采用J6,量化工具链,采用非fast模式用校验数据转换模型。跑出来的hbm模型上板测发现有很多算子运行在cpu上了。请问yaml里可以配置让算子强制运行在bpu上吗?

专栏算法工具链求助,PTQ 非fast模式怎么配置可以强制让算子运行在bpu上?
求助,PTQ 非fast模式怎么配置可以强制让算子运行在bpu上?
已解决
长城上贴瓷砖2024-12-25
125
21
算法工具链
征程6



评论3
0/600
- HuangHui
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.5
Lv.5在量化配置中的node_config中配置float32量化就OK
2024-12-2501- 长城上贴瓷砖回复HuangHui:
我写错了不好意思。我是说怎么让算子强制运行在bpu上。float32应该是在cpu上吧。
2024-12-250
- 长城上贴瓷砖Lv.1
请问有什么配置专门指定算子放在bpu上的吗?
2024-12-25015- HuangHui回复长城上贴瓷砖:
这个不用特别的指定,BPU支持的算子,工具链会优先选择通过BPU支持的。对于临输出的算子,考虑高精度输出,肯能链路会提前反量化后将一些算子运行在CPU上,对于这种如果确实需要跑回到BPU的,可以 在量化配置中的node_config中配置中指定类型为int8/int16就OK了,如下
"node_config": { // 配置某个节点的输入数据类型
