
1.需求场景
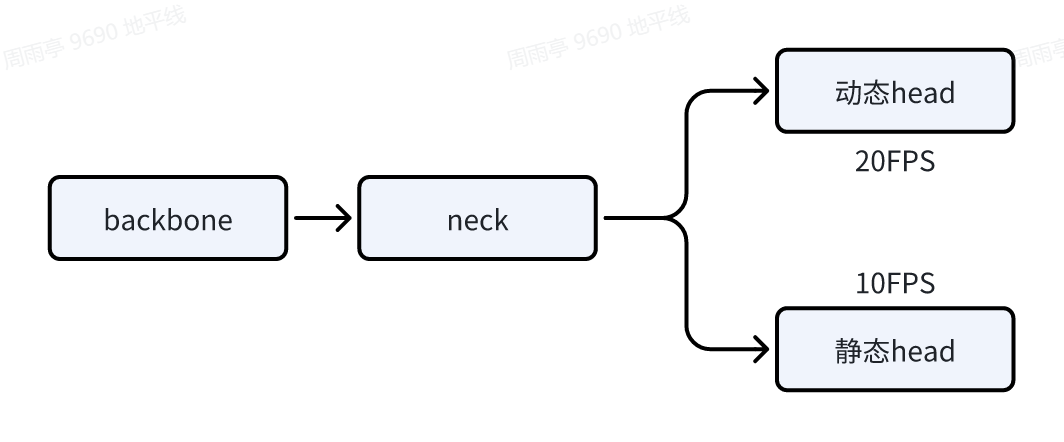
2.技术分析
以BEV动静态任务为例,实现不同任务分支推理不同帧率(动态20帧,静态10帧),很容易想到两种方案:
模型1推理20次,输出分别送给模型2推理20次,模型3推理10次。
优点:应用层可灵活调度3个子模型的推理;模型1-公共部分 只需要推理20次;
缺点:模型1-公共部分的输出内存需要额外存储,增加load/store带宽消耗;拆分次数多,影响编译时的全图优化,可能会增加latency;
模型1-公共动态推理20次,模型2-公共静态推理10次。
优点:应用层可灵活调度2个子模型的推理;只需准备整个模型输入/出内存,无需准备公共部分输出的内存;拆分次数少,编译时可全图优化,减小latency;
缺点:公共部分(backbone+neck)需要推理30次,造成latency增加与BPU资源浪费;公共部分需要存储两份;
为了兼顾方案1与方案2的优点,同时实现不同任务分支推理不同帧率,工具链提供了link打包功能,具体打包方式如下:
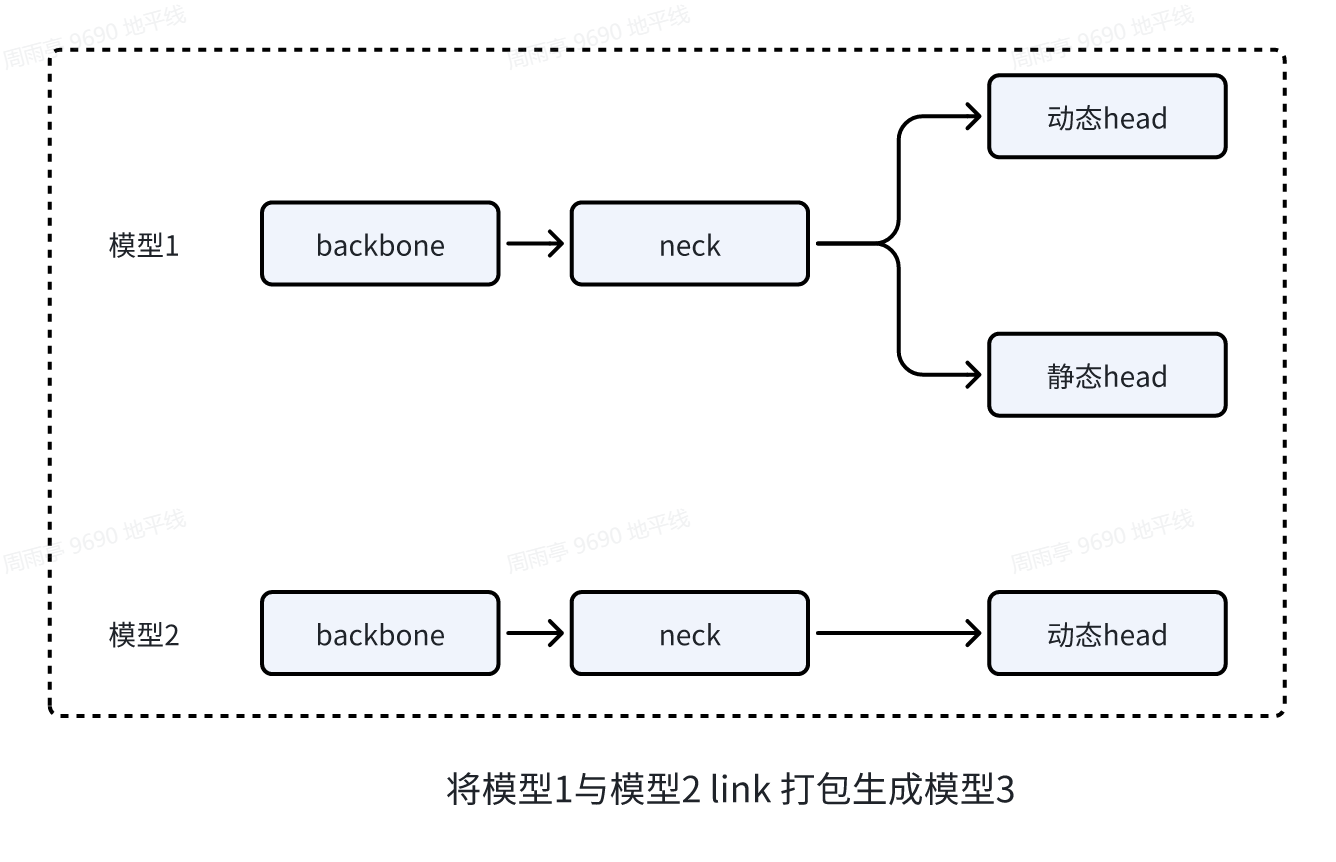
