
前言
本文将对KV Cache量化技术进行介绍。
KV Cache的介绍请查看【手撕大模型】KVCache原理及代码解析。
KV Cache量化技术介绍
对象 | 特点 | 量化挑战 |
权重 (Weights) | 固定不变,可离线量化、校准 | 量化噪声可被模型学习到 |
激活 (Activations) | 每次前向变化大 | SmoothQuant、AWQ 等方法 |
KV Cache | 激活的一部分(注意力Key/Value)且跨 token 持续使用 | 分布动态、层间差异大,不能重新校准 |
KVQuant
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
现有LLM量化方法虽然有做 activations 或 weights 的量化,但专门针对 KV Cache、并且做到亚 4 位(比如 3-bit、2-bit)却效果不好/几乎没有/存在明显精度损失。
论文提出了一系列创新,主要针对 Key 和 Value 的激活缓存的特点设计。下面将按方法点逐个说明。
方法细节
Per-Channel Key Quantization
这样做的好处:对 outlier 较严重的通道可以给出较大范围,而通道分布较窄的可以用更窄的量化范围/更细的刻度,从而整体量化误差更小。
Pre-RoPE Key Quantization
在 Transformer 架构中,很多模型使用 RoPE(Rotary Positional Embedding)来给 Key/Query 注入位置编码。RoPE 会导致通道维度之间的“旋转”/混合关系。
Non-Uniform KV Cache Quantization
换而言之:某些层或通道如果对量化误差敏感,经校准后可能使用更多刻度(或更大位宽),而其他低敏感的可用更粗糙的量化,这样整体在给定比特预算下误差更小。
Per-Vector Dense-and-Sparse Quantization
Q-Norm 与其他细节
在 reddit/摘要中还提及 “Q-Norm” 的名字:虽然在主方法里可能不是核心标题,但确实是一种细化策略,用于确保量化之后激活分布偏移(shift)控制得更好。
实验结果与意义
KVQuant在多个模型(如 LLaMA‑7B、Llama‑2、Llama‑3、Mistral)上进行了测试。
- 在标准语言模型 benchmark(如 Wikitext‑2、C4)上:使用 3-bit 量化 的 KV Cache,困惑度(perplexity) 的退化控制在 < 0.1。在部署上,他们声称实现了:单张 A100-80GB GPU 上用 LLaMA-7B 支持 1 百万(1 M)token 上下文长度,8 GPU 系统支持 10 百万(10 M)token。
- 在速度方面,在 LLaMA-7B 模型上配合自定义 kernel,实现最大约 1.7× 加速(相比 FP16 baseline 的 matrix-vector)理想。
KVQuant提供了将 KV Cache 从传统 FP16/FP32 精度降低到极低位宽(如 3-bit)而几乎不损失质量的方法,为「超长上下文」LLM 推理(数百万、数千万 token)提供了实用的内存/带宽优化路径,铺垫了后续更多 KV Cache 量化、压缩、系统层部署优化工作的基础。
KVQuant在Hugging Face 中使用示例
Quanto
Quanto 对 KV cache 的量化是 Hugging Face 最近(从 Transformers v4.43 起)引入的一项关键特性,用来在推理时显著降低 KV 缓存显存开销。它的特点有:
- 支持 动态量化(activations, KV cache)
- 支持 静态量化(权重)
支持多种 bit 宽:2 / 4 / 8-bit
- 提供 PyTorch 张量级 API(无需修改模型结构)
- 与 Transformers + Accelerate 完全兼容
Quanto 的量化原理(以 4-bit 为例)
对于每个注意力头的 KV 矩阵:
分块量化(block-wise quantization)
将矩阵切分为小块(默认 32 或 64 行),每块单独量化。这样做的优点是局部统计更准确;支持快速 dequant以及兼容 int kernel。其工作流程如下:

Per-block scale + zero-point
- 每块保存一个 scale 和 zero_point,用于还原:
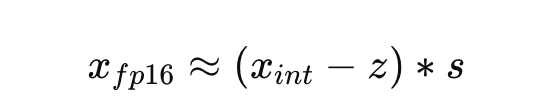
INT4 仅需 4 bit 存储,外加少量 scale 元数据。
实时反量化访问
- 推理时(如 torch.matmul),Quanto 提供高效 CUDA kernel,直接在量化表示上完成部分计算(避免完全解码)。
其核心代码为:
Quanto Hugging Face 中使用示例
参考链接
https://zhuanlan.zhihu.com/p/5932153295
https://arxiv.org/abs/2401.18079

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)