
该示例为参考算法,仅作为在J6上模型部署的设计参考,非量产算法
1 简介
SparseBevFusionMultitaskOE模型是一个bev多任务感知模型,包含感知三大任务的检测头:sparse动态检测头,sparse静态元素检测头和通用障碍物检测头。整体的模型结构如下:
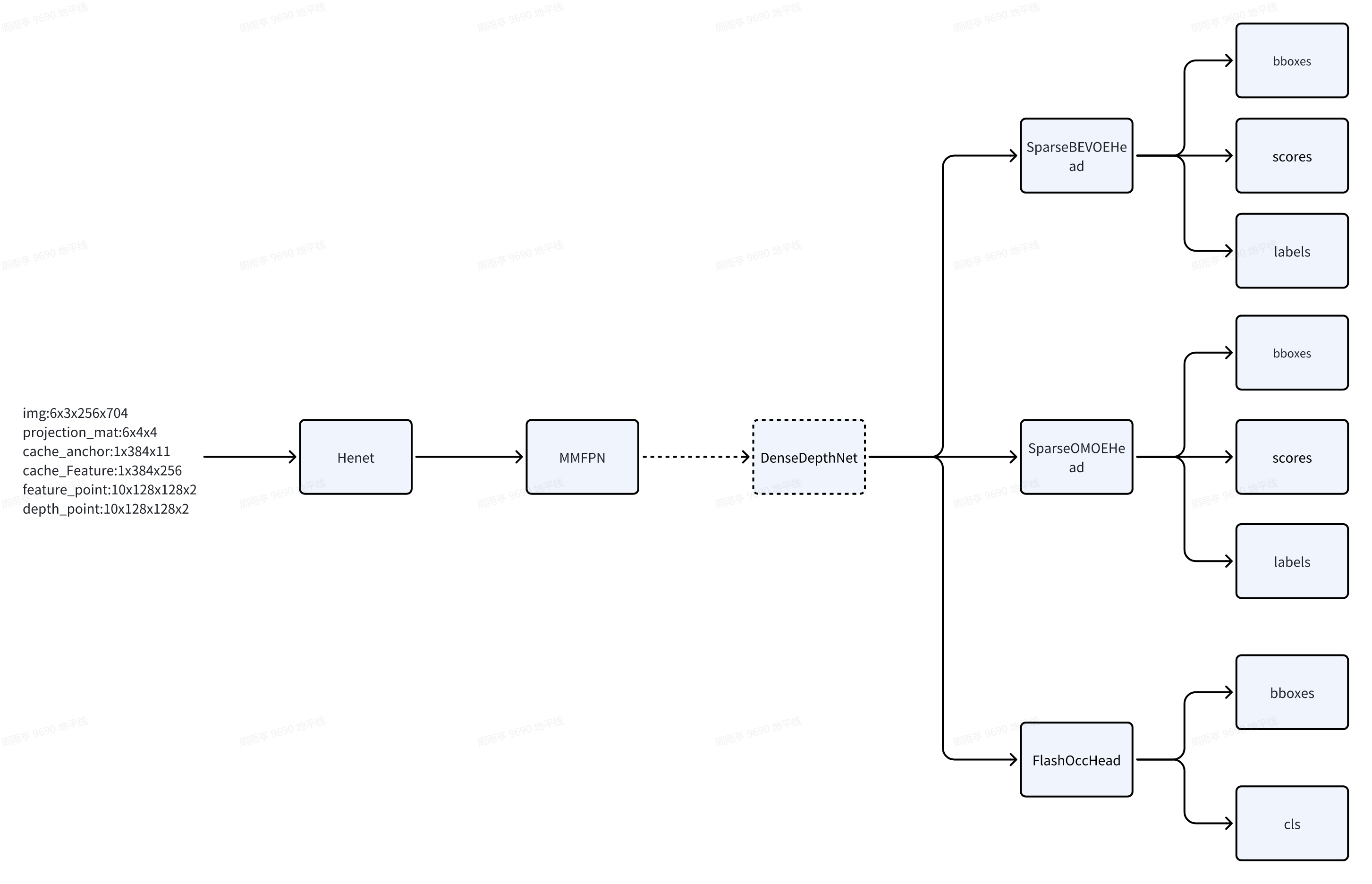
sparse bev类模型主要思路是通过关键点投影回camera空间采样并进行预测。因此对于多任务模型来说,不同task之间可以共用的是img_encoder的backbone和neck部分,同时加入辅助分支densedepthnet用于辅助训练,部署时不需要。动态检测、静态要素检测和占用格预测任务可以分别抽象为三个head:detection head(det head)、onlinemapping head(om head)和occupancy head(occ head)。在模型的选择上,我们选取了参考算法已集成的,也是较主流的模型-sparse4d、maptr、flashocc,在J6上部署的效果更好。
2 性能精度指标
模型信息 | 精度(浮点/qat) | J6M性能 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
模型 | 数据集 | Input shape | backbone | num_anchor | det | om | occ | FPS | Latency | |
NDS | mAP | mAP |
| |||||||
