
文档版本 | 修订内容 | 修订时间 |
|---|---|---|
v1.1 | 同步E/M调优文章更新:conv+add 融合拆分方法;新增QAT训练常见异常排查文章跳转 | 2026/07/13 |
v1.0 | 初始版本 | 2025/10/22 |
QAT调优流程
流程总览:
针对J6P/H的硬件特性,以int8+int16+fp16的混合精度量化为主要调优配置,会增加较多的fp16设置来优化量化精度
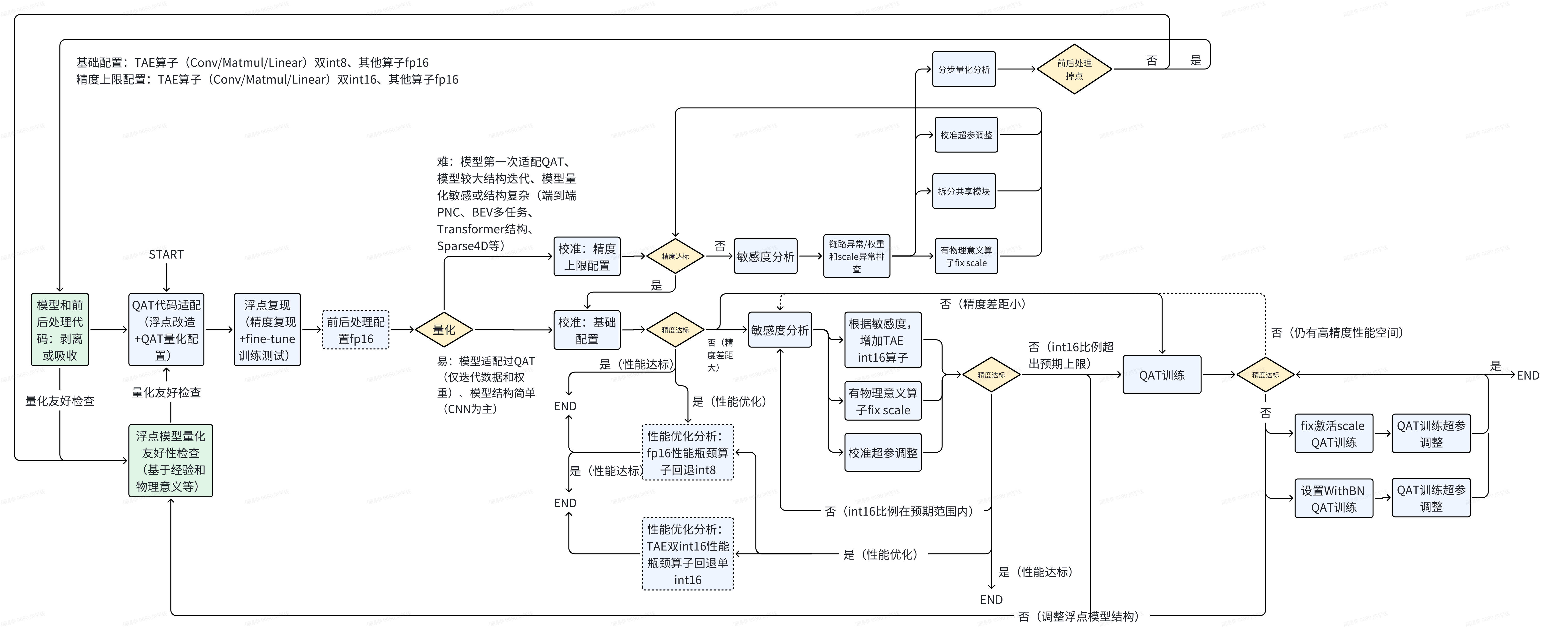
J6H/P上会用到更多fp16高精度和GEMM类算子双int16等的配置,为了配置方式更加简单灵活,QAT量化工具提供了一套新的qconfig量化配置模板,具体使用方式和注意事项参考:
《【地平线J6工具链入门教程】QAT新版qconfig量化模板使用教程》
调优原则:
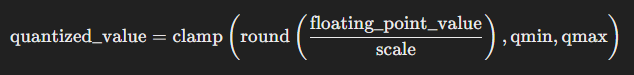
如上是一个标准的对称量化公式,产生误差的地方主要有:
- round 产生的舍入误差。例如:当采用 int8 量化,scale 为 0.0078 时,浮点数值 0.0157 对应的定点值为 round(0.0157 / 0.0078) = round(2.0128) = 2,浮点数值 0.0185 对应的定点值为 round(0.0185 / 0.0078) = round(2.3718) = 2,两者均产生了舍入误差,且由于舍入误差的存在,两者的定点值一致。
对于舍入误差,可以使用更小的 scale,这样可以使得单个定点值对应的浮点值范围变小。由于直接减小 scale 会导致截断误差,所以常用的方法是使用更高的精度类型,比如:将 int8 换成 int16,由于定点值范围变大, scale 将减小。 - clamp 产生的截断误差。当 qmax * scale 无法覆盖需要量化的数值范围时,可能产生较大截断误差。例如:当采用 int8 量化,scale 为 0.0078 时,qmax * scale = 127 * 0.0078 = 0.9906,大于 0.9906 的值对应的定点值将被截断到 127。
对于截断误差,可以使用更大的 scale。scale 一般是由量化工具使用统计方法得到,scale 偏小的原因是校准数据不够全,校准方法不对,导致 scale 统计的不合理。比如:某一输入的理论范围为 [-1, 1],但校准或 qat 过程中,没有观测到最大值为 1 或最小值为 -1 的样本或观测到此类样本的次数太少。应该增加此类数据或者根据数值范围,手动设置固定 scale。在截断误差不大的情况下,可以调整校准参数,通过不同的校准方法和超参缓解截断误差。
【注意】:J6P/H 平台的浮点模型量化友好设计以及 QAT 模型改造等内容和 J6E/M 一致,仍可参考该文章对应章节:
【地平线J6工具链进阶教程】J6E/M工具链QAT精度调优-v1.1
。其中文章2.1节常见问题新增:通过插入identity拆分conv+add 算子融合方法
