
QAT训练完成后,从torch qat伪量化模型到J6板端部署hbm模型之间,有模型export导出、convert转定点、插入前处理节点以及compile编译等步骤,在这些步骤中,如果出现精度不一致的情况,说明存在一致性问题。一致性问题分为两类:
用户侧问题。例如:前后处理不一致,代码误用导致训练部署图不一致的问题等。
工具侧问题。例如:查表算子转定点(非线性函数使用多项式近似或分段线性近似来代替精确计算)、不同硬件对于浮点/定点实现不一致、rgb/yuv444转nv12存在信息损失等,由于神经网络具有一定的鲁棒性,若不存在代码误用以及工具bug的情况下,板端hbm模型精度 与torch qat伪量化模型之间的误差很小。
不论哪类一致性问题,您都可以参考本文进行排查。
1. 基础定义
一致性问题从API分割看,主要包括export前后、convert前后、compile前后,在分析过程中,可能还会引入查表算子转定点(pre_export)、插入nv12节点前后(insert_nv12)、删除首尾节点前后(remove_op)的一致性问题,在深入分析之前,大家先统一各阶段模型的概念:

主要模型 | 说明 | 获取方法 |
qat.pt | torch qat 模型 | 对插入quant/dequant后的浮点模型使用 prepare 接口 |
qat_export.pt
| torch qat export 模型。相比于qat.pt 做了查表算子定点化。 相比于qat.bc,计算逻辑一致,依旧为torch模型,可用gpu推理加速 | qat_pt要先validation和eval,再去pre_export |
qat.bc | export导出产生的 hbir 模型 | |
quantized.bc | 由qat.bc convert定点化产出的 hbir 模型 | |
nv12_quantized.bc | 图像输入插入nv12节点 | 在图像输入前插入nv12节点后进行定点化,示例可见《J6E/M计算平台部署指南-6.3模型修改》 |
hbm | 编译产生的板端部署模型 | 对 quantized.bc 模型使用 compile 接口 |
2. 一致性问题定位流程
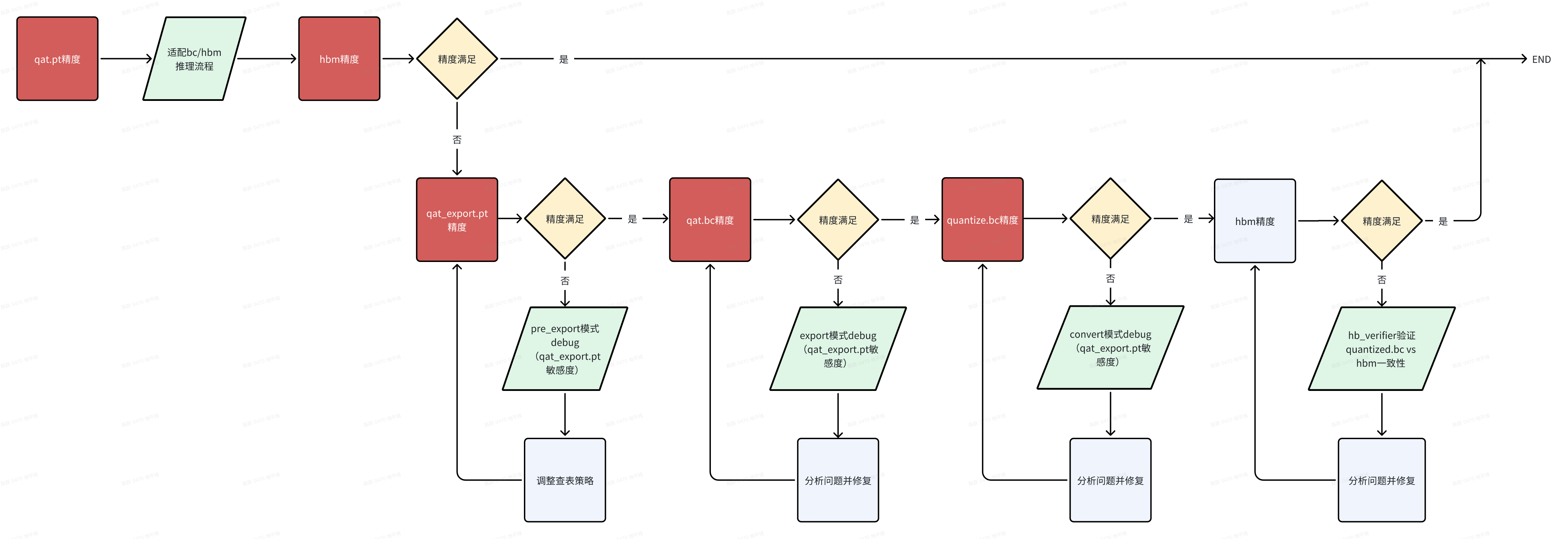
3. export一致性分析
3.1 分析前提
- 分析export一致性时,请先确认qat_model eval精度与单帧可视化符合预期;
qat.bc与qat_model eval共用一套前后处理,保证不存在前后处理差异导致的一致性问题;
qat.bc多帧数据可视化均不符合预期;
3.2 分析思路
3.2.1 模型一致性上限
3.2.2 仅查表转定点
export出现一致性问题时,通常需要先判断是否为 查表转定点导致的。具体方式为:将qat_model通过pre_export接口仅转查表,验证pre_export_pt可视化。
