
1. 前言
本文旨在提供 J6H/P 计算平台的部署指南,将会从硬件、软件两部分进行介绍,本文整理了我们推荐的使用流程,和大家可能会用到的一些工具特性,以便于您更好地理解工具链。某个工具具体详l细的使用说明,还请参考用户手册。
2.J6H/P硬件配置
2.1 BPU®Nash
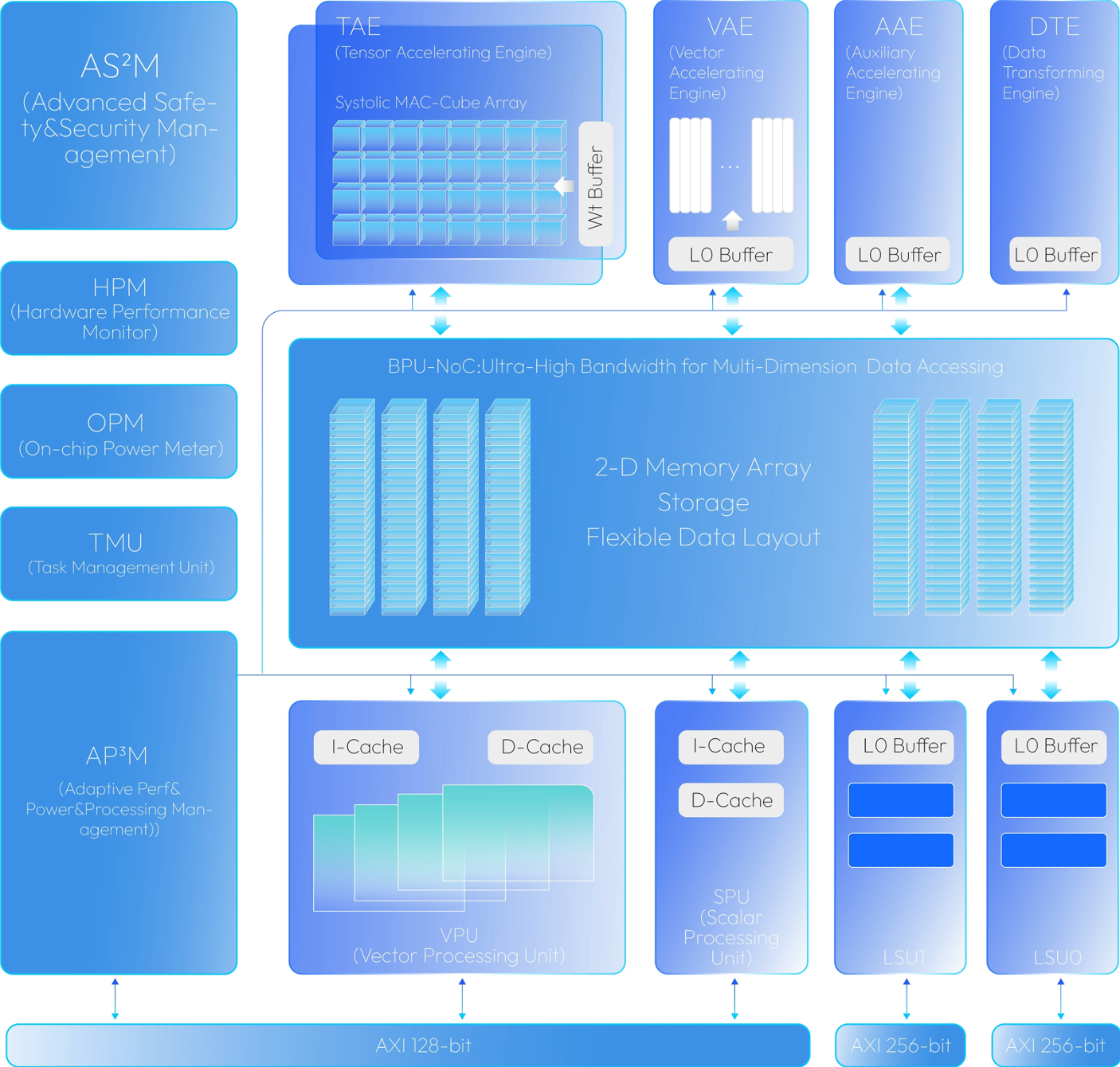
2. 2 硬件规格
| BPU | DSP
| |||||
|---|---|---|---|---|---|---|---|
| 算力 | TAE浮点输出 | VAE浮点 | VPU | SPU | APM |
|
J6E | 80T | N | N | Y | Y | Y | Q8*1 |
J6M | 128T | N | N | Y | Y | Y | Q8*1 |
J6P | 560T | Y | Y | Y | Y | Y | Q8*2 |
J6H | 420T | Y | Y | Y | Y | Y | Q8*2 |
J6B-Base | 18T | Y | Y | N | N | Y | V130*1 |
BPU内部器件:
- TAE:BPU 内部的张量加速引擎,主要用于 Conv、MatMul、Linear 等 Gemm 类算子加速
- VAE:BPU 内部的 SIMD 向量加速引擎,主要用于完成vector计算
- VPU:BPU 内部的 SIMT 向量加速单元,主要用于完成vector计算
- SPU:BPU 内部的 RISC-V 标量加速单元,主要用于实现 TopK 等算子
- APM:BPU 内部另一块 RISC-V 标量加速单元,主要用于 BPU 任务调度等功能
- L1M:一级缓存,BPU核内共享
- L2M:二级缓存,BPU核间共享
2.3 与其他J6计算平台的主要区别
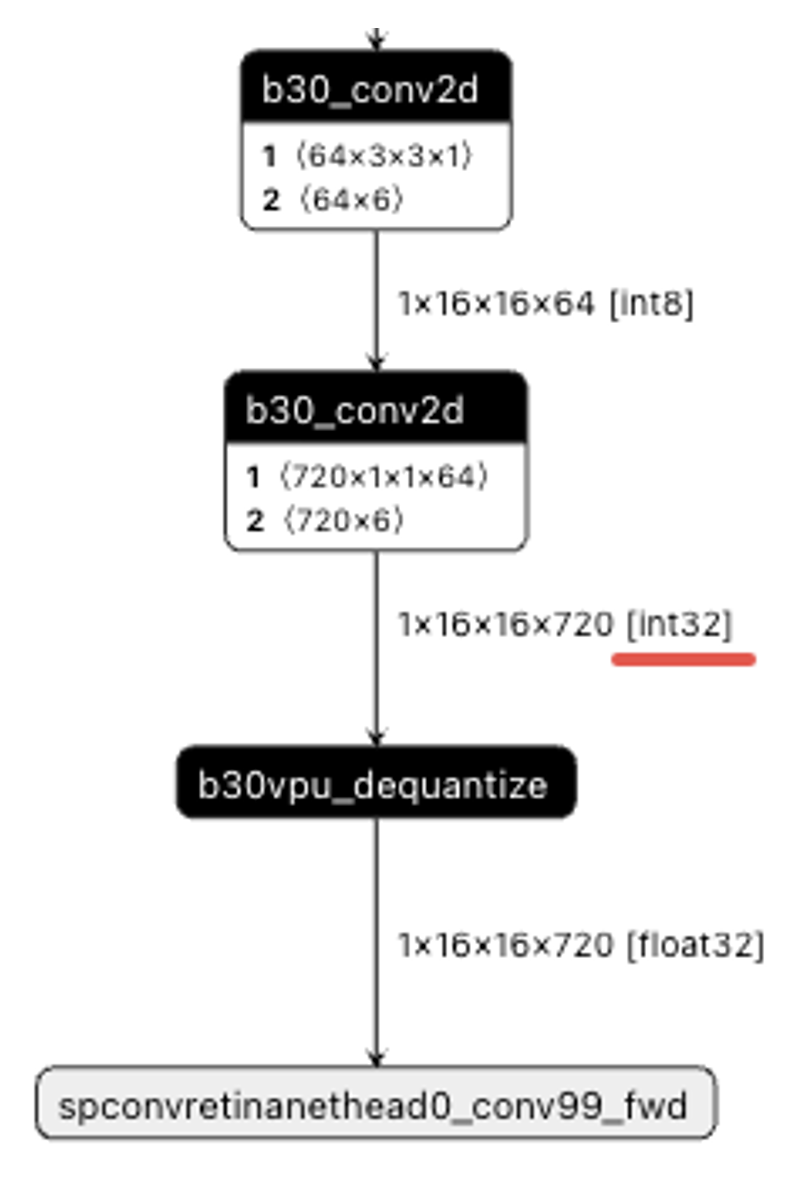
J6E/M尾部高精度conv输出int32:
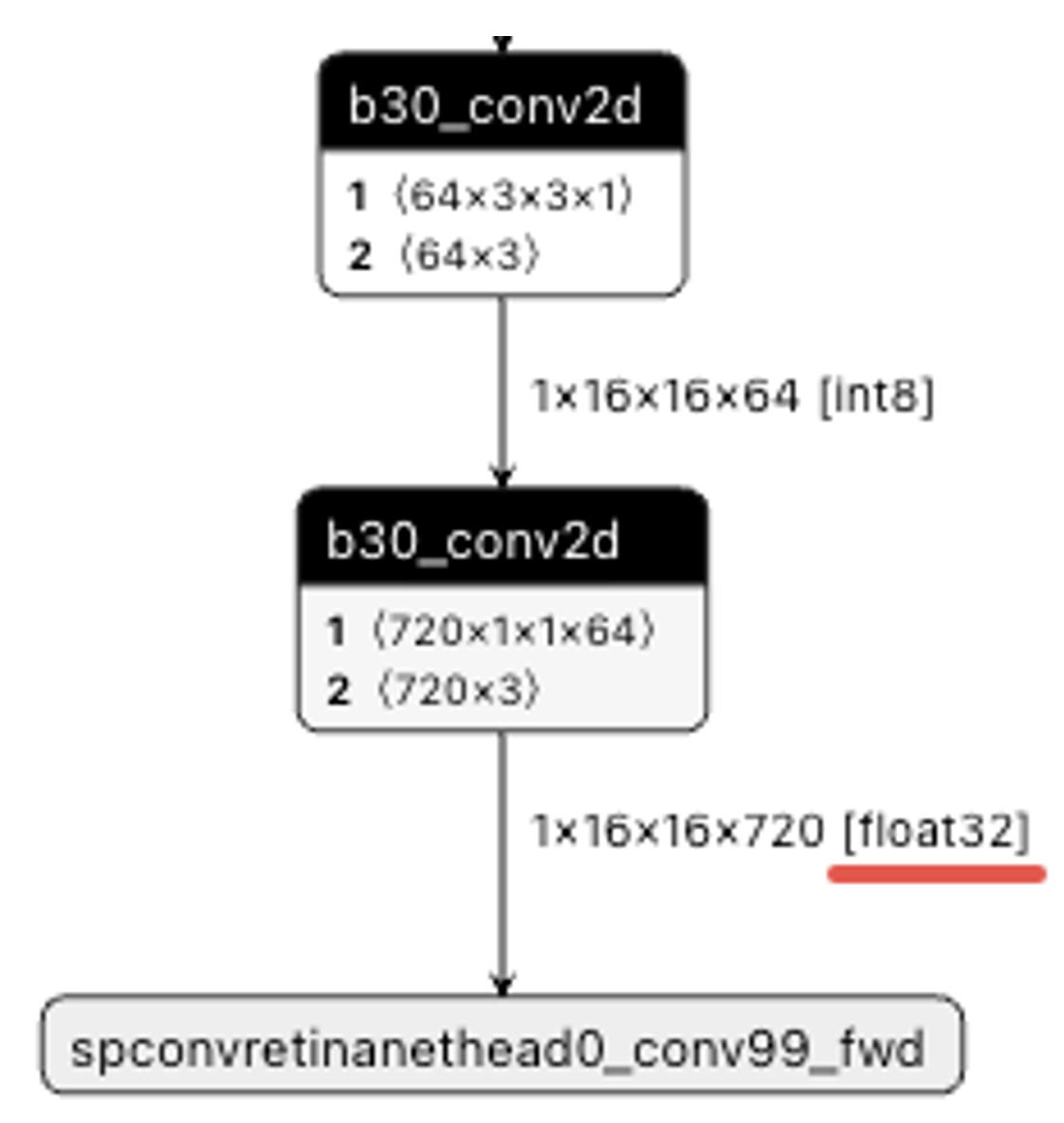
J6B/H/P尾部高精度conv输出float32:
| TAE | VAE | VPU |
J6E/M | 输出支持:int8,int16,int32 | 支持int8,int16 | 较少的fp16算子支持 |
J6H/P | 输出支持:int8,int16,int32,fp16,fp32 | 支持int8,int16,fp16 | 能力增强,支持较多fp16和fp32算子 |
J6B | 输出支持:int8,int16,int32,fp16,fp32 | 支持int8,int16,fp16 | 没有VPU |
针对nv12输入,金字塔配置文件需要注意修改stride参数,如果J6E/M/B内存够的话,建议可直接按64对齐来申请,跨平台迁移时就无需更改配置。
3. 新功能特性
若已有其他平台使用经验,可只关注本章节内容,了解J6H&P与其他J6计算平台的功能点差异即可。
相较于J6E/M/B,J6H/P最主要区别是多核,TAE/VAE/VPU器件能力的增强以及增加了L2M,本章节将介绍这几点差异对于在J6H/P平台上开发算法方案的影响。
