
1. VLA简介
1.1 VLA定义
VLA (Vision Language Action)是一种多模态机器学习模型,结合了视觉、语言和动作三种能力,旨在实现从感知输入直接映射到控制动作的完整闭环能力。VLA强调一体化多模态端到端架构,非感知规控的模块化方案。
下图是常见端到端的框架,是RT-2、OpenVLA、CLIP-RT等 VLA 系统的典型代表,这些系统均采用基于 Transformer 的视觉和语言骨干网络,并通过跨模态注意力机制进行融合。
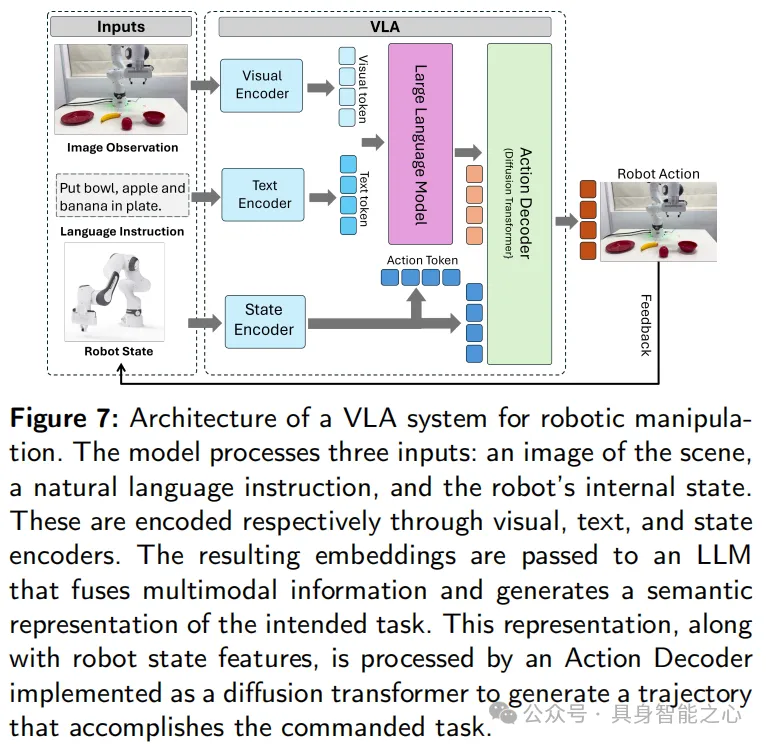
该架构融合视觉、语言和本体感受三类编码器,视觉编码器(如ViT、DINOv2)提取图像特征,语言编码器(如PaLM、LLaMA)将自然语言指令嵌入相同空间,状态编码器则将机器人感知与运动状态编码为辅助tokens,支持可达性推理与反馈调整。
所有tokens拼接后送入Transformer,可通过扩散策略(如Diffusion Policy)或直接映射策略得到控制命令。输出可为连续动作信号(如执行器速度)。
1.2 VLA典型结构
VLA模型典型结构如下,围绕视觉编码器、语言编码器和动作解码器三个关联模块构建
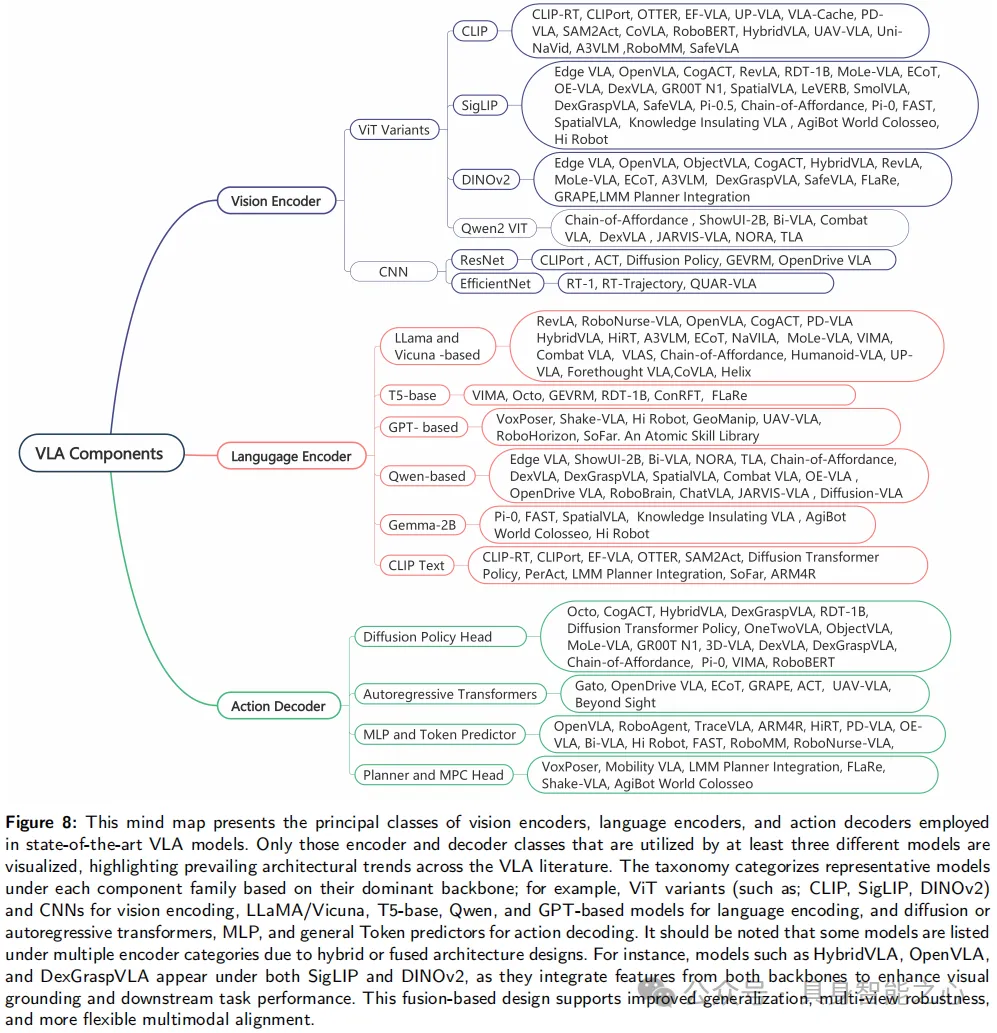
视觉编码器中:
基于 CLIP 和 SigLIP 的编码器因对比学习带来的强视觉文本对齐能力受青睐,应用于 CLIPort 等模型;
DINOv2、Qwen2 VIT 等 ViT 变体因能建模长距离空间依赖和高级视觉语义,应用于 HybridVLA等模型;
ResNet、EfficientNet 等基于 CNN 的编码器则出现在 CLIPort、ACT、RT-1、QUAR-VLA 等模型中;
语言编码器:
LLaMA 和 Vicuna 系列用于 RevLA、OpenVLA 等模型,支持指令理解和零样本推理;
T5 风格模型应用于 VIMA、Octo 等,提供灵活的编码器 - 解码器结构;
GPT 和 Qwen 系列在 VoxPoser 等模型中平衡泛化能力与紧凑部署;