若pre_export_pt 多帧可视化 or 验证集精度指标 符合预期:说明查表算子没问题,跳过该章节
若pre_export_pt 多帧可视化 or 验证集精度指标 不符合预期:说明是查表算子转定点引起的问题,需要排查具体是哪个查表造成的。
- 【定位具体查表op】若从debug工具产出物中未分析出是哪个(些)查表算子造成的一致性问题,可根据plugin debug工具的敏感度排序,设置敏感度高的部分 查表op 取消转定点,缩小问题op范围。如果将部分 查表op 取消转定点后,pre_export_pt精度上升/可视化正常,则说明确实是这些 查表 op导致。
- 【查表转定点常见解决方案】常见有一致性问题的查表op:rsqrt、reciprocal、sin/cos等,可尝试增大num_tables的数值来优化查表算子的一致性,用于拟合非线性函数的表项num_tables需配置为6的倍数,不同查表op默认num_tables不同,经验看,num_tables超出126后对查表一致性几乎不再有收益。在qat_model加载权重后,在pre_export前配置num_tables,配置示例如下:
如果希望全局进行 所有sin/cos 去周期,可以参考如下用法。(也需要重新calib/qat)
3.2.3 图一致性
在确认仅查表转定点pre_export_pt模型的精度/多帧可视化符合预期后,若qat.bc依旧存在精度问题,请优先检查export通路代码中是否存在if 部署逻辑(只有部署才走的通路),若存在,先尝试不走部署逻辑export生成qat_bc,验证此时qat_bc可视化是否符合预期。
- 若符合预期:说明if逻辑造成图不一致影响了权重加载或代码有误。
重点关注的Graph信息:
- opcode为算子调用类型
- name为当前算子名称,需注意和model_check_result.txt中的module.submodule名称区别
- target为算子输出
- args为算子输入
- 若不符合预期:往下尝试 3.2.3 plugin debug工具
3.2.4 plugin debug工具
当qat_export.pt指标正常,qat.bc精度指标不符合预期,且不存在图不一致问题时,需要运行plugin debug工具来分析“export”阶段一致性问题,
分析pre_export_pt_vs_qatbc阶段的debug工具产出物,发现哪个算子一致性误差大,根据算子支持情况,配置更高精度类型进行量化导出,再次验证一致性。
4. convert一致性分析
4.1 分析前提
分析convert一致性时,说明qat.bc精度/可视化符合预期,quantized.bc多帧数据可视化均不符合预期;
qat.bc与quantized.bc使用相同的输入和后处理,避免非模型部分引起的差异;
4.2 分析思路
4.2.1 J6EM高一致性策略【OE3.5.0为beta功能】