3.1 多核部署
3.1.1 多核模型编译
J6H/P硬件支持单帧多核的部署方式,但是当前多核模型(特指单次模型推理同时使用了两个及两个以上 BPU核心的模型)功能还在开发中,目前支持了resnet50 双核模型的demo,性能数据见下表:
| 单核模型实测延时(ms) | 双核模型实测延时(ms) |
|---|---|---|
Resnet50 | 9.1187 | 5.7458 |
由于BPU是独占式硬件,若运行双核模型,则代表该模型运行期间,有两个bpu会被同时占用,无法运行其他任务;加上多核模型相较于单核能拿到的性能收益与模型结构紧密相关,很难确保理想的双核利用率。因此出于更高的跨平台迁移效率和硬件资源利用率等因素考虑,建议按下一节建议拆分模型部署。
3.1.2 pipeline设计
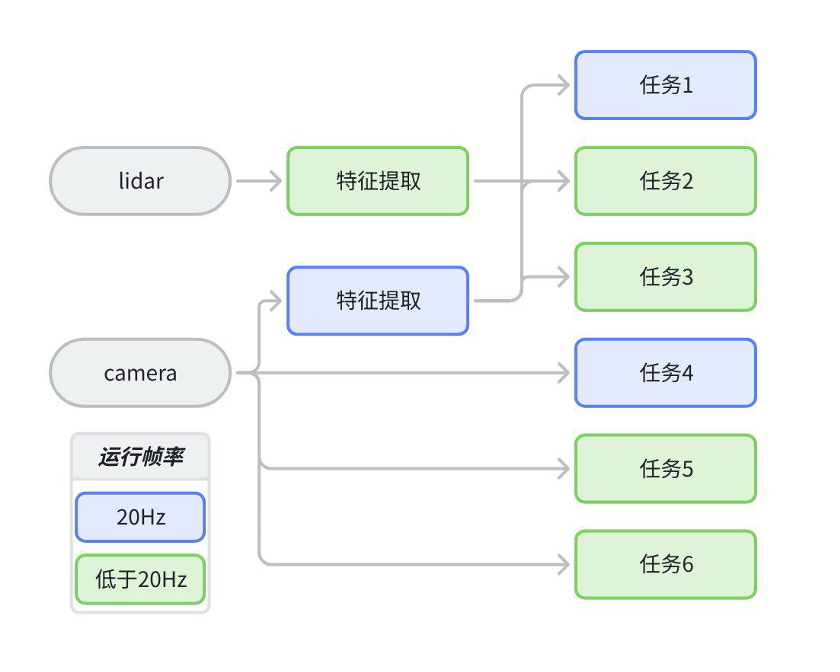
J6H/P分别提供了3个和4个BPU计算核心,给了应用调度更灵活的设计空间,通过多核充分并行,可有效减少系统端到端延时。以下方案仅为示例,并非是标准推荐:
算法架构示意图:
部署pipeline设计:

由于工具难以感知模型上下游关系,任务重要程度,不同设计帧率等信息,且多核模型利用率提升难度很大,因此建议用户手动拆分不同功能的模型以提高多核计算资源的利用率。拆分逻辑有如下建议:
- 多任务帧率不同:智驾系统中各个子任务设计帧率可能是不同的,建议拆分部署。
- 无上下游依赖:两个没有上下游输入输出数据依赖的模型,建议拆分部署,编译在一起也是顺次执行的。拆分后通过放在不同核心上部署,可以缩短整体系统的端到端延时。
- 跨团队开发,提前做资源分配:算法功能开发团队约定算力分配后可独立开发优化,独立上线测试,若编译在一起则每次发版都会有相互依赖。
3.2 合理使用L2M
由于J6H/P算法方案相对会比J6E/M/B的复杂,包括接入的摄像头数目,模型前后处理和模型体量变大都会导致整个系统对带宽的需求要高很多。由于带宽争抢,不可避免当多核同时运行时会发现模型延时相较于独占硬件测试时会变长。为了缓解带宽争抢导致模型延时变长的现象,J6H/P提供了L2M,可使部分与DDR交换的数据被缓存在L2M内。建议在大部分模型都产出hbm后,甚至pipeline大致确定之后,使用如下方式离线评估所有模型的带宽资源使用情况,测试不同l2配置的带宽收益。
3.2.1 L2M使用说明
需要更新到OE3.5.0及以上)。当前仅支持以BPU核为粒度配置L2大小,暂不支持运行时实时对单模型做配置。启用L2M涉及到模型编译,以及运行时正确制定环境变量两项工作。
3.2.1.1 模型编译
编译时通过指定参数控制模型可用的l2大小:
3.2.1.2 模型推理
无需改动推理代码,只需通过环境变量控制每个核可申请的l2大小(暂不支持运行时动态申请)
建议部署在相同BPU核上的模型,编译时指定相同的L2M大小,否则需要按最大需求来配置。
不正确的L2M使用可能导致如下问题:
未给对应核分配足够的L2M或是没有分配L2M
推理将会失败,打印如下提示日志信息:
比如模型编译时指定了12M L2M,运行时只通过环境变量给该核分配了6M;或是运行时忘记配置环境变量。