上图中将模型1与模型2 link 打包生成的模型3,相比于模型1体积不会大多少,同时具备推理模型1与模型2的功能。根据需求,调整模型1与模型2的推理次数,即可实现不同任务采用不同帧率部署。
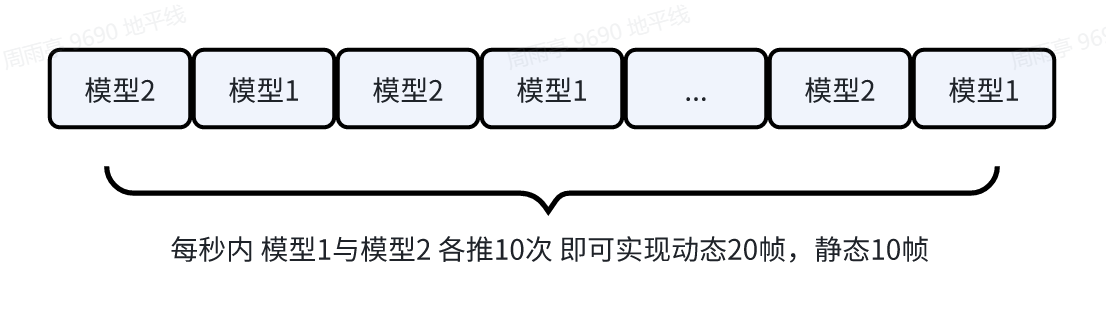
如下图所示:推理一次模型1,可实现动态任务head与静态任务head各推理一次,推理模型2可实现仅推理一次动态任务head,当模型1推理10次、模型2推理10次时,即可实现动态推理20次,静态推理10次的效果。(公共部分backbone+neck仅推理20次)
3.方案实现
3.1 模型link打包
根据需求场景,先将多任务模型拆分导出为不同子任务的qat.bc,然后分别将他们编译成hbo文件,最后将多个hbo文件link打包为一个hbm模型。
compile输出同时支持hbm与hbo两种文件格式,可通过配置文件后缀名为".hbm" or ".hbo"来区分。
link支持将多个hbo文件打包生成一个hbm文件。
将两个hbo文件通过link打包生成一个hbm模型,示例代码如下:
3.2 打包模型推理
3.2.1 hrt_model_exec工具推理