高一致性策略对查表转定点无影响,主要影响convert前后的一致性
- level0全局开启会对latency有负面影响,大约10~20%,甚至出现过40%的情况
- level2对latency有正面收益,推荐优先使用level2
高一致性策略仅适用于J6EM
- 实现方式未来会进行优化,请大家使用时关注用户手册《QAT-训练部署一致性-高一致性 QAT 策略》章节
高一致性策略封装在 horizon_plugin_pytorch.qat_mode.ConsistencyStrategy 下,可以使用 set_consistency_level 接口设置策略。
当前支持五个等级( 0 - 4 )的策略,等级越高,一致性越好,但 QAT 精度可能受到轻微影响。推荐直接使用 level 2,在绝大多数情况下对 QAT 精度无影响,甚至可以改善因截断误差引起的精度问题,对性能和一致性有正收益。
level2 在convert阶段,linear与conv会有一个scale的误差,其它op是对齐的
level4 在convert阶段,linear与conv也会有一个scale的误差,但概率会降低到万分之几
linear与conv将bias去掉,level4 在convert阶段将没有误差
4.2.2 plugin debug工具
当采用高一致性策略未解决convert前后的一致性问题时,需要运行plugin debug工具来分析“convert”前后一致性问题,建议使用高一致性策略后的模型来对比分析,示例如下
判断正确运行plugin debug工具方法:
compare_per_layer_out.txt:存在对比结果
output_xxx_sensitive_ops.txt:敏感度有高有低,且最后几个算子的量化敏感度接近于 0
4.2.3 分段转浮点
绝大部分情况下,plugin debug工具都可以分析解决convert前后一致性问题,若您发现plugin debug工具失效或不想适配使用plugin debug工具,工具链还支持分段转浮点的方法来分析convert前后一致性,具体做法是将qat.bc中 某op 或 一定范围的op 配置为CPU算子,从而定位出引起convert定点化中掉点的op。
在qat.bc模型中,每个节点都有一个id,根据id将某些伪量化删除可以使得模型的一部分变成cpu算子,下图为qat.onnx的可视化图。
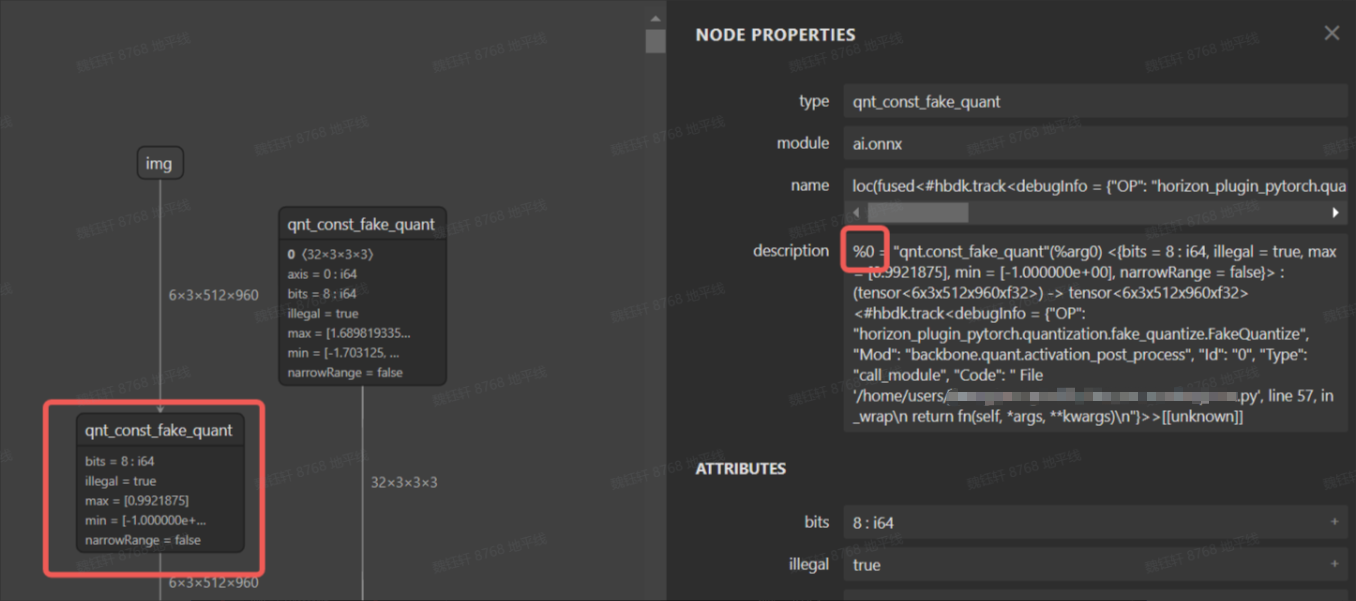
bc编辑工具在horizon_plugin_profiler/bc_editor/bc_editor.py,使用方式如下:
config.json内容可以参考horizon_plugin_profiler/bc_editor/config_template.json,指定需要删除的伪量化op id,可以是一个区间id,也可以是单个op id,通过该方案,可很容易实现分段浮点.
