
本文基于地平线征程6芯片的特性以及部署经验积累,将在各场景的模型设计上给出高效模型结构建议,以达到加速用户的模型部署效率和落地效果的目的。
高效backbone
为了 提供针对 J6 系列芯片专门设计的高效 backbone,结合 J6 芯片的硬件特性,设计了高效模型 HENet (Hybrid Efficient Network)。
模型介绍参考社区文章:https://developer.horizon.auto/blog/10144
模型 | 输入大小 | J6E 帧率(FPS) | J6M 帧率(FPS) | 浮点精度 | 量化精度 | 数据集 |
|---|---|---|---|---|---|---|
resnet18 | 1x3x224x224 | 2456 | 3146 | 72.04 | 71.64 | ImageNet |
1x3x704x1280 | 306 | 391 | / | / | ImageNet | |
resnet50 | 1x3x224x224 | 1092 | 1490 | 77.38 | 76.78 | ImageNet |
1x3x704x1280 | 124 | 168 | / | / | ImageNet | |
efficientnet-b0 | 1x3x224x224 | 3379 | 4004 | 74.31 | 73.85 | ImageNet |
1x3x704x1280 | 472 | 620 | / | / | ImageNet | |
mobilenetv2 | 1x3x224x224 | 4172 | 5988 | 72.63 | 71.47 | ImageNet |
1x3x704x1280 | 732 | 942 | / | / | ImageNet | |
mixvargenet | 1x3x224x224 | 3928 | 4114 | 71.32 | 70.63 | ImageNet |
1x3x704x1280 | 485 | 653 | / | / | ImageNet | |
vargnetv2 | 1x3x224x224 | 2661 | 3307 | 73.93 | 73.17 | ImageNet |
1x3x704x1280 | 631 | 860 | / | / | ImageNet | |
HENet_TinyE | 1x3x224x224 | 2637 | 3268 | 77.67 | 76.92 | ImageNet |
1x3x704x1280 | 534 | 737 | / | / | ImageNet | |
HENet_TinyM | 1x3x224x224 | 2467 | 3114 | 78.38 | 77.62 | ImageNet |
1x3x704x1280 | 444 | 605 | / | / | ImageNet |
Transformer Attention
MSDA
地平线attention算子在保持算子逻辑等价的同时在效率上进行了优化。主要优化点有:
将部分耗时较长的element-wise 类型的算子改为Linear实现(reduce_sum)
去除gridsample后的reshape操作,减少translayout