发现没有带宽收益,或者推理结果错乱
老版本ucp也能推理带l2的模型,只不过会出现推理结果不正确,并且没有带宽收益的问题,请从日志里确认ucp的版本已经升级到OE3.5.0及以上集成的版本。
3.2.2 统计并优化系统带宽
由于目前hbm_perf暂不支持L2M(perf看不出l2m的收益,预计260215版本可支持),因此具体收益需要通过实测获取。按照经验,实测与预估偏差非常小(10%以内),通过预估方式如果发现四个核带宽占用差不多,可以直接每个核平分l2,如果核0和核3的带宽占用最为显著,可以直接将l2平均分给两个核的模型。
3.2.2.1 按实车pipeline设计预估平均带宽的方式
首先使用hbm_perf评测模型,从html或json中获取带宽信息,结合设计帧率评估模型上线后预计需要的带宽资源:
平均带宽(GB/s) = DDR bytes per second( for n FPS) / n * 设计帧率/2^30
以下面这个模型为例,实车设计帧率为10FPS,则实车时该模型需要的平均带宽为:
68138917200/10.39*10/2^30 = 61.08GB/s

3.2.2.2 按实车pipeline实测平均带宽的方式
修改hrt_model_exec工具,支持按设计帧率perf模型(如何修改工具,以及带宽数据如何分析请参考社区文章:https://developer.horizon.auto/blog/13054)
找一个空闲的开发板,用hrt_model_exec工具按设计帧率perf模型:
使用hrut_ddr获取bpu占用的平均带宽
3.3 量化配置
3.4 部署差异
3.4.1 模型输出精度可能不同
由于J6B/H/P的TAE硬件支持fp16和fp32输出而J6E/M不支持,因此若模型以GEMM类算子结尾的话,J6E/M 配置高精度输出是int32,J6B/H/P 配置高精度输出是fp32。因此J6E/M 模型直接编译到J6B/H/P,模型输出类型有可能会发生改变,软件代码需要注意适配。
3.4.2 跨距对齐要求不同
J6H/P要求nv12 stride满足64对齐,J6E/M/B是32对齐。且输入输出tensor的对齐规则也有可能不同。
从J6E/M/B迁移J6H/P需要注意金字塔配置文件的stride是否满足64对齐,如果J6E/M/B内存够用的话,建议可直接按64对齐来申请,跨平台迁移时就无需更改配置。
3.4.3 最小内存单元不同
J6H/P tensor最小申请内存是256字节,J6E/M 64字节,J6B 128字节。这个差异会体现在模型的aligned byte size属性上,对于小于最小内存单元的数据,或者不满足最小内存单元整数倍的数据,会要求强制对齐。建议输入输出tensor内存大小按aligned byte size申请,不要写hard code,避免迁移时遇到问题。

3.4.4 绑核推理
J6H/P有两个dsp核,提交dsp任务时可以指定一下backend
J6H/P有三/四个bpu核,建议所有任务做静态编排后,运行时做绑核(不建议使用HB_UCP_BPU_CORE_ANY,会因系统调用导致latency 跳变),减少使用抢占等会产生额外ddr开销的功能:
J6H/P单核内支持的抢占策略与J6E/M一致,多核已经为编排提供了足够的灵活度,建议多核计算平台上尽量避免使用硬件抢占,减少抢占引入的额外带宽消耗。
4. 建议使用流程

在J6计算平台上,我们建议前期初步做性能评测和性能优化时使用PTQ工具,只需要准备浮点onnx即可,较易上手。后续正式做量产迭代使用QAT量化工具,精度更有保障,对于多阶段模型,或者模型新增head等变化,可以更灵活复用已有QAT权重,有利于模型迭代更新,而PTQ则无法拼接历史量化onnx。下图为PTQ和QAT量化产物对比:
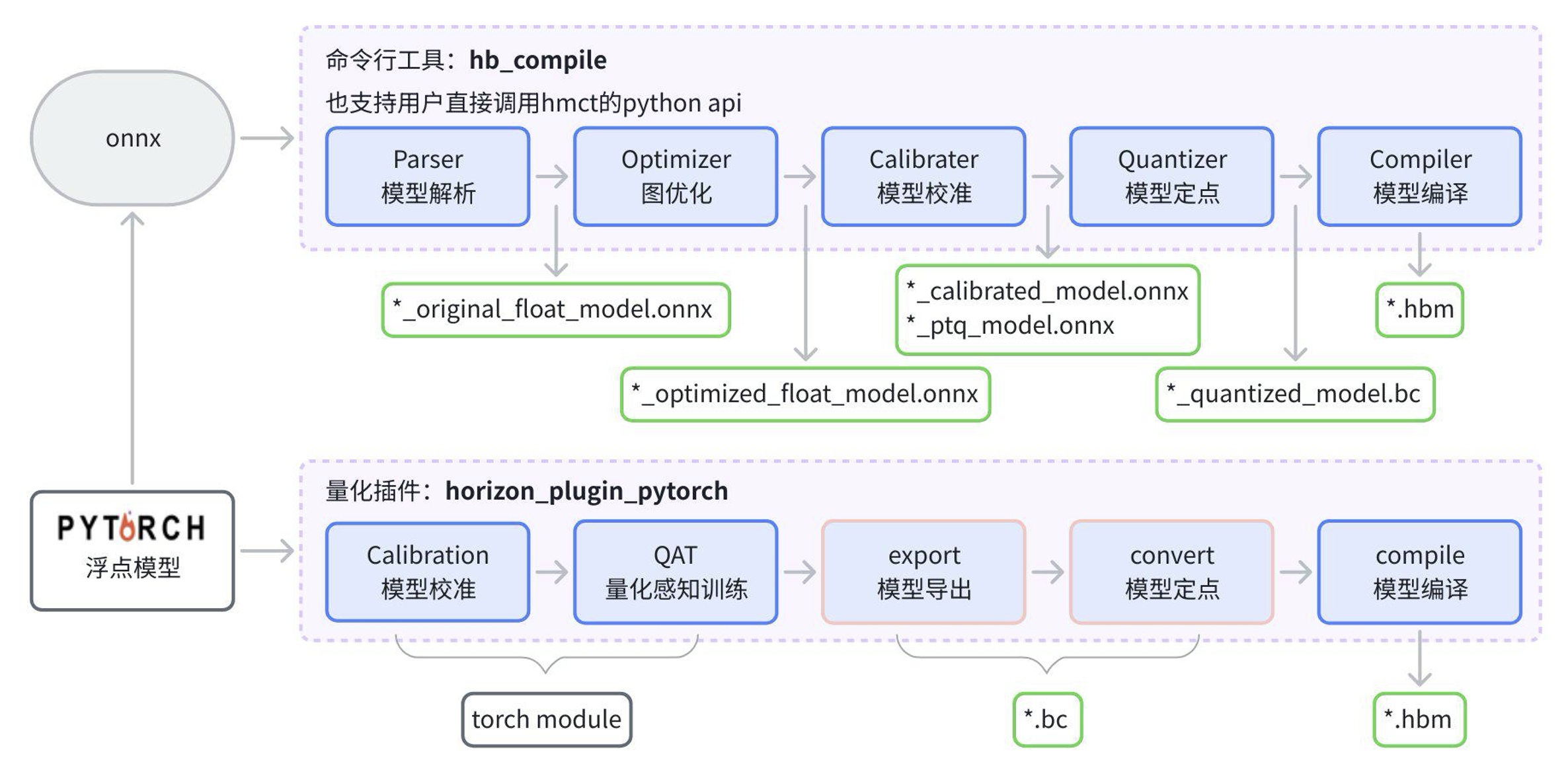
4.1 性能评测
PTQ环境搭建请参考用户手册-环境部署-Docker容器部署。
4.1.1 快速性能评测(默认全Int8)
需要注意的是,fast-perf默认会删除模型前后的Quantize,Transpose,Dequantize,Cast,Reshape,Softmax算子,如果模型输入输出节点较多,会与实际部署性能产生gap,建议按下面的步骤,手动修改一下yaml文件:
执行上面那一行命令之后会在当前路径下生成.fast_perf路径,路径下有yaml文件,打开yaml文件按照实际部署需要,去掉无需删除的节点,一般来说部署时只需要删除量化反量化:

修改完成后只要模型输入没有变化,则后续可一直复用该yaml文件,修改onnx_model路径即可:
4.1.2 int8_fp16测试
先生成模版:hb_compile --fast-perf --model xxx.onnx --march nash-p,默认生成在.fast_perf/隐藏目录下
修改config:
编译:hb_compile --config temp.yaml
评测其他精度,如全int16,softmax/layernorm fp16等,修改上面的fp16.json文件即可,配置方式详细说明请参考用户手册 - 训练后量化(PTQ)- quant_config说明。
4.1.3 板端模型性能测试工具
进入OE包目录:samples/ucp_tutorial/tools/hrt_model_exec,编译:
将结果文件夹中的output_shared_J6_aarch64/aarch64/bin/hrt_model_exec以及output_shared_J6_aarch64/aarch64/lib拷贝到板端的{path}下。
新建/修改setup.sh文件:
- 执行source setup.sh,就可在板子上使用hrt_model_exec文件了
评测模型延时常用命令:
4.2 性能分析及优化
相较于J6E/M,J6H/P额外需要考虑的是引入了FP计算耗时以及多核的带宽争抢。
与平台无关,早期评测时建议参考上一章获取模型性能情况,后续量产过程中进行精度调试之前也建议先测试一下性能,并完成性能优化(部分性能优化策略可能数学不等价,导致需要重训浮点或qat)。性能分析和优化建议参考如下步骤:
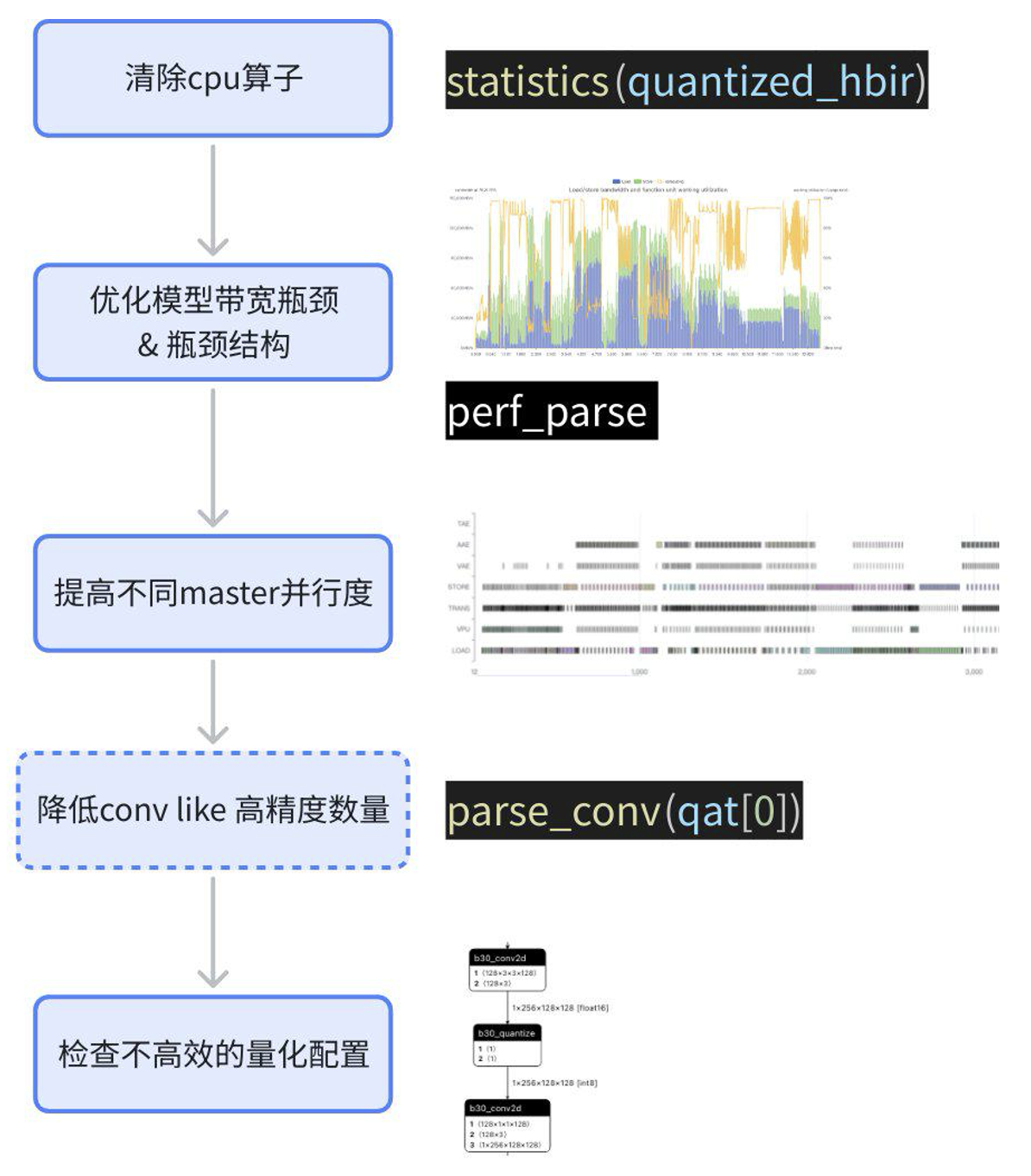