bev_sparse_henet_tinym_nuscenes | Nuscenes | 6x3x256x704 | HENET | 384 | 0.5421/0.5323 | 0.4339/0.42222 | - | - | 79
| 12.92ms
|
maptroe_sparse_henet_tinym_nuscenes | Nuscenes | 6x3x256x704 | HENET | 100 | - | - | 0.5982/0.5959 | - | 77 | 13.22ms |
flashocc_henet_lss_occ3d_nuscenes | Nuscenes | 6x3x512x960 | HENET | bevsize 128x128 | -
| - | - | 0.3674/0.3642 | 119
| 8.39ms
|
SparseBevFusionMultitaskOE | Nuscenes | 6x3x256x704
| HENET | sparse4d:384 maptr:100 flashocc:bevsize 128x128 | 0.5234/0.5214 | 0.41/0.41 | 0.5958/0.5906 | 31.89/33.31 | 35 | 28.6ms |
注:flashocc掉点为分辨率降低导致;sparse动态目标检测掉点会在后续版本中优化。
3 地平线部署说明
sparse多任务模型的每个head是基于公版模型做了优化后部署的,以下为模型相较于公版的改动点:
模块 | 改动点 |
|---|---|
input | 统一为6x3x256x704 |
backbone | img_encoder和bev_encoder均使用henet |
neck | img_encoder 使用MMFPN,返回所有层的feat |
Sparse head |
|
maptr head |
|
occ head |
|
详细可以参考单任务模型的参考文档的改动说明章节:
地平线静态目标检测 MapTR 参考算法-V2.0 - 地平线开发者社区
地平线3D目标检测 bev_sparse 参考算法-V2.0 - 地平线开发者社区
地平线占用预测FlashOcc参考算法-V1.0 - 地平线开发者社区
3.1 训练策略
3.1.1 浮点训练
(一)数据结构说明
参考算法已有的三个单任务模型都是基于nuscenes数据集的,它同时包含三个任务的标注数据。其中dataset使用NuscenesSparseMapDataset,包含了地图相关的标注。
(二)训练架构
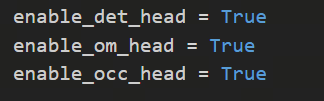
构建一个OrderedDict,通过标识选择加入哪些模型,然后在整体model中,传入task_heads。
注:为了兼容lidar融合的模型,head中保留lidar_feature,在不使用lidar net的情况下lidar_feature=None
(三)训练策略
SparseBevFusionMultitaskOE模型在训练上:
SparseBevFusionMultitaskOE模型为同源数据集,多个任务一起训练,非单独的训练某个head。