"node_name1": {"qtype": "int8"/"int16"}
}
2024-12-260 - HuangHui回复长城上贴瓷砖:
 2024-12-260
2024-12-260 - 长城上贴瓷砖回复HuangHui:
好的。请问softmax是可能会被放到cpu吗?我在profile上发现我attention里面的softmax被放了好多在cpu上。
2024-12-260 - HuangHui回复长城上贴瓷砖:
应该是可以的,你试试呗
{ "op_config": { "Softmax": {"qtype": "int8"} } }
2024-12-260 - 长城上贴瓷砖回复HuangHui:
好的。我是想问softmax这个算子有什么特殊性,会比较容易被放到cpu上吗?
2024-12-260 - HuangHui回复长城上贴瓷砖:
只是出于精度考虑,默认跑在了CPU。不过跟模型的量化友好性也相关,支持手动移到BPU的,如果移到BPU,精度没有大的影响,就跑BPU就好了
2024-12-260 - 长城上贴瓷砖回复HuangHui:
啊,softmax默认在cpu上吗?我看别人跑了bevformer,里面也有softmax,profile里没显示在cpu上。它是看模型有的在cpu上有的在bpu上吗?
2024-12-260 - HuangHui回复长城上贴瓷砖:
 上面这个是J5上的情况,J6上算子约束列表中没写,但是应该也是这样的,我确认后跟你说。但无论默认如何,CPU的精度相对好,性能不好;BPU性能好,但精度可能不好但也不绝对,所以通过配置然后以你编译的结果测试为准,毕竟你都知道怎么配置跑BPU,CPU了2024-12-260
上面这个是J5上的情况,J6上算子约束列表中没写,但是应该也是这样的,我确认后跟你说。但无论默认如何,CPU的精度相对好,性能不好;BPU性能好,但精度可能不好但也不绝对,所以通过配置然后以你编译的结果测试为准,毕竟你都知道怎么配置跑BPU,CPU了2024-12-260 - 长城上贴瓷砖回复HuangHui:
好的感谢
2024-12-260 - HuangHui回复长城上贴瓷砖:
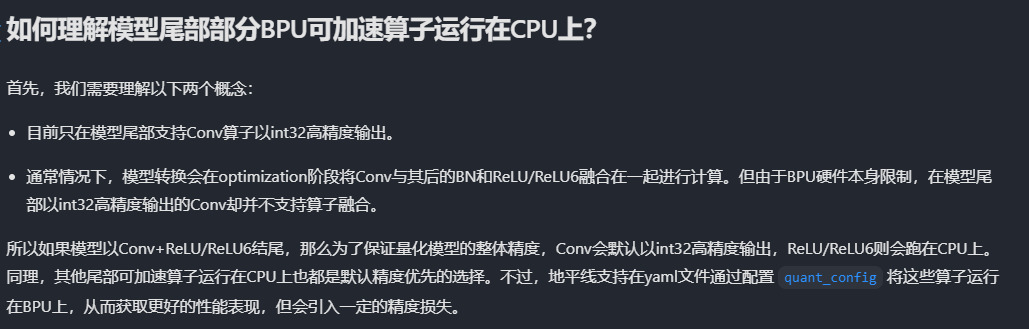
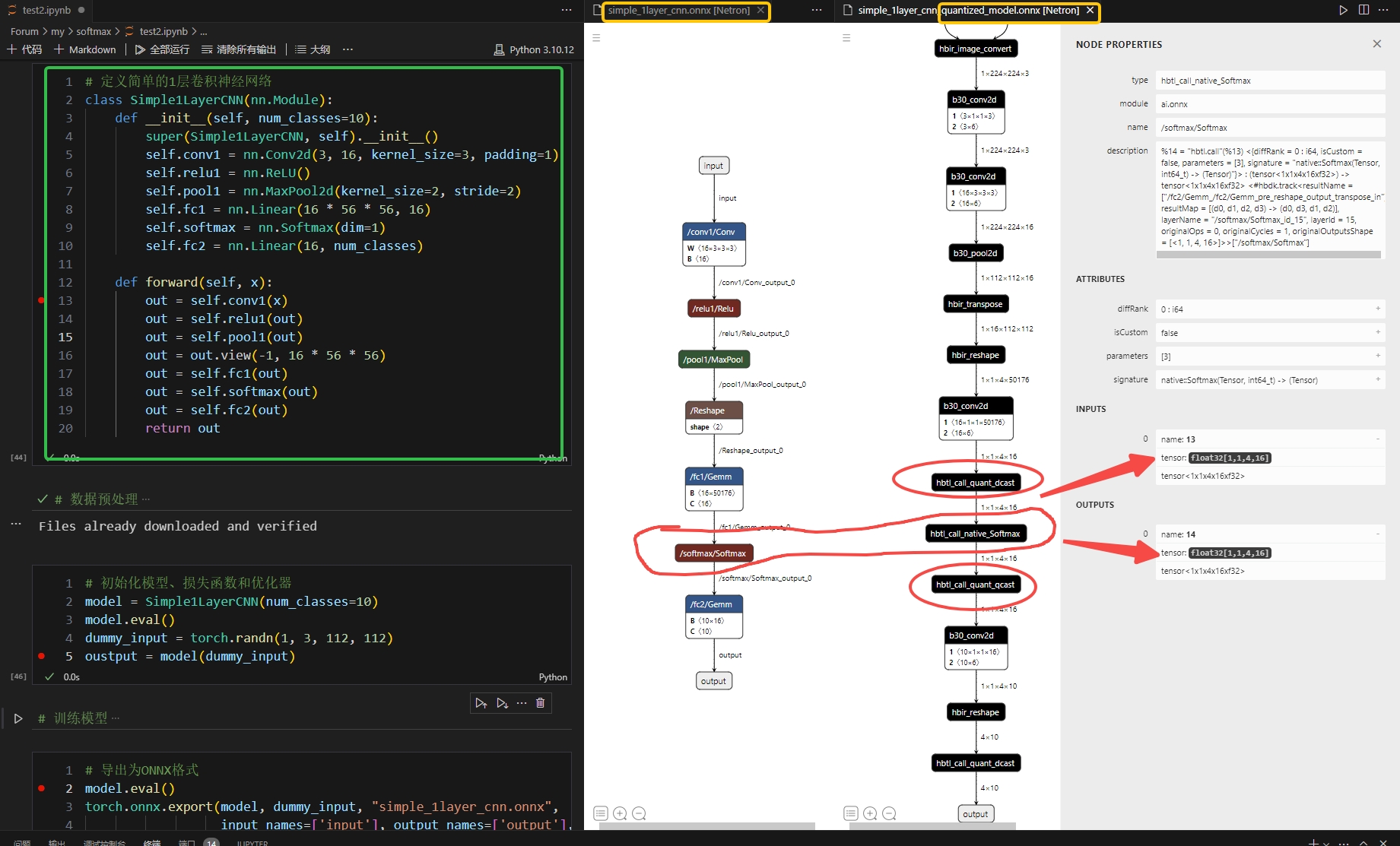 上面这个是默认不做特殊配置
上面这个是默认不做特殊配置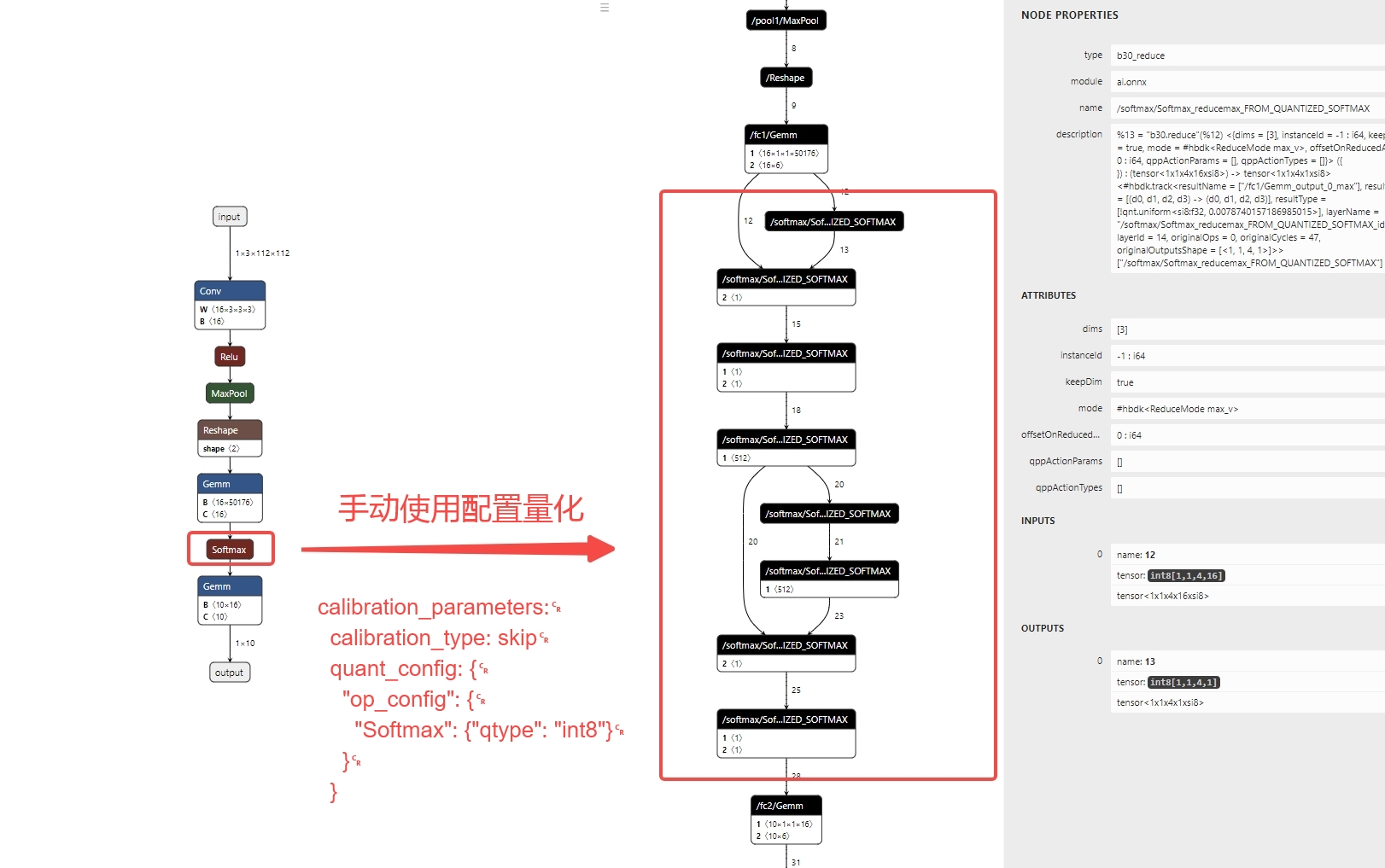 这个是手动量化配置之后
这个是手动量化配置之后结论:j6和J5一样,正对softmap,考虑精度影响,默认是CPU运行的,但支持BPU运行,需要手动配置并由用户自己对开启后的精度影响评估然后确定是否要再BPU运行
2024-12-260 - 长城上贴瓷砖回复HuangHui:
所以默认放在cpu上是默认为float32执行了是吗?手动配置为int8,为什么拆分成这么多节点了呀,是把softamx分成了好多个计算吗,是什么啊?