具体分析和优化过程请见《J6 性能分析带宽优化》。
4.3 量化训练
整个量化训练的过程,大致为如下流程:
改造浮点模型:在输入的地方插入QuantStub,输出插入DequantStub,标记模型需要量化的结构;
calibration一个step后导出qat.bc,确认结构是否完整,是否有多余的结构,是否有不符合预期的cpu节点;
配置GEMM双int16+其他float16 做calibraion,调整训练参数,fix scale等直至无限接近浮点。若精度崩掉则先排查流程问题;精度达标的情况下,若延时也满足预期,则量化训练结束;
配置GEMM双int8+其他float16 做calibraion,精度不达标的话进入精度debug的流程;若精度达标则量化训练结束;
calibration精度达到浮点95%以上,还想继续提升精度的话,可以进行qat训练;个别模型calibration精度较低,可通过qat训练得到较大提升;
测试quantized.bc或者hbm精度确认是否达标。
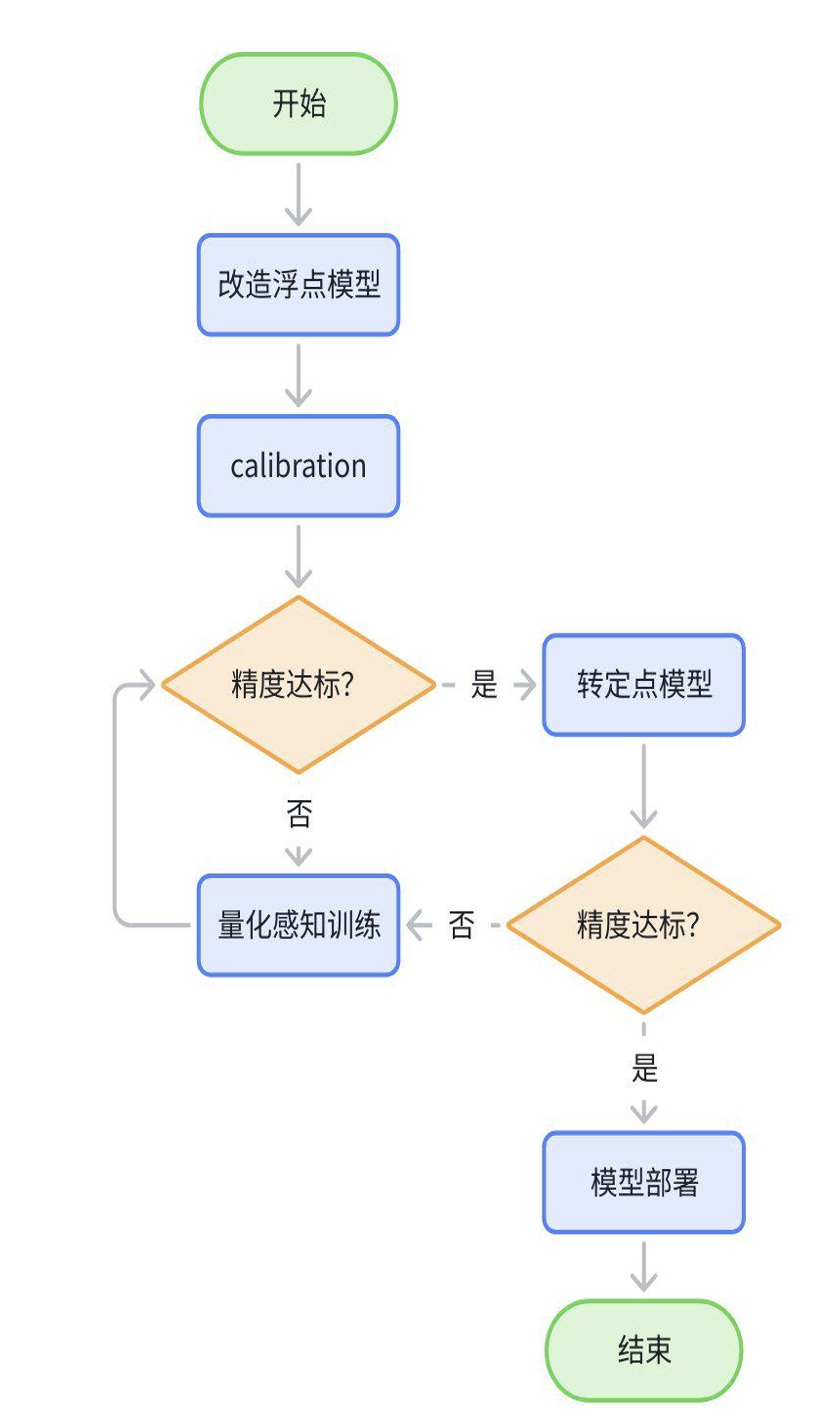
需要注意的是导出qat.bc模型时,建议指定一下模型输入输出节点名称以及模型名字,便于应用集成和后续trace分析,也避免hbm精度评测时同时加载多个名字相同的模型出错。

4.3.2 典型量化配置
4.3.2.1 基础模版(GEMM双int8+其他float16 )
4.3.2.2 添加fix scale(pyramid和resizer输入请关注)
部署时模型输入来源为pyramid和resizer的模型,需要输入节点量化精度配置为int8类型,另外这类输入一般是经过归一化的,数值范围在[-1,1]或者[0,1],因此建议可以直接设置fix scale。
此外还有一些模型中的节点有明确物理含义,建议也手动配置fix scale,避免qat过程滑动取平均导致部分有效值域不完整。
4.3.2.3 通过敏感度增加高精度配置
4.3.2.4 多阶段模型量化配置
若多阶段模型在浮点训练时就是分开训的,则qat保持和浮点节点一致分为多阶段训练。第一阶段按照前面的配置正常calib就好(不要qat,除非calib精度实在是达标不了,qat之后权重变了,二阶段需要finetune浮点),二阶段使用如下方式,将一阶段设置成浮点,仅量化二阶段:
若想要一阶段和二阶段连接部分的scale相同,则qat阶段不要在两阶段连接部分加量化反量化,仅在导出模型时添加:
两阶段分别calibration完之后,使用如下脚本拼接得到完整的calibration权重,使用该权重完成后续的qat训练,若还有第三阶段,需要基于二阶段qat权重finetune浮点:
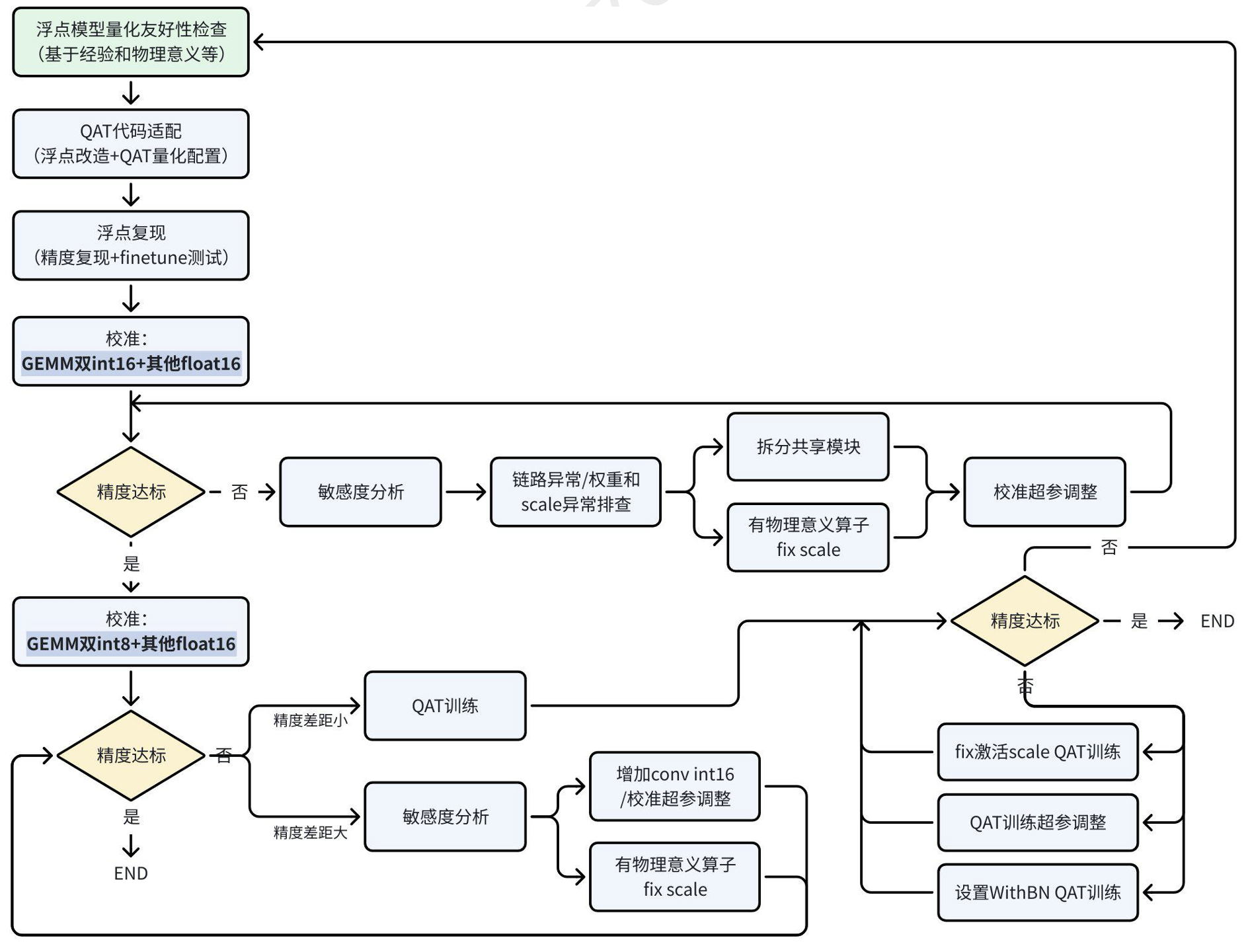
4.3.3 精度调优流程
由于J6H/P上大多数vector计算,int16精度和float16精度计算速度相当,因此建议vector计算精度直接使用float16,可有效减小量化调优的难度,提升迭代效率。若在其他平台上有全int8部署经验,或依据经验判断模型全int8(或加少量int16)无精度风险,为追求极致帧率,可不使用float16。如下为J6H/P的量化调优建议流程:
4.3.4 部署模型编译
由于模型输入输出格式训练和部署时可能存在区别,因此工具链提供了一些api用于在量化训练后调整模型以适配部署要求。差异主要是在图像输入格式,以及是否需要删除首尾量化反量化节点这两个方面。
4.3.4.1 pyramid或resizer输入
该操作请在 convert 前完成,且qat训练时对应输入节点的quant需要是int8量化。下图为训练和部署编译时模型输入的差异:
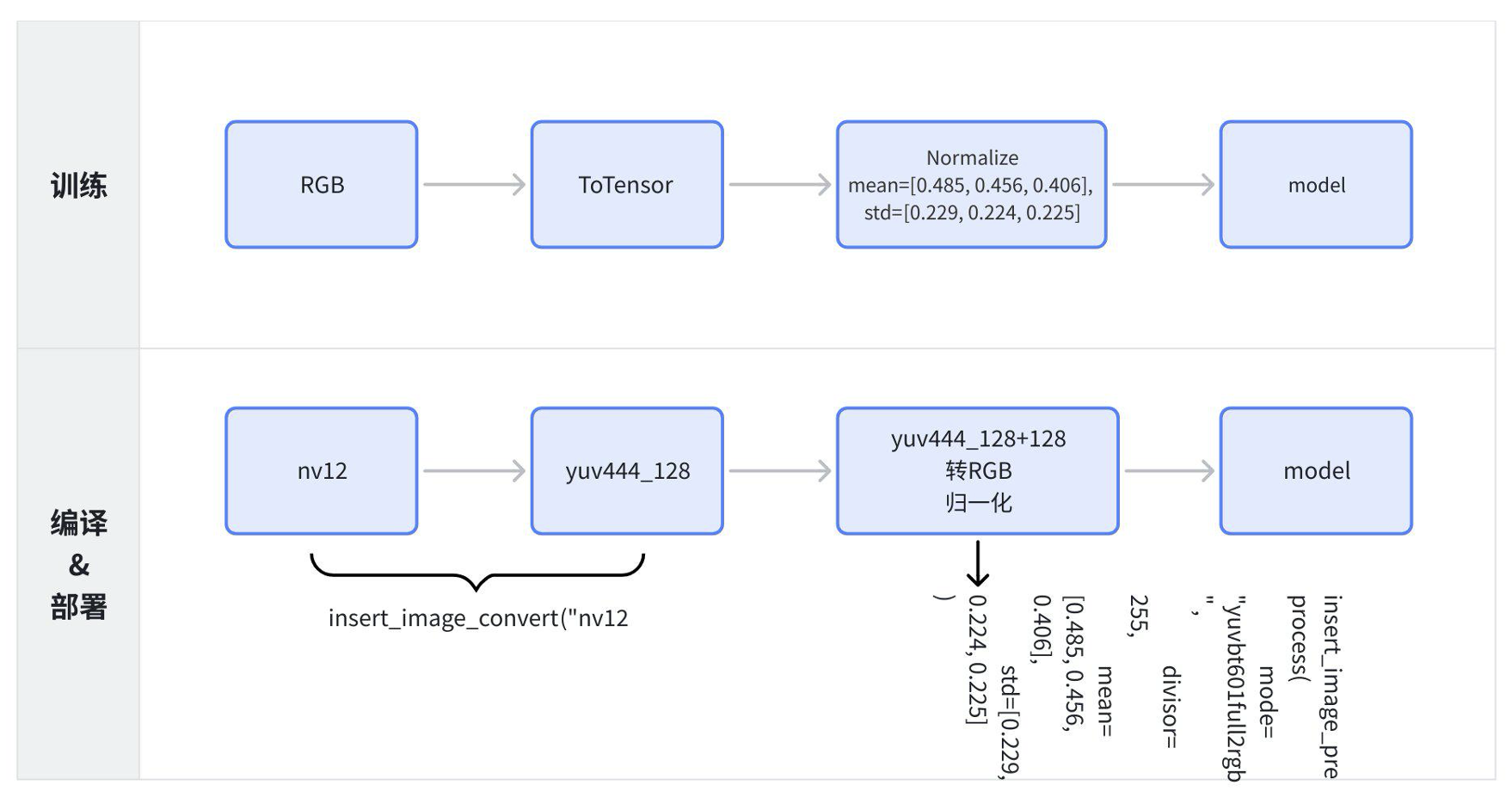
将如下代码加到编译生成hbm的流程中,只需指定需要修改为pyramid/resizer的节点名字即可(注意type为训练时候的数据格式,mean和std也需要结合训练前处理代码做配置)
- mode,可选值包含:
- "yuvbt601full2rgb" YUVBT601Full 转 RGB (默认)
- "yuvbt601full2bgr" YUVBT601Full 转 BGR
- "yuvbt601video2rgb" YUVBT601Video 转 RGB 模式
- "yuvbt601video2bgr" YUVBT601Video 转 BGR 模式
- "bgr2rgb" BGR转RGB
- "rgb2bgr" RGB 转 BGR
- "none" 不进行图像格式的转换,仅进行 preprocess 处理
- 数据转换除数divisor,int 类型,默认为 255
- 均值mean,double 类型,长度与输入c方向对齐,默认为 [0.485, 0.456, 0.406]
- 标准差值std,double 类型,长度与输入c方向对齐,默认为 [0.229, 0.224, 0.225]
4.3.4.2 算子删除
该操作需要在 convert 后完成,因为 convert 前模型都还是浮点输入输出,没有生成量化反量化节点:
若进行了删除动作,需要在后处理中根据业务需要进行功能补全,例如实现量化、反量化的逻辑。
量化计算参考代码:
如果并不想去掉模型所有的量化反量化,只想删掉个别输入输出节点相连的op,可采用下面的方法删除与某输入/输出节点直接相连的节点:
4.3.5 定点模型精度评测
由于qat还是伪量化模型,从伪量化转换真正的定点模型有可能会产生误差,因此建议模型上线之前除了测试qat torch module精度之外,再测试一下定点模型的精度。定点模型精度可以基于quantized.bc或者.hbm做测试,quantized.bc和hbm在模型中无cpu算子,无fp32精度算子的情况下,模型输出是二进制一致的。
4.3.5.1 quantized.bc推理
python
quantized.bc推理输入格式为dict,支持tensor和np.array,输出格式与输入一致。当前只支持cpu推理,建议通过多进程加速推理过程。
C++
与推理hbm接口使用无任何区别,便于用户在x86端测试系统集成效果,具体使用方式请参考后文第五章,.so替换成x86的即可。
4.3.5.2 hbm推理
4.3.5.3 pyramid输入模型测试建议