1. 模型检查
完成模型改造和量化配置后,调用Prepare接口时会对模型做算子支持和量化配置上的检查,这些检查一定程度上反映了模型量化存在的问题。对于不支持的算子将以报错的形式提醒用户,一般有两种情况:
- 未正确进行模型的量化改造。Prepare过程中QAT量化工具会对模型进行trace来获取完整的计算图,在这个过程中会完成算子替换等的优化,对于这些已替换的算子,输入输出类型如果是torch.tensor而非经过QuantStub转化后的qtensor,则会触发不支持算子的报错,表现为xxx is not implemented for QTensor;
确实存在不支持的算子。工具链已支持业界大量的常用算子,但对于部分非常见算子的不支持情况,需考虑进行算子替换或者作为算子需求向工具链团队导入。
- 算子融合检查。算子融合作为QAT量化工具的标准优化手段,常见的融合组合为Conv+ReLU+BN和Conv+Add等,未融合的算子会在txt文件中给出,未按预期融合的算子可能是因为共享没有融合成功或者是QAT量化工具的融合逻辑变更(针对新版qconfig量化模板enable_optimize=True情况,见【地平线 J6工具链入门教程】QAT新版qconfig量化模板使用教程),需要检查代码,确认未融合的情况是否符合预期:
共享模块检查。一个 module 只有一组量化参数,多次使用将会共享同一组量化参数,多次数据分布差异较大时,会产生较大误差:
called times > 1 的模块可能有很多个,全部改写成非共享是一劳永逸的。对于修改简单且精度影响大的共享算子如QuantStub,强烈建议取消共享;对于DeQuantStub算子,共享不会对模型精度产生影响,但是会影响Debug结果的分析,也建议取消共享,修改方式参考J6E/M“模型改造”章节。
例如下面的共享模块,量化表示的最大值为 128 * 0.0446799 ≈ 5.719,在第一次使用中,输出范围明显小于 [-5.719, 5.719],误差较小, 第二次使用中,输出范围超出 [-5.719, 5.719],数值被截断,产生了较大误差。两次数值范围的差异也造成了统计出的scale不准确,因此该共享模块必须修改
上面共享算子的修改方式可以参考:
对于不带权重的function类算子都可以参考上面的拆分方式,但是也存在部分共享算子或模块带有权重参数拆分起来比较复杂,是否需要拆分建议先根据量化敏感度进行分析。带有权重参数算子拆分时需要复制权重,拆分方式可以参考:
量化配置检查。txt文件中会给出模型量化精度的统计信息:
算子输出量化精度统计
+---+--+--+--+
| module type | torch.float32 | qint8 | qint16 |
|---+--+--+--+
| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 0 | 123 | 182 |
...