5. nv12节点插入一致性分析
5.1 分析前提
分析nv12节点插入一致性时,说明quantized.bc精度/可视化符合预期,nv12_quantized.bc多帧数据可视化均不符合预期;
quantized.bc与nv12_quantized.bc使用相同的后处理,避免因后处理差异引入一致性问题;
5.2 分析思路
nv12输入理论上对于模型输出影响很小,可以按照如下三个思路来挨个验证:
nv12节点插入代码误用
nv12输入数据准备差异
确实是nv12引入的误差(非bug类)
5.2.1 nv12节点插入代码误用
nv12节点插入具体细节请参考工具链用户手册 或 配套的迁移文档,常见的误用在insert_image_preprocess中的mode参数,具体示例如下,详见代码注释:
5.2.2 nv12输入数据准备差异
推荐采用如下代码准备nv12数据
5.2.3 非bug类nv12引入的误差
如果你的网络对nv12节点插入造成误差特别敏感,则需要将该误差带入到模型训练中,可参考如下代码:
其中,b2y内部实现了bgr->nv12->yuv444的转换。
6. compile一致性分析
6.1 分析前提
分析compile一致性时,说明quantized.bc 或 nv12_quantized.bc 精度/可视化没问题。
模型中没有浮点算子时,可以做到小数点后4位一致,如果有浮点算子,由于不同硬件平台对浮点算子的 实现方式、支持精度(FP32/FP16)、底层数学库 等存在差异,存在差异是普遍存在的,不一定能做到小数点后4位对齐。
bc与hbm使用的前后处理一致。
6.2 分析思路
为了方便不同编码习惯的客户快速比对compile前后bc与hbm的一致性,工具链提供了三种分析方法:
- 使用命令行工具hb_verifier快速比对
- 使用python API:hbdk接口快速比对(推理速度相对较慢)
- 使用python API:hbm_infer接口快速比对(推理速度相对较快)
6.2.1 hb_verifier工具
hb_verifier比对bc与hbm一致性时,需要关注的信息如下:
参数名称 | 参数说明 |
-m, --model | 指定模型输入,HBIR模型(*.bc)文件、HBM模型(*.hbm)文件。 两个模型地址之间用“,”分割:-m model1,model2。 |
-i, --input | 指定推理测试时使用的数据,仅支持*.npy文件。 多输入模型添加输入数据有以下两种传参方式,多个数据之间用“,”分割:input_name1:input_data_1.npy,input_name2:input_data_2.npy, … input_data_1.npy,input_data_2.npy… |
-c, --compare_digits | 设置比较推理结果的数值精确度(即比较数值小数点后的位数),若不进行指定,工具会默认比较至小数点后五位。 |
--ip | 指定开发板 IP 地址,默认为空。多个输入需要使用英文逗号分隔。 |
-u, --usename | 指定开发板用户名称,默认为 root。多个输入需要使用英文逗号分隔。 |
-p, --password | 指定开发板用户密码,默认为空。多个输入需要使用英文逗号分隔。 |
--port | 指定开发板 SSH 端口,默认为 22。多个输入需要使用英文逗号分隔。 |
bc与hbm一致性比对时,输出信息如下:

比对示例如下:hbm推理支持板端与x86仿真两种运行方式,二者结果是一样的,板端推理速度会更快一些。
若一致:则一致性问题出现在前后处理没对齐。
- 若不一致:请准备好quantized.bc与hbm,在地平线开发者社区-工具链板块上提问。
6.2.2 hbdk接口推理
使用hbdk提供的API接口 hbm[0].feed,在相同输入的情况下(可以是算法侧提供,也可以是软件侧提供),推理quantized.bc与hbm(hbm推理支持板端与x86仿真两种运行方式,二者结果是一样的,板端推理速度会更快一些),验证他们的输出一致性/可视化,带nv12节点的验证示例代码如下:
6.2.3 hbm_infer接口推理
输入数据的读取代码需要用户根据实际的目录和文件格式进行修改,如下示例是以.bin文件为例,经过量化然后介入bc与hbm模型。如果是numpy或者pkl文件,需要根据实际情况进行读取和处理。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)