对于pyramid模型,由于部署和训练输入格式不一致,因此若要使用插入前处理节点后的quantized.bc或者hbm做精度测试的话,需要适配一下前处理代码,需要注意的是,把训练时的rgb/bgr/yuv444转换成nv12,是存在信息损失的,若模型训练的时候前处理没有带上转nv12的过程,则有可能对这样的信息损失不够鲁棒,出现掉点的现象。因此若pyramid输入定点模型掉点超出预期,需要再测试一下不插入前处理节点的模型精度,若的确是nv12带来的损失,建议修改模型前处理重训浮点。
5. 模型部署
5.1 UCP简介
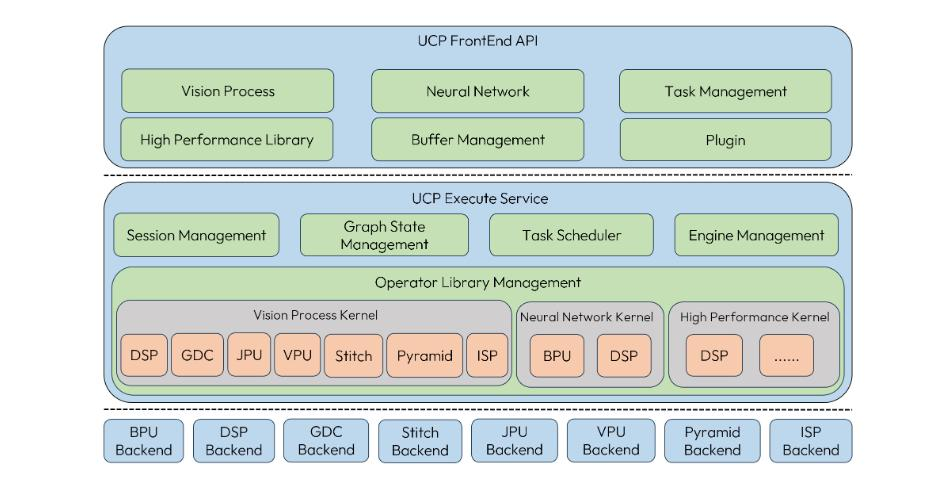
UCP 支持的 Backbend:

5.2 模型推理快速上手
5.3 Pyramid/Resizer模型输入准备说明
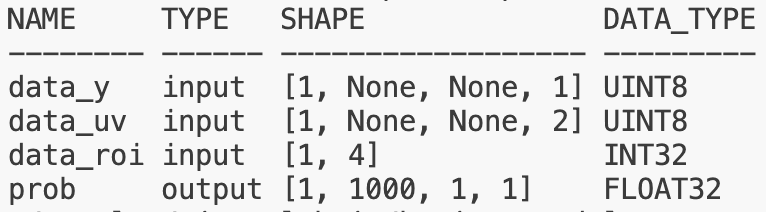
由于Pyramid/Resizer模型相对特殊,其输入是动态 shape/stride,因此单独介绍一下其输入tensor准备的注意事项和技巧。下表是解析Pyramid/Resizer模型观察到的现象(-1 为占位符,表示为动态,Pyramid 输入的 stride 为动态;Resizer 输入的 H、W、stride 均为动态。):
- Resizer 输入的 HW 动态,是因为原始输入的大小可以是任意的;
- Pyramid/Resizer 输入的 stride动态,可以理解为是支持 Crop 功能(后文5.4.1节)
| Pyramid | Resizer |
hb_model_info X86端命令行工具
|  |
hrt_model_exec model_info
板端可执行程序工具
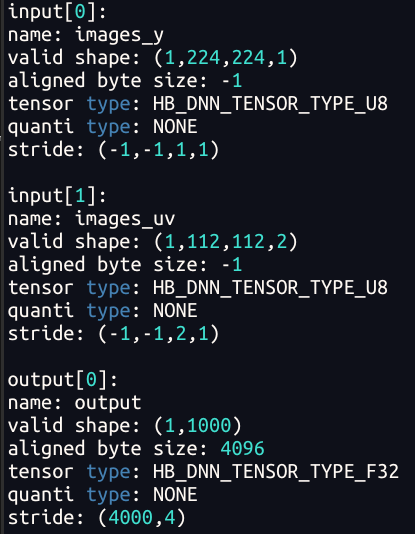
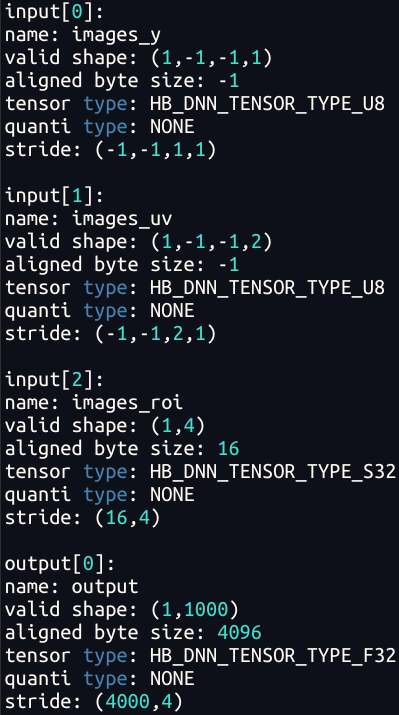
在J6H/P平台上要求Pyramid/Resizer输入必须满足W64对齐,因此无论是金字塔配置还是模型输入准备,都需要满足对齐要求。
输入tensor准备:
金字塔配置:
5.4 模型部署优化
5.4.1 通过地址偏移完成crop
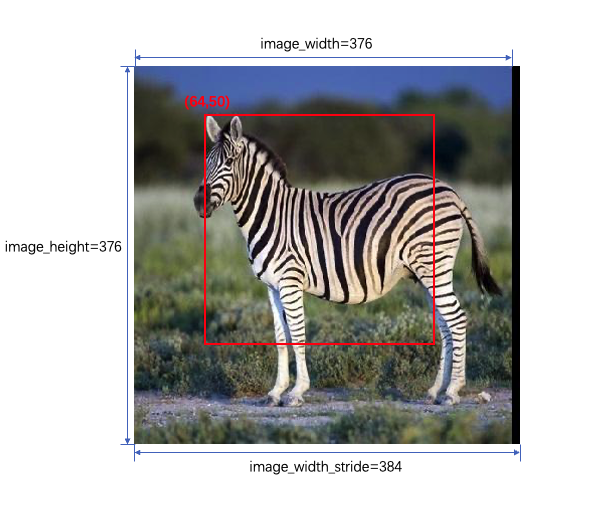
场景描述:
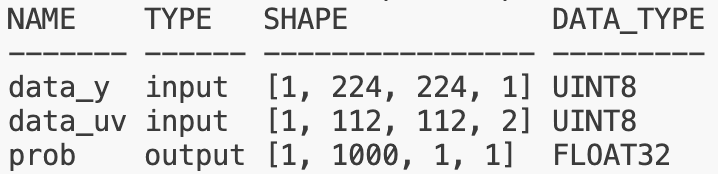
Y: validShape = (1,224,224,1), stride = (-1,-1,1,1)
UV: validShape = (1,112,112,2), stride = (-1,-1,2,1)
该模型的输入图片大小为 224x224,假设有一张 H x W = 376 x 384(其中W存在大小为8的padding,因为nv12需要W64对齐)的图片,可以直接基于 stride 值进行 crop,没有额外的拷贝开销
Crop功能使用:
原始图片 Y、UV 的 validShape、stride、指针如下:
- Y: validShape = (1, 376, 384, 1), stride = (384*376, 384, 1, 1),内存指针为y_data