Gemma-2B 用于 Pi-0、FAST;
CLIP 文本编码器则在 CLIPort 等中完成基础对齐任务;
动作解码器:
基于扩散的 Transformer 是 Octo 等模型首选,通过迭代去噪实现细粒度、平滑控制;
自回归 Transformer 头在 Gato 等中逐步生成动作序列,优化实时响应;
VoxPoser 等模型嵌入模型预测控制或规划头支持动态决策;
MLP 或tokens预测器头用于 OpenVLA 等实现高效低级控制;
总结:
视觉编码器多采用 CLIP 和 SigLIP 基于的 ViT 骨干网络;
语言领域以 LLaMA 家族为主;
动作解码中基于扩散的 Transformer 头因建模复杂多模态动作分布能力最受青睐;
2. 智驾场景引入VLA
2.1 智驾VLM的问题
视觉语言模型(VLM)虽然擅长理解复杂场景,但存在以下问题:
空间精度不高:输出轨迹点是基于语言生成的,易产生偏差。
传统端到端模块虽然推理快,但缺乏全局语义理解能力。可以通过一种“慢→快”的协同机制来连接两者,Trajectory Refinement(轨迹优化) 就是这个桥梁。Trajectory Refinement用于提升路径规划的精度与实时性,其本质是使用 DriveVLM(慢系统)输出的粗略轨迹作为参考,引导传统自动驾驶模块(快系统)进行高频率、实时的精细轨迹生成。
端到端快系统 的输入端是以视觉为主的传感器信息,输出端是行驶轨迹。VLM慢系统 的输入端是2D视觉信息、导航信息,输出端是文本而非轨迹(VLM并非端到端神经网络)。
端到端模型和VLM是两个独立的模型,且运行频率不同,做联合训练与优化非常困难。
VLM 在语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
VLM通过叠加多帧的图像信息完成时序建模,会受到 VLM 的 Token 长度限制,会增加额外的计算开销。
2.2 智驾VLA的优势