使用fp16量化精度的算子,量化精度统计
| module type | torch.float32 | qint8 | qint16 | torch.float16 |
|-----+--+--+--+--|
| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 34 | 0 | 0 | 0 |
| <class 'torch.nn.modules.padding.ZeroPad2d'> | 0 | 11 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 48 | 14 | 9 | 50 |
...
重点检查的信息有:
- a. 每层算子的输入输出dtype、权重的dtype,是否符合量化配置;若和量化配置不符合,比如配置了int16,但是算子显示为int8,则需要关注下算子回退信息,例如在旧模板下Conv+Add融合时Conv不支持int16输入,会导致前序算子输出回退到int8。新的qconfig量化配置模板下算子回退过程需查看qconfig_changelogs.txt,详细参考:https://developer.horizon.auto/blog/13112
b. 配置了fix scale的算子,是否正确显示FixedScaleObserver信息,scale值是否正确
c. 逐层算子的observer是否正确:权重默认MinMaxObserver,QAT校准时激活默认MSEObserver,QAT训练时激活默认MinMaxObserver
d. 若为QAT训练阶段且配置了固定校准的激活scale,查看averaging_constant,判断是否生效,生效为averaging_constant=0(即不更新scale),默认为0.01(更新scale)
重点关注的Graph信息:
- opcode为算子调用类型
- name为当前算子名称,需注意和model_check_result.txt中的module.submodule名称区别
- target为算子输出
- args为算子输入
2. QAT校准
2.1 int8+int16+fp16混合精度调优
如果模型中吸收了前后处理的相关算子和操作,这部分默认需要fp16精度进行量化
- 基础配置: TAE算子(Conv/Matmul/Linear)双int8、其他算子fp16、Sin/Cos算子fp32
- 精度优化配置: TAE算子(Conv/Matmul/Linear)单int16(部分双int16)、其他算子fp16、Sin/Cos算子fp32
- 精度上限配置: TAE算子(Conv/Matmul/Linear)双int16、其他算子fp16、Sin/Cos算子fp32
- 性能上限配置: 全局int8,建议仅在测试模型最优性能(精度无保证)或作为高精度耗时优化的对比参考时配置
基础配置下,回退fp16性能瓶颈算子到低精度int8
精度优化配置下,回退双int16的TAE算子到单int16,回退fp16性能瓶颈算子到低精度int8
对于不同精度配置下的QAT校准,都有一些校准超参可以调整,需要用户结合具体模型去做调参优化,其中主要的参数有校准数据的batch size、校准的steps,详细的参数参考:
- 基础调优手段:调优指南_基础调优手段