数值融合,量化阶段提前融合部分数值操作,将norm操作融合到sampling_offsets中,可以减少量化误差,同时提高部署效率
数值融合部分,需要先将模型转换为部署模型,准备数值融合,代码如下:
LSS/Bevpool 部署攻略
LSS v1
LSS为BEV转换的方式,LSS转换最重要的操作为bevpool操作,bevpool中的index操作对J6芯片硬件并不友好,因此给出替换方式,使其可以部署。
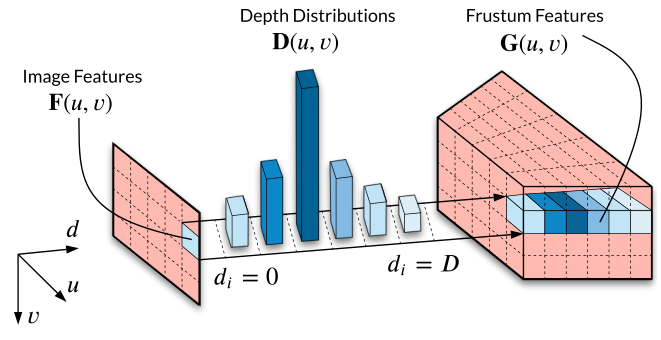
BPU不支持按index的赋值操作,因此公版的bevpool无法原生支持,参考算法版本分别对深度和feature多次grid_sample采样后相乘来替代公版实现。
LSS v2
v1版本是排序后取前10个点,会导致在周围的目标容易丢失
具体为:
Densebev性能优化方案
bevmask操作可以减少无效anchor,提高模型部署效率,动态的bevmask 在J6上无法支持,在优化方案中,我们对内外参生成BevMask的原理做了详细的分析,发现:
当相机传感器位置固定时,内外参转换矩阵即固定,轻微抖动对BevMask影响不大。
从BEV voxel 的角度来看,中心点到multi camera的映射是稀疏的,在BevFormer开源的代码和模型中,默认利用了这个特性,加速计算而不会带来任何精度损失(也就是上面说的bev_mask)
从BEV pillar 的角度来看,通常每个pillar只会映射到1-2个camera。
利用到上面的几个特性我们可以减少空间融合模块的复杂度,但需要引入一对gather/scatter操作,以及相关的index计算(有效点的index只和相机有关,为前处理计算,内外参不变的情况下只需要计算一次)。即先通过gather将bev空间上的有效点取出来,计算完空间特征融合后,再用scatter将其还原到Bev空间对应的位置,然后根据每个bevpillar的有效点数来算Bev空间每个点的均值即可。
整体框架如下图所示:
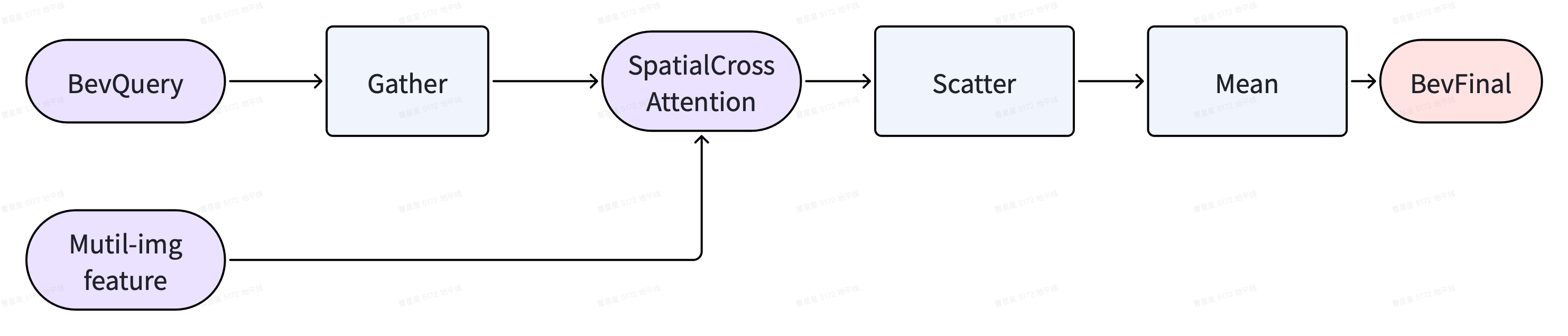
为了能编译成静态模型,有2个额外需要关注的设置:
Bev空间映射到每个camera的最大点数。这个可以根据内外参计算得到,但为了应对一些抖动情况,可以适当放开,在Nuscenes数据集上,50*50大小的Bevsize下,我们设置为20*32。 这个数字直观理解就是,最大视场的相机在Bev空间覆盖的区域大小。
每个BEV pillar映射到的最大的camera数。目前是一个静态设置的最大值,可以根据数据统计得到,在Nuscenes数据集中,我们设定为2, 这个数字直观理解就是有视野重叠的最大camera数。
代码均在算法包位置:
hat/models/task_modules/bevformer/attention.py
BEV坐标转换量化攻略
坐标转换是将3d的点映射到2d 图像上,输入为3d坐标和转换矩阵,输出为2d点坐标,主要的做法为3d坐标和转换矩阵的点积,然后转为2D平面坐标。
易产生量化误差的操作为:
3d点和homo矩阵的matmul操作,精度不够会对结果产生直接影响
将(x,y)/z,若z非常小则会导致x,y坐标数值很大,对量化不利
对于1:
对matmul拆分,使保证高精度(或在新模版中使用双int16)
对于2:
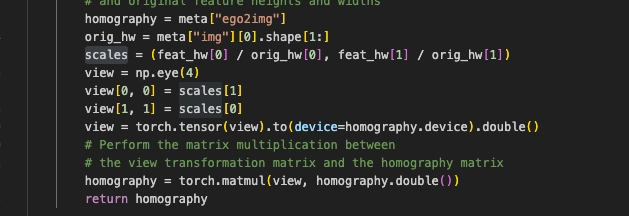
对z做clamp,由于该坐标是用于gridsample采点,若为无效点(坐标大于featuremap)则可以在前面做clamp去除,避免无效值对量化的影响。可以参考:

将缩放操作提前,即将坐标点在前部分就缩小,操作将div放在homo计算中,将缩放直接放在矩阵中,无需在模型中做。(经验上越大的scale,转定点后掉点的风险越大,去除无效数值避免较大的scale),参考:
Sparse bev部署攻略
性能优化
一阶段生成的featuremap只使用FPN的单层特征。
根据场景适当减少anchor num、decoder layer、num_head,对浮点精度影响较小的配置。
对模型中的update模块的topk运算若对性能影响较大则考虑去除,对浮点的影响视具体模型而定,若影响较大可以尝试使用memory bank找回。目前已支持spu的topk实现。
使用henet替换Resnet50。
精度优化
- 计算2d点时(depth = self.reciprocal_op(torch.clamp(points_2d[..., 2:3], min=1e-5))),可以根据实际情况限制最小值避免出现极大的x,y坐标(实际极大的坐标为无效值),对QAT量化不友好。
对homo做缩放,避免在坐标转换时出现matmul数值过大出现量化问题。
- anchor_project计算时为避免很大的timestamp差异(对量化不友好),可使用以下方式:
若BPU执行则可以增加过滤
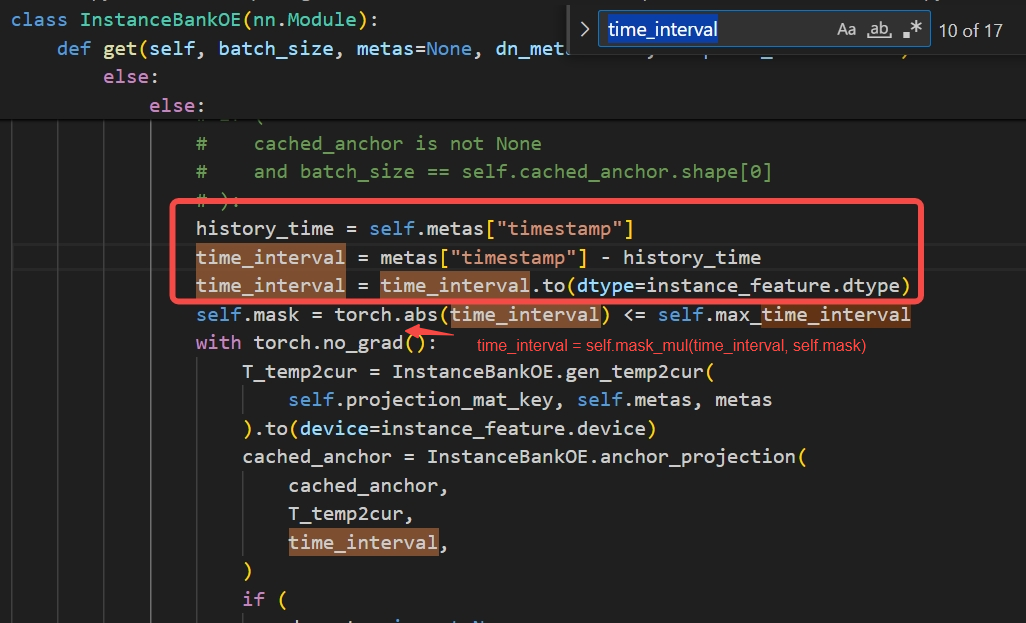
若BPU执行则量化配置时可以通过对算子配置threshold(数值为有效值范围的最大值)来实现对离群点的过滤。
CPU执行,对anchor_project过程不做量化(板端CPU计算后作为模型输入)
gen_cached_data为时序的anchor_projection计算,计算完后再做QuantStub量化。
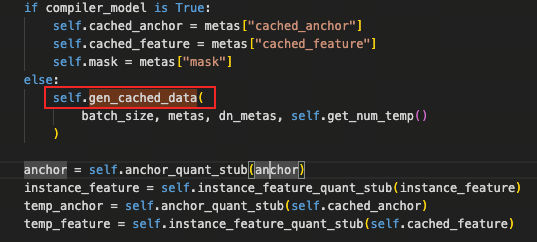
project_mat的matmul计算若有精度可以做拆分或者使用双int16量化。
若坐标处理中有放大值域的计算,善于使用clamp,例如将红色部分换成上面注释的部分,将clamp的min增大,对x,y可以避免出现极值,更有利于量化。
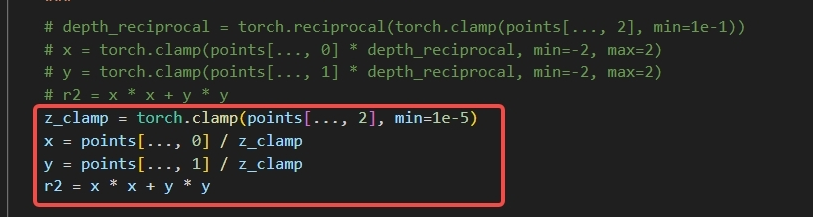
对于具有物理意义相关的数据可以自己限制范围,控制值域,更有利于量化。
对于该示例,生成的grid坐标会在图像的featuremap中取值,存在能取到值的有效点和取不到值(超过图像表示范围:±tan(fov/2))的无效点。因此,若x,y的值很大的话是取不到有效值的,所以对超出范围的无效点做处理不会影响浮点模型精度且对量化更友好。由计算可知x和y的最终坐标需要/z映射到2D图像,若z非常小会导致x,y很大,因此可以在z上做clamp使x,y的分布更均匀且不会影响物理范围。
对sparse4d部署更详细的见文章:https://developer.horizon.auto/blog/12622

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)