VLA的输入端是视觉为主的传感器信息、2D视觉信息、3D视觉信息、导航信息、语音指令信息,输出端是文本和行驶轨迹。
VLA视觉-语言-动作 模型与端到端系统,均为(传感输入)端到(控制输出)端神经网络,在神经网络架构上均能实现全程可导。
VLM视觉-语言模型因为其并不直接输出轨迹,导致无法受益于真实数据和生成数据的驱动。
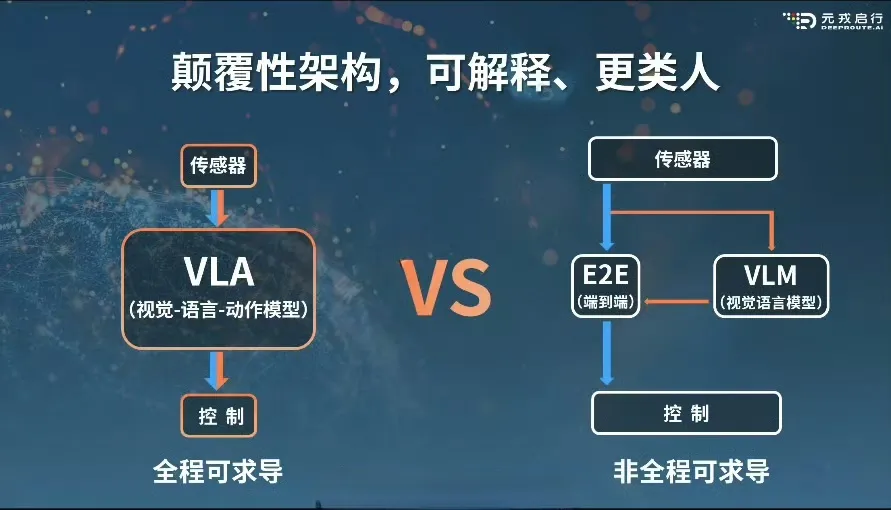
全程可求导和非全程可求导的区别在于,无论是数据驱动的端到端还是知识驱动的VLA,都能高效率、低成本地通过自动化的数据闭环实现驾驶场景数据驱动,而VLM视觉语言模型无法借助数据闭环,实现高效率、低成本的数据驱动。
在算法架构层面,VLA引入了大语言模型,在算法形式层面,VLA保持了从传感输入到轨迹输出的端到端神经网络形式。
3. 智驾中典型VLA架构
3.1 MindVLA:理想
MindVLA整合空间智能、语言智能和行为智能,基于端到端和 VLM 双系统架构,通过 3D 空间编码器和逻辑推理生成合理的驾驶决策(LM),并利用扩散模型优化驾驶轨迹。LLM 基座模型采用 MoE 混合专家架构和稀疏注意力技术。
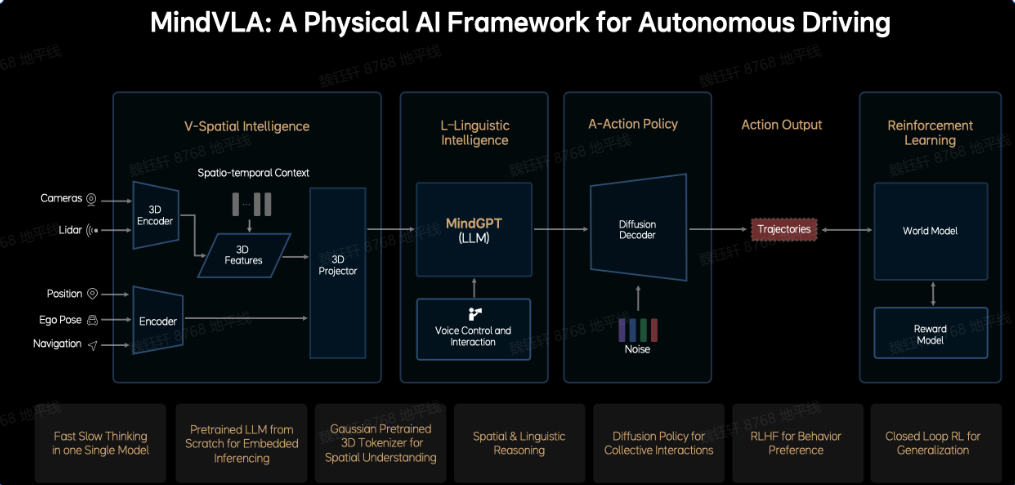
V空间智能模块:输入为多模态传感器数据,使用3D 编码器提取时空特征,然后将所有传感器与语义信息融合成统一的特征。
L语言智能模块:大语言模型MindGPT,用于空间 + 语言的联合推理,支持语音指令和反馈,可实现人车交互。
A动作策略模块:使用扩散模型生成车辆未来轨迹,引入噪声来引导扩散过程,从而生成多样化的动作规划。
强化学习模块:使用World Model模拟外部环境响应,评估行为后果;使用奖励模型(Reward Model)提供驾驶偏好,将人类驾驶偏好转化为奖励函数(RLHF)。
3.2 ORION:华科&小米
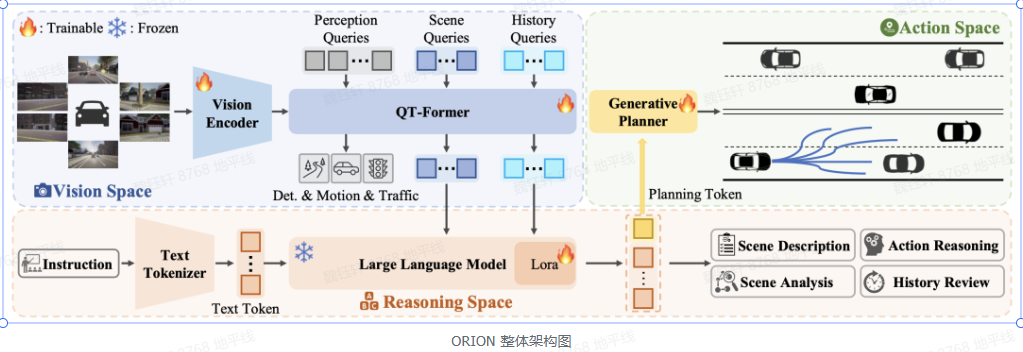