模型训练时需要增加添加BevRotation,经过在nescenes上验证,不添加会导致掉点。
训练策略复用了单任务模型 。
对模型配置loss weight,根据模型表现动态的调整权重值。
3.1.2 模型量化
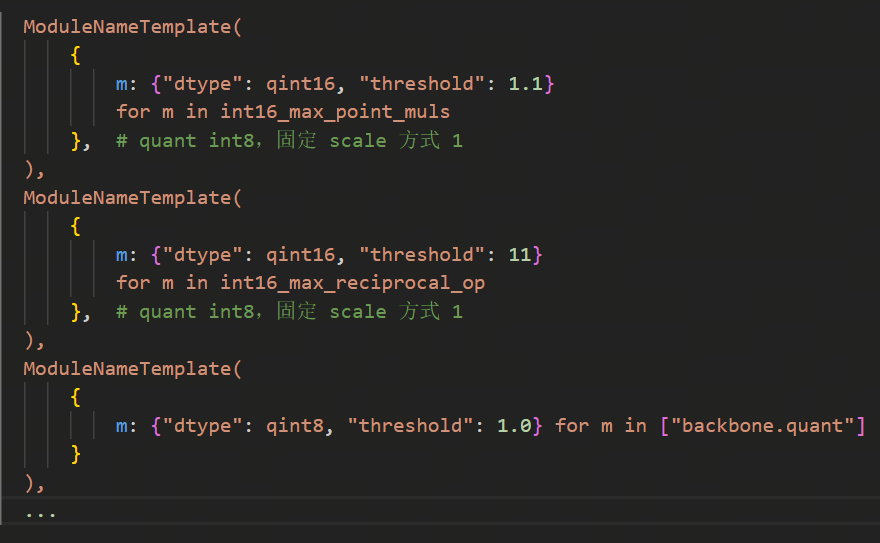
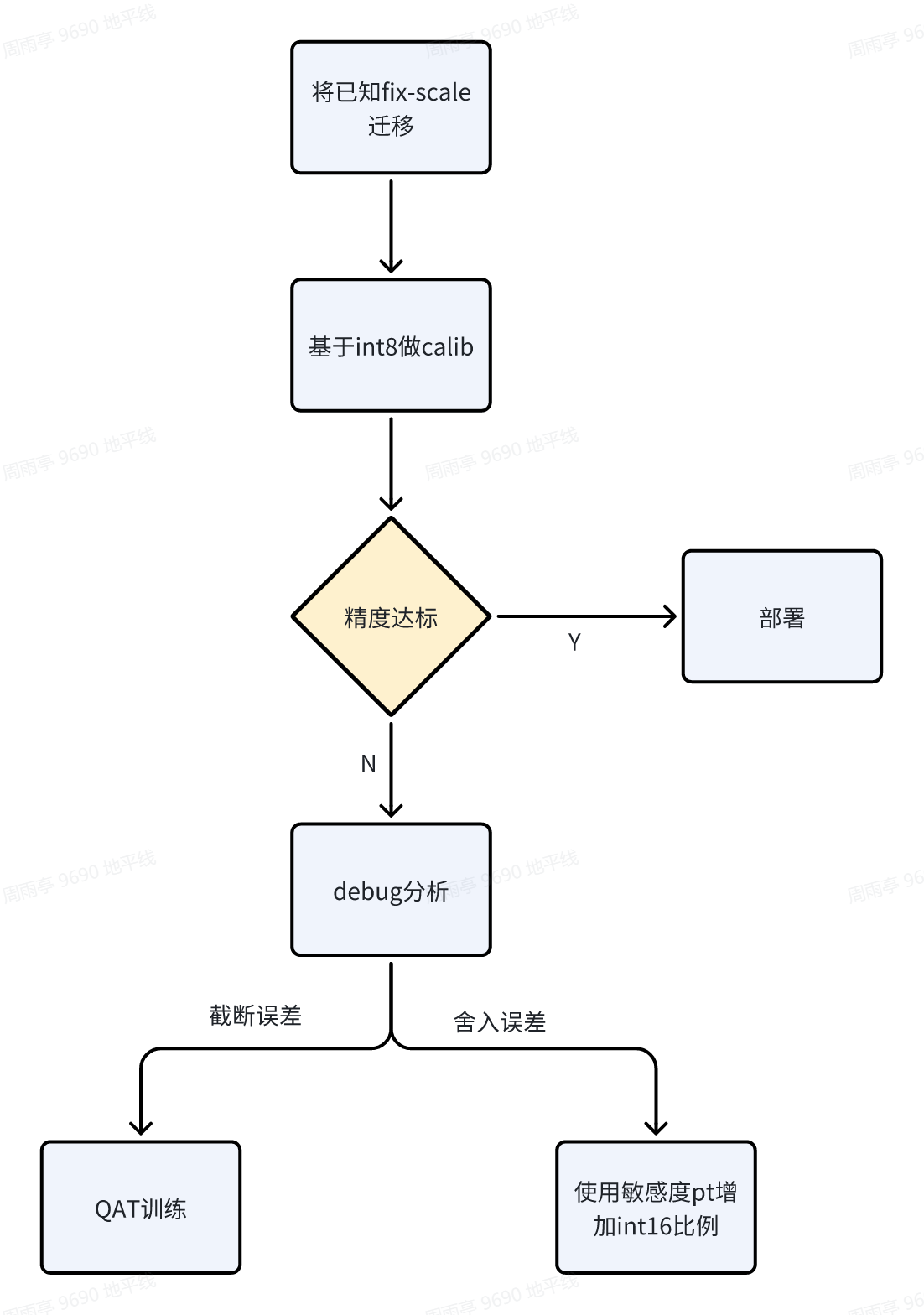
在多任务时,建议先将已知的在单任务中需要fix-scale的层(特别是具有物理意义、范围固定的op)做固定scale处理、对已知需要int16精度的算子配置高精度。例如动态单任务的fix-scale为:
多任务时可以做复用:
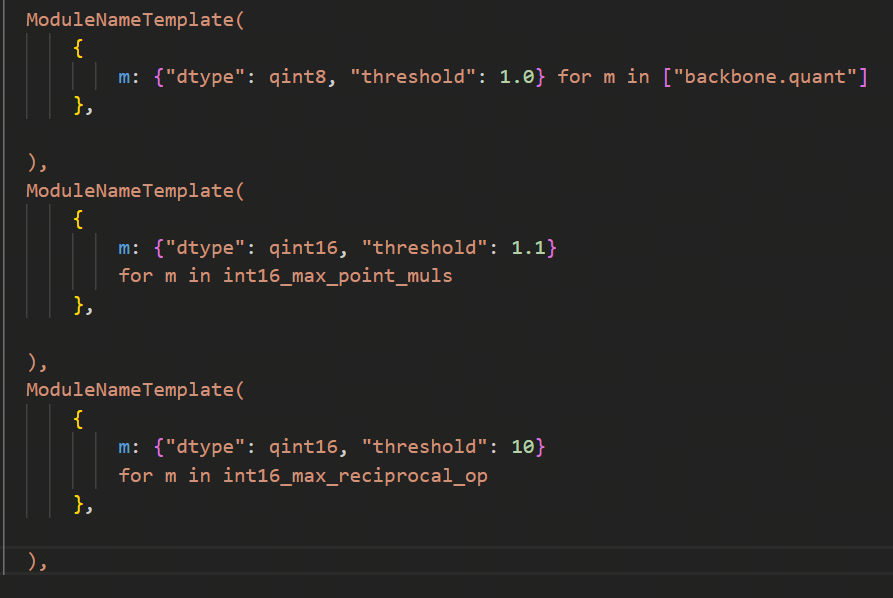
多任务量化推荐流程:
4 总结与建议
4.1 部署建议
尝试训练时增加数据增强(BEV Rotate)提高模型的泛化能力
对精度较差的任务可以适当的增大loss weight
量化优先尝试HistogramObserver校准方式
多任务量化时建议基于单任务的经验,对需要固定scale的算子做fixscale,可以有效缩短量化周期。
本文通过对SparseBevFusionMultitaskOE在地平线征程6上量化部署的优化,使得模型在J6M上得到latency为28 ms的部署性能,同时,通过SparseBevFusionMultitaskOE 的部署经验,可以推广到其他多任务模型的部署中。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
