如题,我将模型正常编译之后,在板端的耗时测得12ms,使用 profile_path 工具得到如下信息:

总的耗时如下:
总的耗时如下:
目前已知的信息是cpu算子和gpu算子都有较大的latency,我想针对耗时做一些优化,但是目前只有尝试了在compile的时候将opt调整为2,可惜耗时没有明显变化,所以想请教一下,针对板端耗时的优化有什么策略路线或者其他博客资料么~

目前已知的信息是cpu算子和gpu算子都有较大的latency,我想针对耗时做一些优化,但是目前只有尝试了在compile的时候将opt调整为2,可惜耗时没有明显变化,所以想请教一下,针对板端耗时的优化有什么策略路线或者其他博客资料么~


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Lv.1
Lv.1好像点进来看不到具体评论
你的图片上传有问题,都花了,看看能不能重新上传下
你重新发布下试试看
Lv.1sorry 补上两张图,是关于profiling的耗时分析
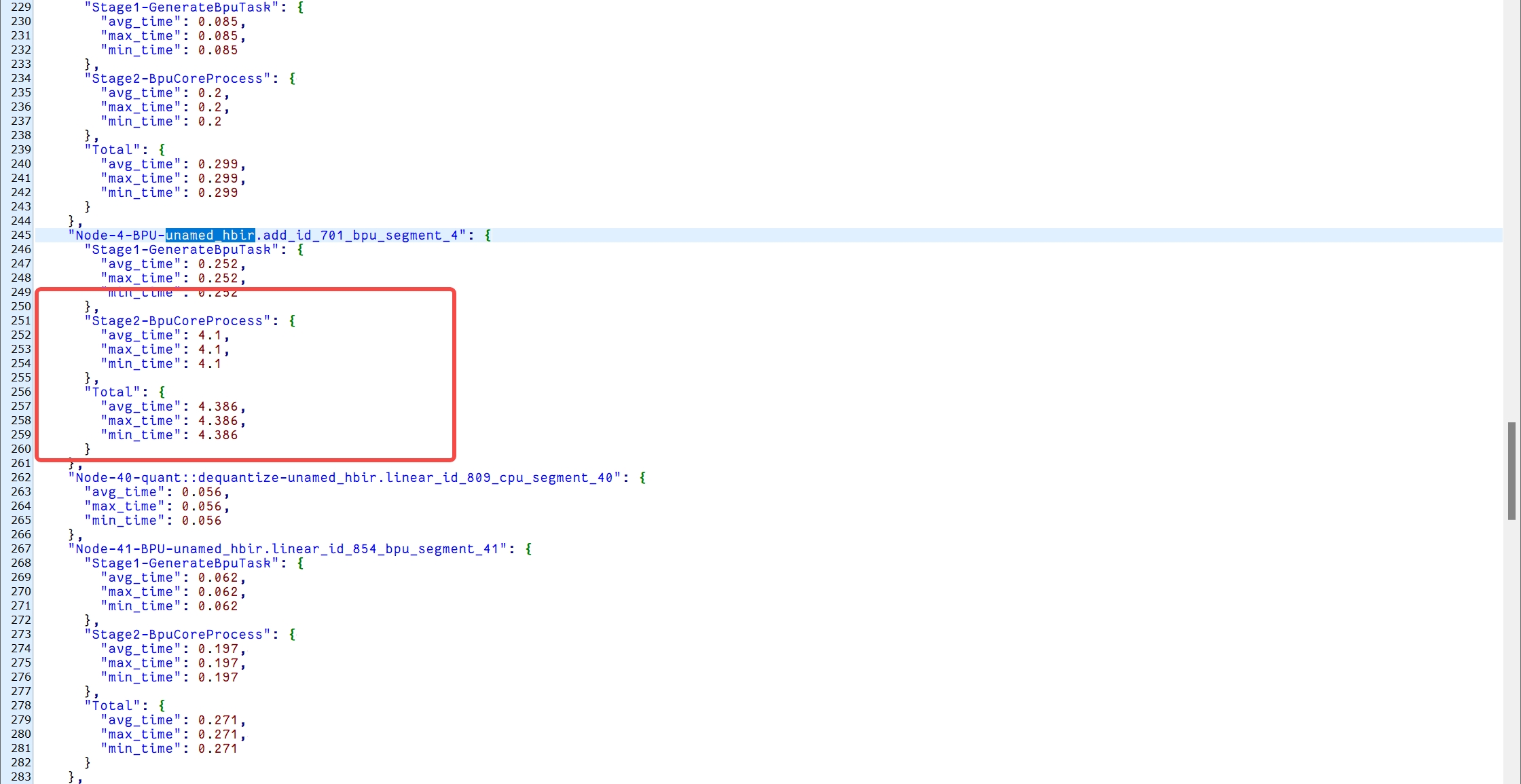

 周末愉快啊 有空再讨论下吧~Lv.1
周末愉快啊 有空再讨论下吧~Lv.1ps: cpu上的算子是scatterND算子导致的, 不知道是否能够有什么替换方式
主要原因是scatterND算子是非连续、随机写入的。 不符合现代硬件对连续内存访问与并行计算的优化习惯 。
ScatterND会往张量的任意位置写数据。 这些写入是不可预测的 。
明白了 感谢解答
Lv.5谢谢大佬,我去看看