- 高级调优手段:调优指南_高级调优手段
由于J6H/P平台使用了较多浮点FP16精度,该精度下数值范围超限场景有以下常见的优化方法和优缺点总结:
方案 | 优点 | 缺点 |
|---|---|---|
直接手动 clip(仅数值范围超限) | 1. 简单有效 | 1. 适用范围有限(grid 范围,sum 等) |
使用 FP32 | 1. 直接有效 2. 方便流程自动化 | 1. 当前算子的输入输出都需要 FP32,bpu支持的算子范围小 2. 最坏情况下,需要设置多个连续的 FP32 算子,量化模型性能存在风险 |
回退 int16 | 1. 在某些值域范围内,表示精度高于 FP16 | 1. 存在 INT16 和 FP16 交错出现的情况,会出现较多 quant/dequant,存在性能风险 2. 出现截断时,需要手动设置固定 scale |
放缩 | 1. 性能优于 FP32 | 1. 需要手动修改模型结构,难以自动化 2. 仅适用线性变化 |
int8+int16+fp16混合精度调优的重点应放在TAE双int16+其他算子fp16的调优上,这里需要把使用问题,量化不友好模块等等各种千奇百怪的问题都解决,看到模型的精度上限,然后根据模型部署的性能要求进行TAE int8和int16混合精度的调优,最后对非TAE算子进行int8+fp16混合精度的调优,最终达成部署精度和部署性能的平衡。
2.2 Debug产出物解读
2.2.1 Badcase调优
对于实车或回灌反馈的可视化badcase,利用Debug工具的调优流程为:
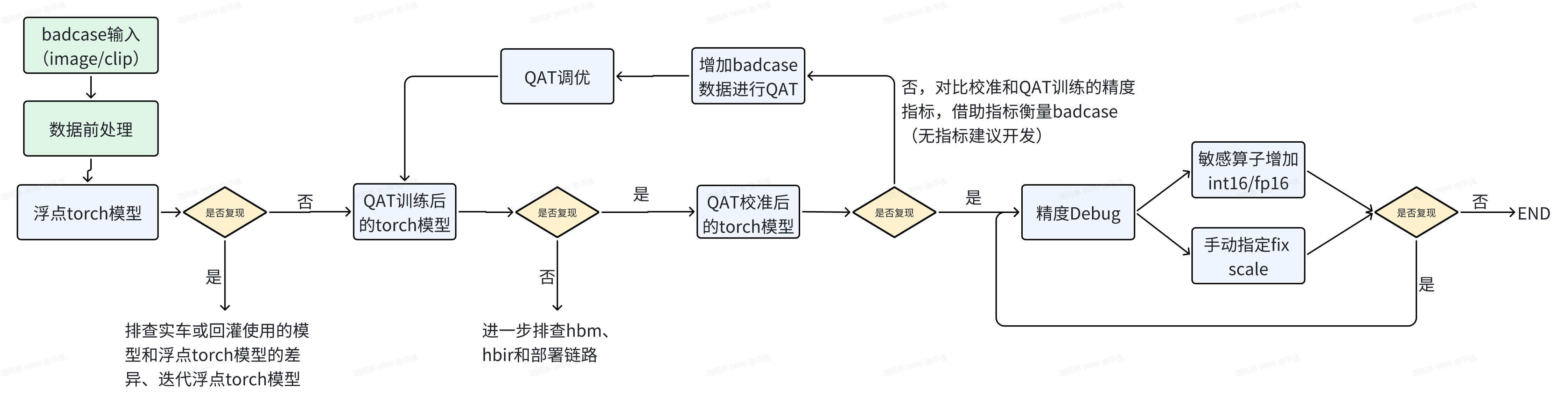
3. QAT训练
大部分模型仅通过QAT校准就可以获得较好的量化精度,对于部分较难调优的模型,以及还需要继续优化误差类指标的模型,通常校准设置的高精度比例导致延时超过部署上限,但精度仍无法达标,这种情况可以尝试QAT训练来获得满足预期性能-精度平衡的量化模型。
参考浮点训练,QAT训练在大部分配置保持和浮点训练一致的基础上,也涉及到部分超参的调整来提升量化训练的精度,例如QAT的学习率、weight_decay、迭代次数等,详细的参数调整策略参考:
- 基础调优手段:调优指南_基础调优手段
- 高级调优手段:调优指南_高级调优手段
浮点和QAT训练中都涉及到对BN的状态控制,在浮点训练中可能会采用FreezeBN fine-tune的方式来提升模型精度,在多任务训练中也会采用FreezeBN的技巧。因此在QAT训练中,提供了FuseBN和WithBN两种训练方式:
FuseBN即在Prepare后,QAT训练前将BN的weight和bias吸收到Conv的weight和bias中,在训练过程中不再单独更新,这一吸收过程是无损的。FuseBN也是QAT默认的训练方式。
WithBN则是在QAT训练阶段保持Conv+BN不融合,带着BN进行训练,BN的参数单独更新,在训练结束后转成部署模型时再做融合。浮点训练阶段如果采用了FreezeBN的训练方式,QAT训练时需设置WithBN来对齐浮点训练方式,设置方式如下:
通过观察QAT训练过程的Loss变化来初步判断QAT训练的量化效果,一般来说和浮点最后的Loss结果越接近越好,Loss过大可能难以收敛,Loss过小可能影响泛化性,对于异常的Loss建议的优化手段:
异常INF和NAN的Loss值,或者初始Loss极大且无收敛迹象,按如下顺序排查:
a. 去掉 prepare 模型的步骤,用 qat pipeline finetune 浮点模型,排除训练 pipeline 的问题,Loss如果仍异常,需要检查训练链路的配置如优化器optimizer和lr_updater等
b. 保持当前QAT训练配置,只关闭伪量化节点后观察训练的Loss现象,理论上和浮点有微小差异
c. lr 设置为 0,进行 qat 训练,排除参数调整不到位的问题。qat 训练的精度应该与 calibration 精度几乎一致
d. 此外还需要检查是否使用了特殊的数据增强策略(如旋转、马赛克等会改变真实的数据分布)
在排查完链路问题后出现初始Loss较大,有收敛迹象但收敛较慢,这种情况可以尝试调整学习率,延长QAT迭代次数,因为QAT训练本质上是对已收敛浮点模型的fine-tune,本身存在一定的随机性,用较大的学习率可以快速波动到一个理想精度(依赖一些中间权重的评测)
- 对于少数模型,QAT训练以及尝试了多次超参调整后精度仍无法达标,建议回归QAT校准阶段增加少量高精度算子(增加GEMM类算子int16,以及其他算子增加FP16)、回归浮点结构检查是否还存在量化不友好的结构如使用了大量GeLU等(参考J6E/M精度调优对应章节【地平线 J6工具链进阶教程】J6 E/M工具链QAT精度调优)
3.1 QAT训练效率
由于QAT训练过程需要感知模型量化所带来的损失,因此模型中会被插入必要的量化相关的节点:数据观测节点Observer和伪量化节点FakeQuant。数据观测节点会不断统计模型中数据的数值范围,伪量化节点会根据量化公式对数据做模拟量化和反量化,两者都会存在开销,此外就是QAT工具内部会对部分算子例如LN层做拆分算子的实现,因此相同配置下的QAT训练效率是会略低于浮点训练效率,具体还和模型参数规模、算子数量等有关。
对于用户可明显感知到的QAT训练效率降低,建议的优化手段有:
- 使用QAT工具提供的算子,这些算子优化了训练效率,例如MultiScaleDeformableAttention(参考手册 )
更新到最新的horizon-plugin-pytorch版本,新版本会有持续的bug fix和新特性优化,如模型中某些结构或者算子训练耗时增加明显,可以向工具链团队导入
4. 模型导出部署
PyTorch模型 -> export -> convert-> compile
export得到qat.bc;
convert得到quantized.bc;
compile得到hbm
调优技巧
1. 分部量化
下面这种方式仅适用于 Calib 阶段,QAT 阶段因为模型已经适应了量化误差,关闭伪量化精度无法保证
2. 部分层冻结下的QAT训练
模型 QAT 训练时,要求模型为 train() 状态,此时若部分层冻结,则需要对应修改状态,参考代码如下:
3. Calib/QAT过程NaN值定位
出现NaN值可通过下面的修改在calib/qat forward过程中报错,从而定位到具体的算子:
常见的可能出现NaN值的结构:
- Multi-head Attention的attn mask,需要手动做数值的clamp



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)