结合--model_file与--model_name即可实现对打包compiled.hbm模型中的某一个模型进行推理。
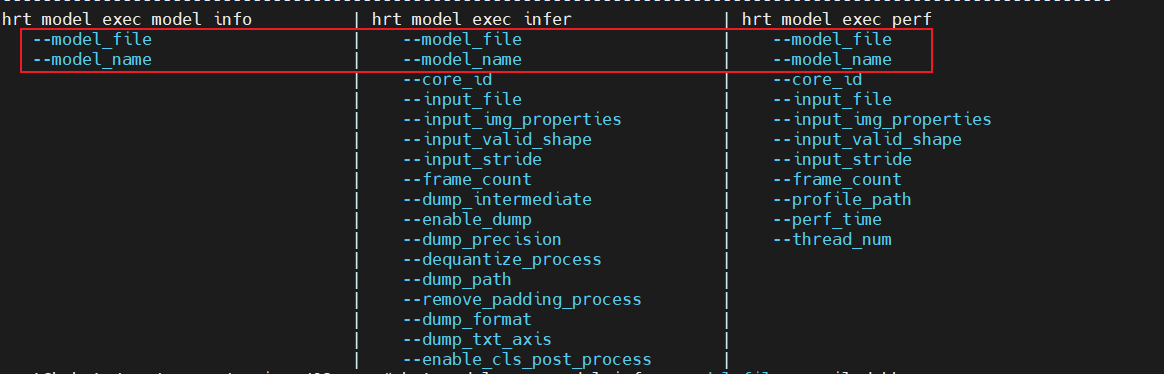
以perf评测打包compiled.hbm模型 中 2_backbone_head1 的性能为例,参考命令如下:
3.2.2 UCP API推理
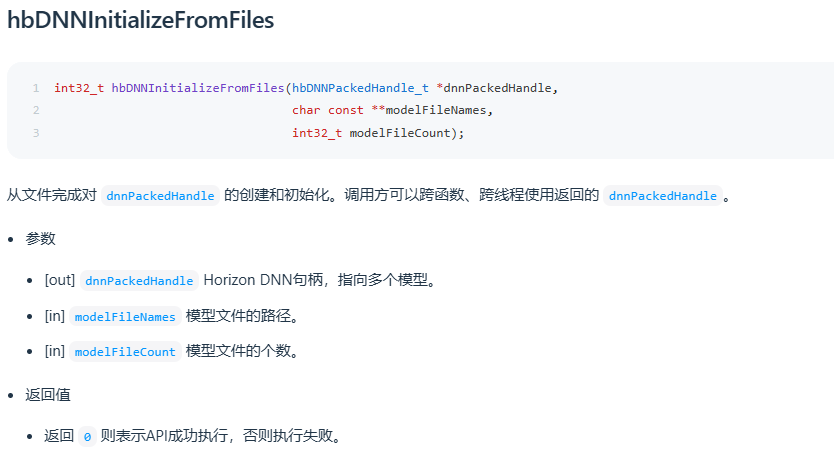
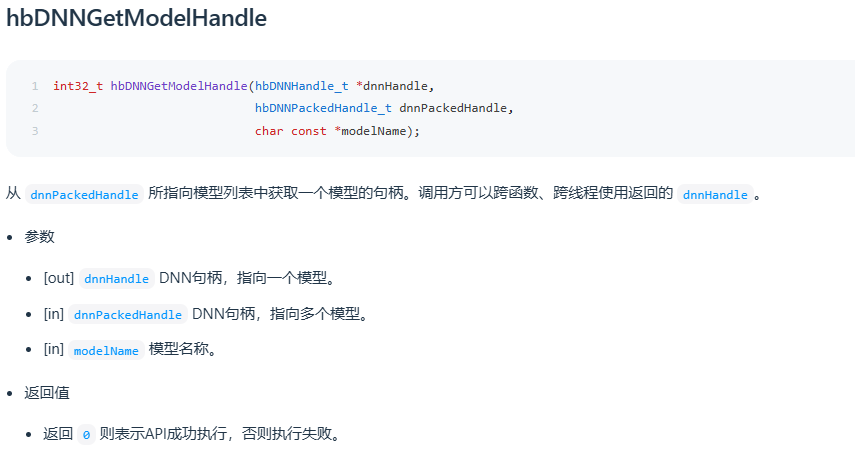
在工具链开发包路径:OE/samples/ucp_tutorial/dnn/basic_samples 下方的示例中有用到这两个接口,可参考使用。
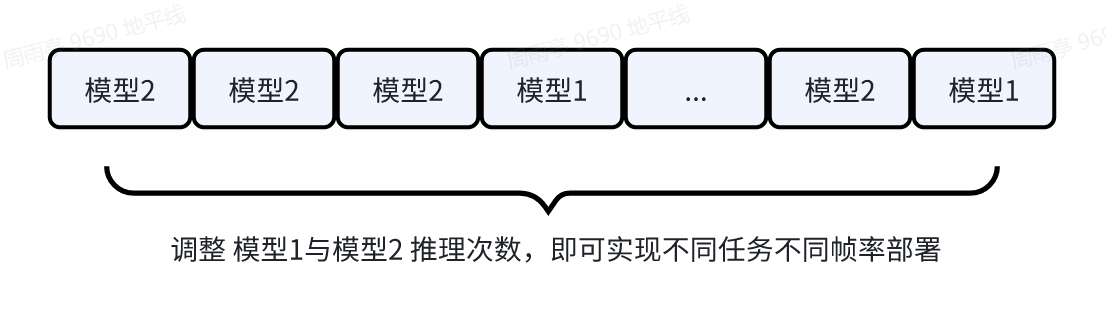
3.3 多任务不同帧率推理
根据需求,调整打包模型compiled.hbm中的 模型1 backbone_head1_head2 与模型2 backbone_head1的推理次数,即可实现不同任务采用不同帧率部署。
3.4 性能数据示例
模型名称 | 模型大小/KB | 模型name | latency/ms |
