
1.模型性能评价指标
1.1延时
1.2模型带宽
在perf文件中有一个模型平均带宽的数字,但这个数字与实车实际所需带宽偏差还是比较大的,因为这个带宽需求是基于模型无资源限制,满帧率运行评估出来的。建议按照如下方式计算实车模型平均带宽:
平均带宽(GB/s) = [DDR bytes per second( for n FPS)] / n * 设计帧率 / 2^30
以下面这个模型为例,实车设计帧率为10FPS,则实车时该模型需要的平均带宽为:
68138917200/10.39*10/2^30 = 61.08GB/s

这样更能贴合实车情况汇总得到整个系统所需带宽,并找到真正的主要带宽瓶颈模型。
2.性能分析
2.1工具简介
pip3 install OE/package/host/ai_toolchain/hbdk4_runtime_aarch64_unknown_linux_gnu_nash-{version}-py3-none-any.whl
dynamic perf:依据板子实测打点回传校准perf layer的耗时(在没有cpu的情况下,预期可做到与实测偏差不超过1ms)
2.2建议流程
建议按如下流程使用分析工具:

完整流程均集成在了下面这个脚本当中,后文仅简述如何利用各个产物分析模型性能瓶颈:
如下为传入qat.bc和hbm的输出示例:
2.3关注模型中是否有cpu算子
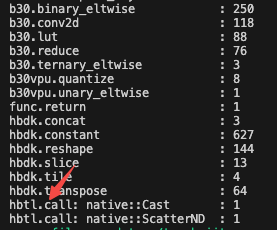
若使用前文的分析脚本,传入qat.bc或者hbm都会帮助检查是否有cpu算子:
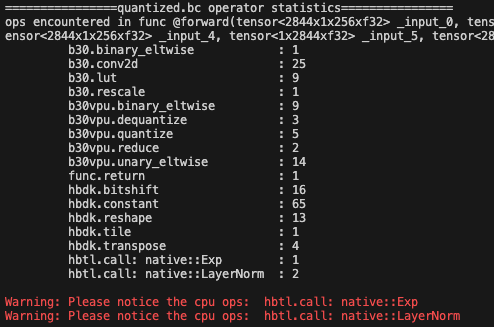
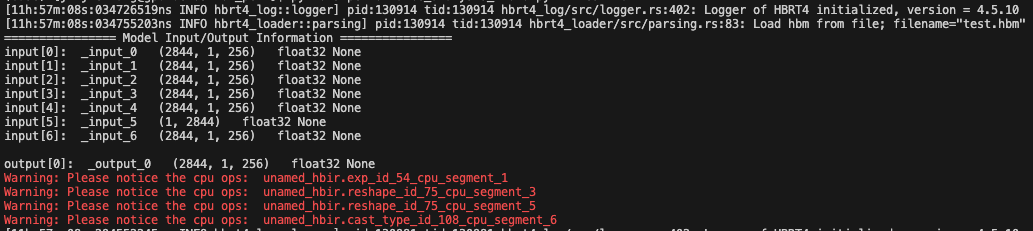
若hbm中检查出的cpu算子名字中包含resizer关键字,则可忽略,resizer输入节点需要生成 jit 指令。
2.4分析高精度conv的配置情况
若是已经进行了量化调优的模型,且高精度引入了较多延时开销,可以关注一下高精度算子的比例,并尝试尽可能减少对计算量大的conv like算子配置输入int16。
使用分析脚本会打印模型中conv like算子的精度配置情况:
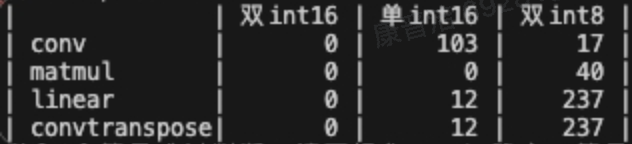
再配合perf json file的解析结果,可了解到模型需要重点减少哪部分算子的高精度配置比例:
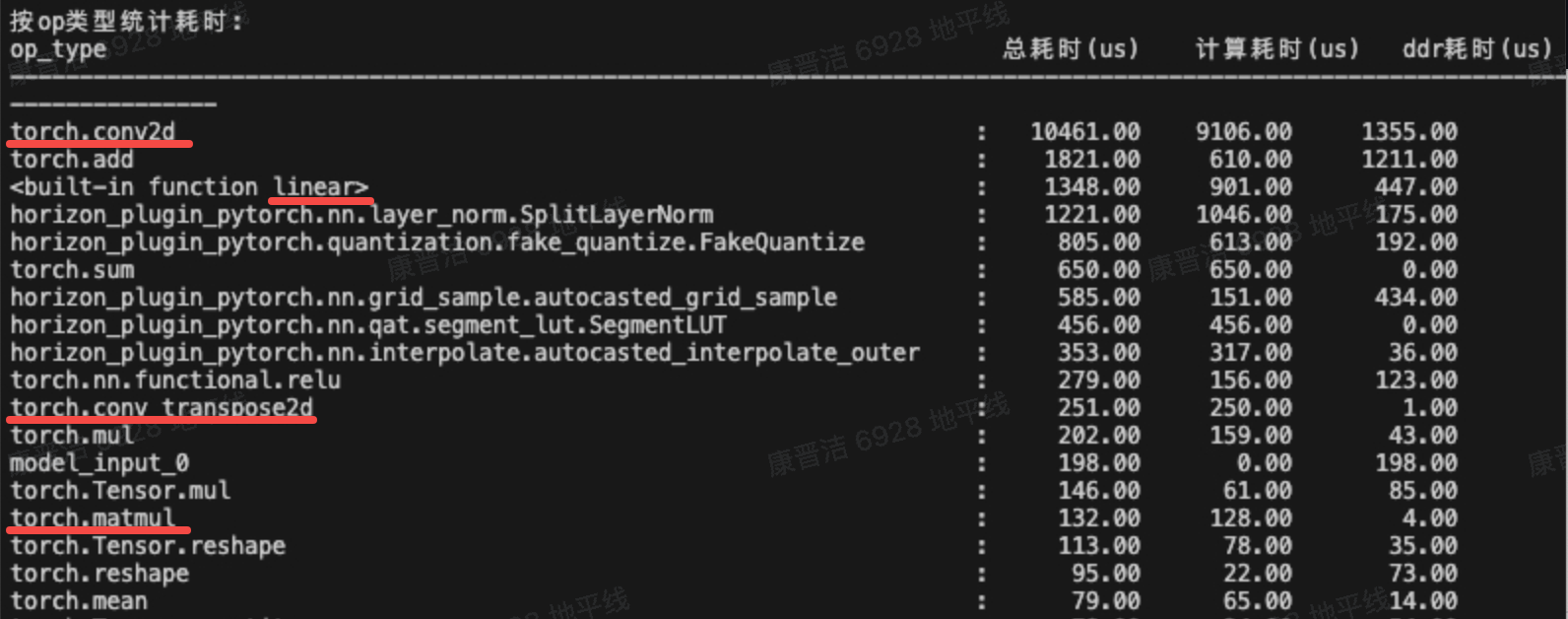
