将自动插入YUV到RGBP(NCHW)转化操作
input_type_rt: 'yuv444_128'
# 网络训练时输入的数据格式,可选的值为rgbp/bgrp/gray/featuremap/yuv444_128
input_type_train: 'bgrp'
# 网络输入的预处理方法,主要有以下几种:
# no_preprocess 不做任何操作
# mean_file 减去从通道均值文件(mean_file)得到的均值
# data_scale 对图像像素乘以data_scale系数
# mean_file_and_scale 减去通道均值后再乘以scale系数
norm_type: 'data_scale'
# (可不填) 模型网络的输入大小, 以'x'分隔, 不填则会使用模型文件中的网络输入大小
input_shape: '1x3x672x672'
# 图像减去的均值存放文件, 文件内存放的如果是通道均值,均值之间必须用空格分隔
mean_file: 'meanfile.txt'
# 图像预处理缩放比例,该数值应为浮点数
scale_value: 1.0
calibration_parameters:
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,输入的图片
# 应该是使用的典型场景,一般是从测试集中选择20~50张图片,另外输入
# 的图片要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 若有多个输入节点, 则应使用';'进行分隔
cal_data_dir: './calibration_data_rgbp'
# 如果输入的图片文件尺寸和模型训练的尺寸不一致时,并且preprocess_on为true,
# 则将采用默认预处理方法(opencv resize),
# 将输入图片缩放或者裁减到指定尺寸,否则,需要用户提前把图片处理为训练时的尺寸
preprocess_on: False
# 模型量化的算法类型,支持kl、max,通常采用KL即可满足要求
calibration_type: 'max'
# 模型的量化校准方法设置为promoter,mapper会根据calibration的数据对模型进行微调从而提高精度,
# promoter_level的级别,可选的参数为-1到2,建议按照0到2的顺序实验,满足精度即可停止实验
# -1: 不进行promoter
# 0:表示对模型进行轻微调节,精度提高比较小
# 1:表示相对0对模型调节幅度稍大,精度提高也比较多
# 2:表示调节比较激进,可能造成精度的大幅提高也可能造成精度下降
promoter_level: -1
# 编译器相关参数
compiler_parameters:
# 编译策略,支持bandwidth和latency两种优化模式;
# bandwidth以优化ddr的访问带宽为目标;
# latency以优化推理时间为目标
compile_mode: 'latency'
# 设置debug为True将打开编译器的debug模式,能够输出性能仿真的相关信息,如帧率、DDR带宽占用等
debug: False
# 编译模型指定核数,不指定默认编译单核模型, 若编译双核模型,将下边注释打开即可
# core_num: 2
# 设置每个fuction call最大执行时间,单位为us
# max_time_per_fc: 500
# 优化等级可选范围为O0~O3
# O0不做任何优化, 编译速度最快,优化程度最低,
# O1-O3随着优化等级提高,预期编译后的模型的执行速度会更快,但是所需编译时间也会变长。
# 推荐用O2做最快验证
optimize_level: 'O2'
# Caffe浮点网络数据模型文件
onnx_model: './yolov3_wn.onnx'
# Caffe网络描述文件
prototxt: './yolov3_wn.onnx'
# 指定模型转换过程中是否输出各层的中间结果,如果为True,则输出所有层的中间输出结果,
layer_out_dump: False
# 用于设置上板模型输出的layout, 支持NHWC和NCHW, 输入None则使用模型默认格式
output_layout: NHWC
# 日志文件的输出控制参数,
# debug输出模型转换的详细信息
# info只输出关键信息
# warn输出警告和错误级别以上的信息
log_level: 'debug'
# 模型转换输出的结果的存放目录
working_dir: 'model_output'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'yolov3'
# 模型输入相关参数, 若输入多个节点, 则应使用';'进行分隔, 使用默认缺省设置则写None
input_parameters:
# (可不填) 模型输入的节点名称, 此名称应与模型文件中的名称一致, 否则会报错, 不填则会使用模型文件中的节点名称
input_name: 'data'
# 网络实际执行时,输入给网络的数据格式,包括 nv12/rgbp/bgrp/yuv444_128/gray/featuremap,
# 如果输入的数据为yuv444_128, 模型训练用的是rgbp,则hb_mapper将自动插入YUV到RGBP(NCHW)转化操作
input_type_rt: 'yuv444_128'
# 网络训练时输入的数据格式,可选的值为rgbp/bgrp/gray/featuremap/yuv444_128
input_type_train: 'bgrp'
# 网络输入的预处理方法,主要有以下几种:
# no_preprocess 不做任何操作
# mean_file 减去从通道均值文件(mean_file)得到的均值
# data_scale 对图像像素乘以data_scale系数
# mean_file_and_scale 减去通道均值后再乘以scale系数
norm_type: 'data_scale'
# (可不填) 模型网络的输入大小, 以'x'分隔, 不填则会使用模型文件中的网络输入大小
input_shape: '1x3x672x672'
# 图像减去的均值存放文件, 文件内存放的如果是通道均值,均值之间必须用空格分隔
mean_file: 'meanfile.txt'
# 图像预处理缩放比例,该数值应为浮点数
scale_value: 1.0
calibration_parameters:
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,输入的图片
# 应该是使用的典型场景,一般是从测试集中选择20~50张图片,另外输入
# 的图片要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 若有多个输入节点, 则应使用';'进行分隔
cal_data_dir: './calibration_data_rgbp'
# 如果输入的图片文件尺寸和模型训练的尺寸不一致时,并且preprocess_on为true,
# 则将采用默认预处理方法(opencv resize),
# 将输入图片缩放或者裁减到指定尺寸,否则,需要用户提前把图片处理为训练时的尺寸
preprocess_on: False
# 模型量化的算法类型,支持kl、max,通常采用KL即可满足要求
calibration_type: 'max'
# 模型的量化校准方法设置为promoter,mapper会根据calibration的数据对模型进行微调从而提高精度,
# promoter_level的级别,可选的参数为-1到2,建议按照0到2的顺序实验,满足精度即可停止实验
# -1: 不进行promoter
# 0:表示对模型进行轻微调节,精度提高比较小
# 1:表示相对0对模型调节幅度稍大,精度提高也比较多
# 2:表示调节比较激进,可能造成精度的大幅提高也可能造成精度下降
promoter_level: -1
# 编译器相关参数
compiler_parameters:
# 编译策略,支持bandwidth和latency两种优化模式;
# bandwidth以优化ddr的访问带宽为目标;
# latency以优化推理时间为目标
compile_mode: 'latency'
# 设置debug为True将打开编译器的debug模式,能够输出性能仿真的相关信息,如帧率、DDR带宽占用等
debug: False
# 编译模型指定核数,不指定默认编译单核模型, 若编译双核模型,将下边注释打开即可
# core_num: 2
# 设置每个fuction call最大执行时间,单位为us
# max_time_per_fc: 500
# 优化等级可选范围为O0~O3
# O0不做任何优化, 编译速度最快,优化程度最低,
# O1-O3随着优化等级提高,预期编译后的模型的执行速度会更快,但是所需编译时间也会变长。
# 推荐用O2做最快验证
optimize_level: 'O2'

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)