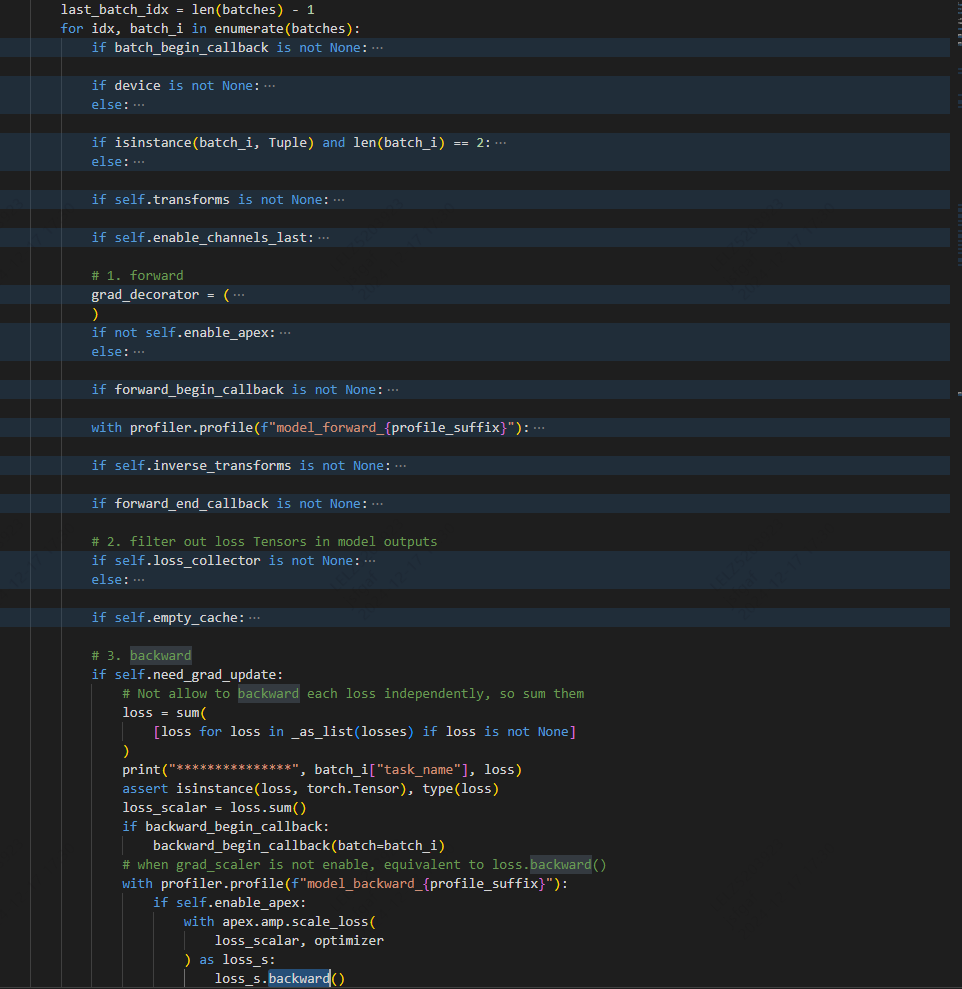
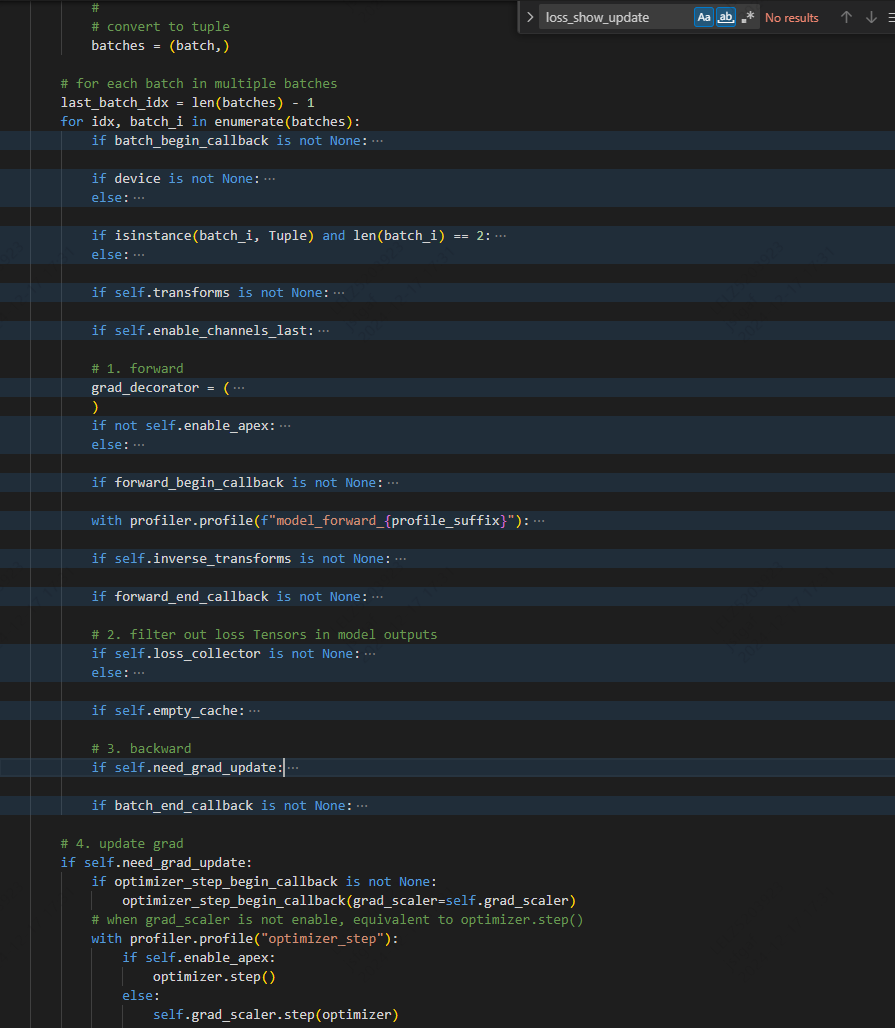
您好,在这个类中,batches包含了多个batch的数据,那每个bach的数据会通过module计算一个loss。我看到每个batch的数据会进行一个loss的backward(),但是最终循环处理完之后再进行update grade。我想问一下这最后一次进行梯度更新是,是用前面最后一个batch的loss计算的梯度更新,还是累计更新,这部分没有看明白,能否解答一下?
class MultiBatchProcessor(BatchProcessorMixin):
"""
Processor can forward backward multiple batches within a training step (before `optimizer.step()`).
It is useful for:
(1) Training a multitask model on single task annotation samples, of which
each task forward backward its batch sequentially within a multitask training step
(2) Training on a memory shortage GPU and want to increase batch size,
you are able to forward backward multiple batches within a training step
.. note::
Example multitask: vehicle, person and traffic light detection.
Single task annotation means only annotate vehicle bounding boxes on an image with vehicle,
person, and traffic light objects.
.. note::
Multiple batches should be organized in tuple format, e.g.
* `batch = (batch1, batch2, ...)`
If not, it will be treated as a single batch, e.g.
* `batch = dict(inputs=xx, target=xx)`
* `batch = [inputs, target]`
See code below for extra explanation.
It is much general in usage than `BasicBatchProcessor` , batch and model
outputs can be in any format, but note that if batch is a tuple means it contains multiple batches.
It is Hardware independent, run on cpu (device None) or gpu
(device is gpu id).
It is suitable for training (need_grad_update) and validation
(not need_grad_update).
Args:
need_grad_update: Whether need gradient update, True for training,
False for Validation.
batch_transforms: Config of batch transforms.
inverse_transforms: Config of transforms,
used for infer results transform inverse.
loss_collector: A callable object used to collect loss Tensors in model
outputs.
enable_amp: Whether training with `Automatic Mixed Precision`.
enable_amp_dtype: The dtype of amp, float16 or bfloat16.
enabel_apex: Whether training with `Apex`.
enable_channels_last: Whether training with `channels_last`.
channels_last_keys: Keys in batch need to convert to channels_last.
if None, all 4d-tensor in batch data will convert to channels_last.
delay_sync: Whether delay sync grad when train on DDP.
Refer to: DDP.no_sync() API
empty_cache: Whether to execute torch.cuda.empty_cache() after each
forward and backward run
grad_scaler: An instance ``scaler`` of :class:`GradScaler`
helps perform the steps of gradient scaling conveniently.
grad_accumulation_step: The step of grad accumulation.