通过视觉语言指令指导轨迹生成的端到端自动驾驶框架。ORION 引入了 QT-Former 用于聚合长期历史上下文信息,VLM 用于驾驶场景理解和推理,并启发式地利用生成模型对齐了推理空间与动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。
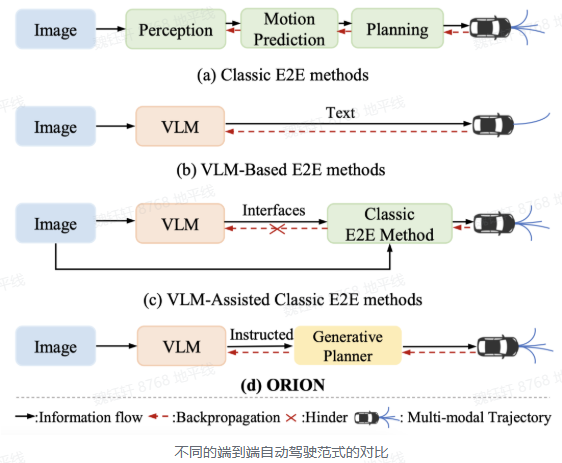
VLM:结合用户指令、长时和当前的视觉信息,能够对驾驶场景进行多维度分析,包括场景描述、关键物体行为分析、历史信息回顾和动作推理,并且利用自回归特性聚合整个场景信息以生成规划 token,用来指导生成模型进行轨迹预测。
生成模型:通过生成模型,将 VLM 的推理空间与预测轨迹的动作空间对齐。生成模型使用变分自编码器(VAE)或扩散模型,以规划 token 作为条件去控制多模态轨迹的生成,确保模型在复杂场景中做出合理的驾驶决策。生成模型弥补了 VLM 的推理空间与轨迹的动作空间之间的差距。
QT-Former:通过引入历史查询和记忆库,有效聚合长时视觉上下文信息,增强了模型对历史场景的理解能力,聚合历史场景信息,使模型能够将历史信息整合到当前推理和动作空间中。可以减少计算开销,还能更好地捕捉静态交通元素和动态物体的运动状态。
4. 参考链接
https://developer.horizon.auto/blog/13051
https://developer.horizon.auto/blog/12961
https://mp.weixin.qq.com/s/j3DYoYfkp0yrNlO9oR2tgA
https://zhuanlan.zhihu.com/p/1888994290799195699
https://mp.weixin.qq.com/s/nP70QtcVLjgLq8Ue95BdJw
https://mp.weixin.qq.com/s/j3DYoYfkp0yrNlO9oR2tgA
https://mp.weixin.qq.com/s/PR_RFtbEfOV2L0cQXg574A
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)