2024-12-260 - HuangHui回复长城上贴瓷砖:
1. 对的,默认就是在CPU上跑的,你如果想通过BPU加速就手动配置,但是跑BPU后肯能精度不好,这个评估和是否要通过BPU加速,你自己决定。
2. 拆成这么多算子是使用BPU加速时硬件结构等因素决定的,这个数据算子实现的事情,用户侧只需要决定是否在BPU上跑就OK。其实你也可以看到SOFT落地过程中存在LUT(查表)算子,这个大部分时候对精度是有损伤的。
2024-12-260 - 长城上贴瓷砖回复HuangHui:
好的
2024-12-260 - 长城上贴瓷砖回复HuangHui:
前面这个截图的这段话有点儿不理解。int32也是运行在bpu上吧?意思是通常情况下,conv+relu融合,一起为int8执行在bpu上。但如果conv在模型结尾,变成int32输出,还是在bpu上,relu没办法一起融合为int32,所以relu单独变成float32在cpu上执行?
2024-12-260 - 长城上贴瓷砖回复HuangHui:
我这边测试 bpu上int8的softmax精度不好,cpu上fp32的softmax太慢,请问下bpu能跑更高精度的softmax吗?比如fp32或者fp16
2025-01-120
- DR_KANLv.5
你可以对比下fast-perf的yaml文件,应该就 差一个optimization: run_fast吧,可以试试这个参数
2024-12-2702- 长城上贴瓷砖回复DR_KAN:
1. 看不到fast-perf的yaml文件呢,我正好想问问怎么能看到这个哪里可以看到啊?
2. run_fast在文档里没看到,这个怎么配置,放在哪个参数下面?这个可以和我的校验数据共存的吗?
2024-12-300 - HuangHui回复长城上贴瓷砖:
fast-perf的执行和文件参考下面操作和内容就可以了:
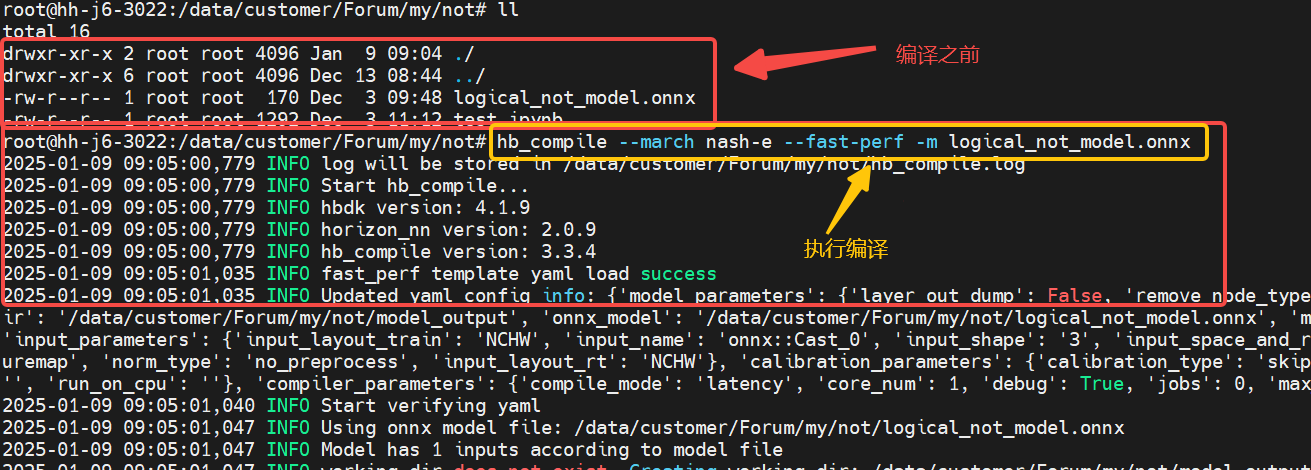
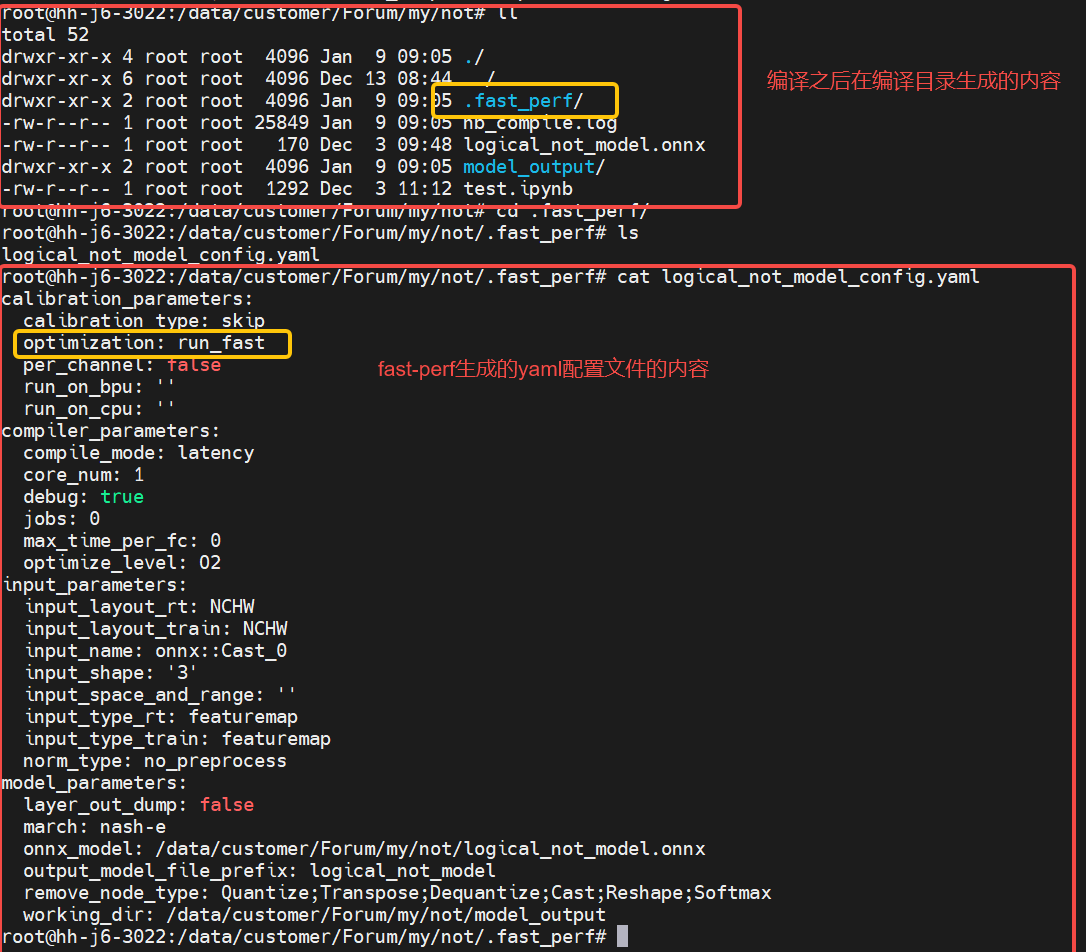 2025-01-090
2025-01-090