Gradient accumulation refers to multiple backwards passes are
performed before updating the parameters. The goal is to update
the model's parameters based on different steps,
instead of performing an update after every single batch.
""" # noqa
def __init__(
self,
need_grad_update: bool,
batch_transforms: Optional[List] = None,
inverse_transforms: Optional[List] = None,
loss_collector: Callable = None,
enable_amp: bool = False,
enable_amp_dtype: torch.dtype = torch.float16,
enable_apex: bool = False,
enable_channels_last: bool = False,
channels_last_keys: Optional[Sequence[str]] = None,
delay_sync: bool = False,
empty_cache: bool = False,
grad_scaler: torch.cuda.amp.GradScaler = None,
grad_accumulation_step: Union[int, str] = 1,
):
if need_grad_update:
assert (
loss_collector is not None
), "Provide `loss_collector` when need_grad_update"
assert callable(loss_collector)
if enable_amp and enable_apex:
raise RuntimeError(
"enable_amp and enable_apex cannot be true together."
)
if enable_apex and apex is None:
raise ModuleNotFoundError("Apex is required.")
self.ga_step = grad_accumulation_step
if delay_sync or self.ga_step > 1:
torch_version = torch.__version__
assert (enable_apex and apex is not None) or LooseVersion(
torch_version
) >= LooseVersion(
"1.10.2"
), "Delay sync or grad accumulation \
need apex enabled or higher version of torch."
if enable_amp_dtype == torch.bfloat16:
if not torch.cuda.is_bf16_supported():
raise RuntimeError(
"current gpu devices do not support bfloat16."
)
self.need_grad_update = need_grad_update
self.loss_collector = loss_collector
self.enable_amp_dtype = enable_amp_dtype
self.enable_apex = enable_apex
self.enable_channels_last = enable_channels_last
self.channels_last_keys = channels_last_keys
self.delay_sync = delay_sync
self.empty_cache = empty_cache
if grad_scaler is not None:
self.grad_scaler = grad_scaler
else:
self.grad_scaler = GradScaler(enabled=enable_amp)
self.enable_amp = self.grad_scaler.is_enabled()
if enable_amp:
assert self.enable_amp, (
"When grad_scaler is not None, enable_amp does not work."
"You set enable_amp is {}, but the enable_amp of "
"grad_scaler is {}. Please check your config!!"
).format(enable_amp, self.enable_amp)
if batch_transforms:
if isinstance(batch_transforms, (list, tuple)):
batch_transforms = torchvision.transforms.Compose(
batch_transforms
) # noqa
self.transforms = batch_transforms
else:
self.transforms = None
self.inverse_transforms = inverse_transforms
def __call__(
self,
step_id: int,
batch: Union[Tuple[Any], List[Any], object],
model: torch.nn.Module,
device: Union[int, None],
optimizer=None,
storage: EventStorage = None,
batch_begin_callback: Callable = None,
batch_end_callback: Callable = None,
backward_begin_callback: Callable = None,
backward_end_callback: Callable = None,
optimizer_step_begin_callback: Callable = None,
forward_begin_callback: Callable = None,
forward_end_callback: Callable = None,
profiler: Optional[Union[BaseProfiler, str]] = None,
):
assert self.need_grad_update == model.training, (
"%s vs. %s, set model to training/eval mode by "
"model.train()/model.eval() when need_grad_update or not"
% (self.need_grad_update, model.training)
)
if profiler is None:
profiler = PassThroughProfiler()
# 0. reset grad
if self.need_grad_update:
with profiler.profile("optimizer_zero_grad"):
optimizer.zero_grad(set_to_none=True)
if isinstance(batch, tuple):
# Means that `batch_data` contains multiple batches, e.g.
# (1) contains task specific batches of a `multitask model`
# batch_data = (
# [task1_data1, task1_data2, ...], # task1 batch
# [task2_data1, task2_data2, ...], # task2 batch
# [task3_data1, task3_data2, ...], # can be list/tuple of objs
# task4_data # or just a single obj
# ...
# )
#
# (2) contains multiple batches for a single task model
# batch_data = (
# [batch1_data1, batch1_data2, ...],
# [batch2_data1, batch2_data2, ...], # can be list/tuple of objs
# data1 # or just a single obj
# ...
# )
batches = batch
else:
# Means that `data` just contains a single batch, e.g.
# (1) is a single obj
# batch_data = task_data # e.g. a dict(inputs=xx, target=xx)
#
# (2) is a list (NOT A TUPLE) of objs
# batch_data = [task_data1, task_data2, ...]
#
# convert to tuple
batches = (batch,)
# for each batch in multiple batches
last_batch_idx = len(batches) - 1
for idx, batch_i in enumerate(batches):
if batch_begin_callback is not None:
batch_begin_callback(batch=batch_i, batch_idx=idx)
if device is not None:
batch_i = to_cuda(batch_i, device, non_blocking=True)
else:
# run on cpu
pass
if isinstance(batch_i, Tuple) and len(batch_i) == 2:
profile_suffix = batch_i[1]
else:
profile_suffix = idx
if self.transforms is not None:
with profiler.profile(f"batch_transforms_{profile_suffix}"):
batch_i = (self.transforms(batch_i[0]), batch_i[1])
if self.enable_channels_last:
batch_i = convert_memory_format(
batch_i, self.channels_last_keys, torch.channels_last
)
# 1. forward
grad_decorator = (
torch.enable_grad if self.need_grad_update else torch.no_grad
)
if not self.enable_apex:
auto_cast = autocast(
enabled=self.enable_amp, dtype=self.enable_amp_dtype
)
else:
auto_cast = localcontext()
if forward_begin_callback is not None:
forward_begin_callback(batch=batch_i, model=model)
with profiler.profile(f"model_forward_{profile_suffix}"):
with auto_cast:
with grad_decorator():
if self.delay_sync and idx != last_batch_idx:
# delay sync grad util last batch in mt tuple.
if hasattr(model, "disable_allreduce"):
model.disable_allreduce()
elif (
self.ga_step > 1
and step_id % self.ga_step != 0
and idx != last_batch_idx
):
# delay sync grad by grad accumulation step.
if hasattr(model, "disable_allreduce"):
model.disable_allreduce()
else:
# only support enable_allreduce in apex
if hasattr(model, "enable_allreduce"):
model.enable_allreduce()
# model outputs can be in any format
model_outs = model(*_as_list(batch_i))
if self.inverse_transforms is not None:
model_outs = self.inverse_transforms(model_outs, batch_i)
if forward_end_callback is not None:
forward_end_callback(model_outs=model_outs, batch_idx=idx)
# 2. filter out loss Tensors in model outputs
if self.loss_collector is not None:
losses = self.loss_collector(model_outs)
else:
losses = None
if self.empty_cache:
torch.cuda.empty_cache()
# 3. backward
if self.need_grad_update:
# Not allow to backward each loss independently, so sum them
loss = sum(
[loss for loss in _as_list(losses) if loss is not None]
)
print("***************", batch_i["task_name"], loss)
assert isinstance(loss, torch.Tensor), type(loss)
loss_scalar = loss.sum()
if backward_begin_callback:
backward_begin_callback(batch=batch_i)
# when grad_scaler is not enable, equivalent to loss.backward()
with profiler.profile(f"model_backward_{profile_suffix}"):
if self.enable_apex:
with apex.amp.scale_loss(
loss_scalar, optimizer
) as loss_s:
loss_s.backward()
else:
if self.delay_sync and idx != last_batch_idx:
# delay sync grad util last batch in mt tuple.
with model.no_sync():
self.grad_scaler.scale(loss_scalar).backward()
elif (
self.ga_step > 1
and step_id % self.ga_step != 0
and idx != last_batch_idx
):
# delay sync grad by grad accumulation step.
with model.no_sync():
self.grad_scaler.scale(loss_scalar).backward()
else:
self.grad_scaler.scale(loss_scalar).backward()
if backward_end_callback:
backward_end_callback(batch=batch_i, batch_idx=idx)
if batch_end_callback is not None:
batch_end_callback(
batch=batch_i, losses=losses, model_outs=model_outs
)
# 4. update grad
if self.need_grad_update:
if optimizer_step_begin_callback is not None:
optimizer_step_begin_callback(grad_scaler=self.grad_scaler)
# when grad_scaler is not enable, equivalent to optimizer.step()
with profiler.profile("optimizer_step"):
if self.enable_apex:
optimizer.step()
else:
self.grad_scaler.step(optimizer)
self.grad_scaler.update()
if self.empty_cache:
torch.cuda.empty_cache()
if self.enable_amp:
storage.put(
"grad_scaler", self.grad_scaler.state_dict(), always_dict=True
)


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)