1_backbone_head1_head2.hbm | 30295 | / | 5.19 |
2_backbone_head1.hbm | 21781 | / | 4.84 |
compiled.hbm | 30776 | 1_backbone_head1_head2 | 5.18 |
2_backbone_head1 | 4.83 |
可以看到,compiled.hbm体积相比于1_backbone_head1_head2.hbm并没有增加多少。
模型加载推理时,ION内存差异如下:
加载1_backbone_head1_head2.hbm,直接推理:
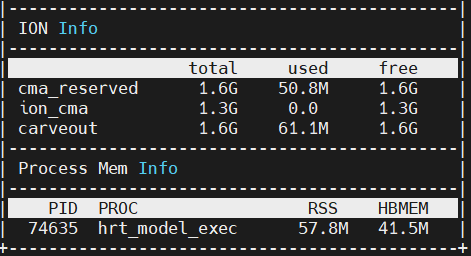
加载compiled.hbm,推理1_backbone_head1_head2:
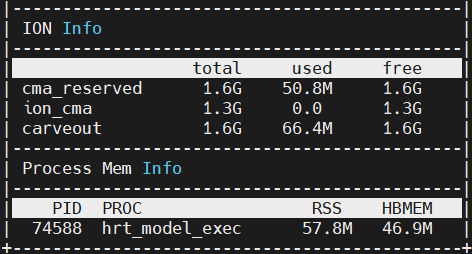
可以看到,compiled.hbm占用的内存相比于1_backbone_head1_head2.hbm并没有增加多少。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)