- UV: validShape = (1, 188, 192, 2), stride = (384*188, 384, 2, 1),内存指针为uv_data
模型输入张量准备-Y:
- Crop 起始点 [h, w] = [50, 64],则: 地址偏移为 y_offset = 50*384 + 64*1,内存指针为 y_data + y_offset
- 模型输入应设置为 validShape=(1,224,224,1), stride = (224*384,384,1,1)
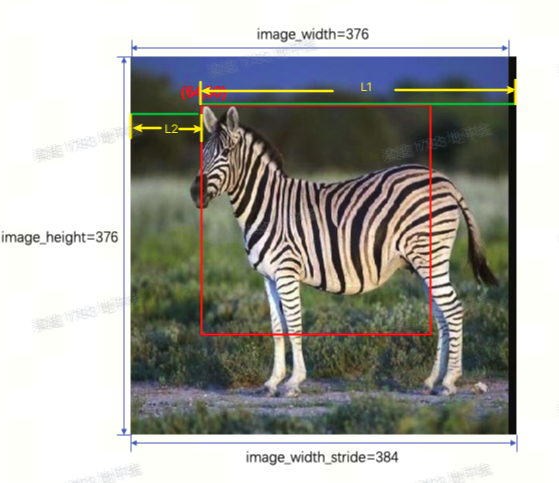
模型输入张量准备-UV:
- 由于 UV 尺寸为 Y 的 1/2,因此裁剪起始点为 [25, 32],则: 地址偏移为 uv_offset = 25*384 + 32*2,内存指针为uv_data + uv_offset
- 模型输入应设置为 validShape=(1,112,112,2), stride = (112*384,384,2,1)
Crop限制条件:
- 图像:要求分辨率 ≥ 模型输入,w_stride 需要 64 字节对齐
模型:要求输入 validShape 为固定值,stride 为动态值,这样能通过控制 stride 的大小对图像进行 Crop
裁剪位置:由于裁剪是对图像内存进行偏移,而对于输入内存的首地址要求 64 对齐
5.4.2 小模型批处理
由于 BPU 是资源独占式硬件,所以对于 Latency 很小的模型而言,其框架调度开销占比会相对较大。在 J6 平台,UCP 支持通过复用 task_handle 的方式,将多个小模型任务一次性下发,全部执行完成后再一次性返回,从而可将 N 次框架调度开销合并为 1 次,以下为参考代码:
5.4.3 优先级调度/抢占
- priority > customId > submit_time(任务提交时间)
- priority 支持 [0, 255],对于模型任务而言:
[0, 253] 为普通优先级,不可抢占其他任务,但在未执行时支持按优先级进行排队
254 为 high 抢占任务,可支持抢占普通任务
255 为 urgent 抢占任务,可抢占普通任务和 high 抢占任务
- 可被中断抢占的低优任务,需要在模型编译阶段配置 max_time_per_fc 参数拆分模型指令
其他 backend 任务,priority 支持 [0, 255],但不支持抢占,可以认为都是普通优先级
5.5 DSP开发
为了简化用户开发,UCP 封装了一套基于 RPC 的开发框架,来实现 CPU 对 DSP 的功能调用,但具体 DSP 算子实现仍是调用 Cadence 接口去做开发。总体来说可分为三个步骤:
使用 Cadence 提供的工具及资料完成算子开发;
DSP 侧通过 UCP 提供的 API 注册算子,编译带自定义算子的镜像;
ARM 侧通过 UCP 提供的算子调用接口,完成开发板上的部署使用。
6. 相关基础知识

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)