有一些shape较大的conv like算子配置高精度后延时会激增,可通过脚本中统计耗时排名靠前的算子找到对应信息,并做针对性优化。

2.5分析瓶颈结构
hbm perf最终会生成一个html文件和一个json文件,结合html文件和二次处理后的json文件信息里,我们可以分析得到模型的瓶颈结构:
1.大段空白
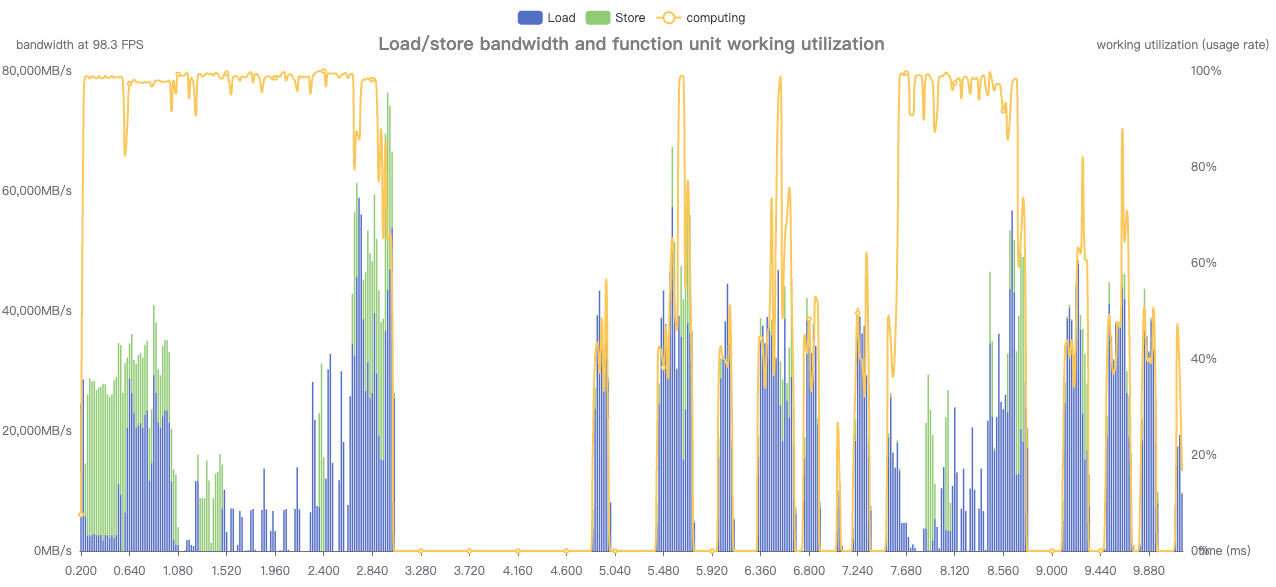
当前spu和cpu计算是无法获取source layer信息的,如果已经确定模型没有cpu算子,空白的地方大概率就是topk和sort算子(当前J6P只释放了这两个spu算子),如果是模型尾部的topk计算,建议直接删除用c++做,如下模型,topk挪到后处理代码里实现后,模型延时减少了4ms,cpu占用增加非常少;若是模型中间的topk算子,一方面是想办法缩减topk输入shape,第二方面上尝试减少输出k的数量。
2.卡带宽
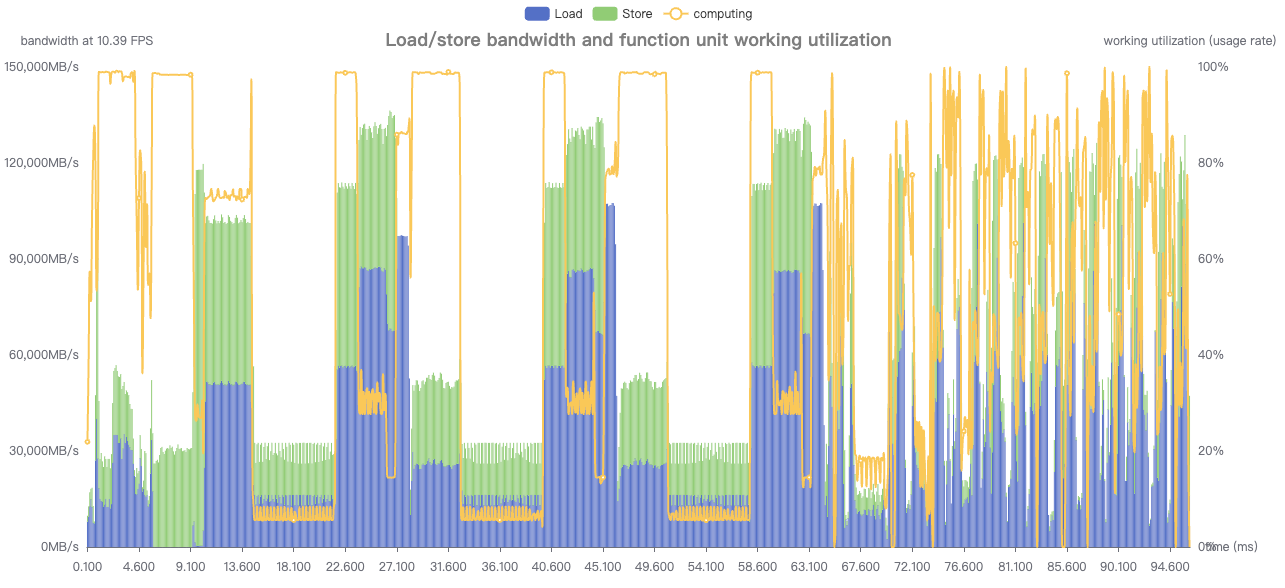
观察html里Temporal Statistics以及json文件中解析出来每类算子的计算带宽情况,可知模型在哪段结构/哪些算子上卡带宽了:
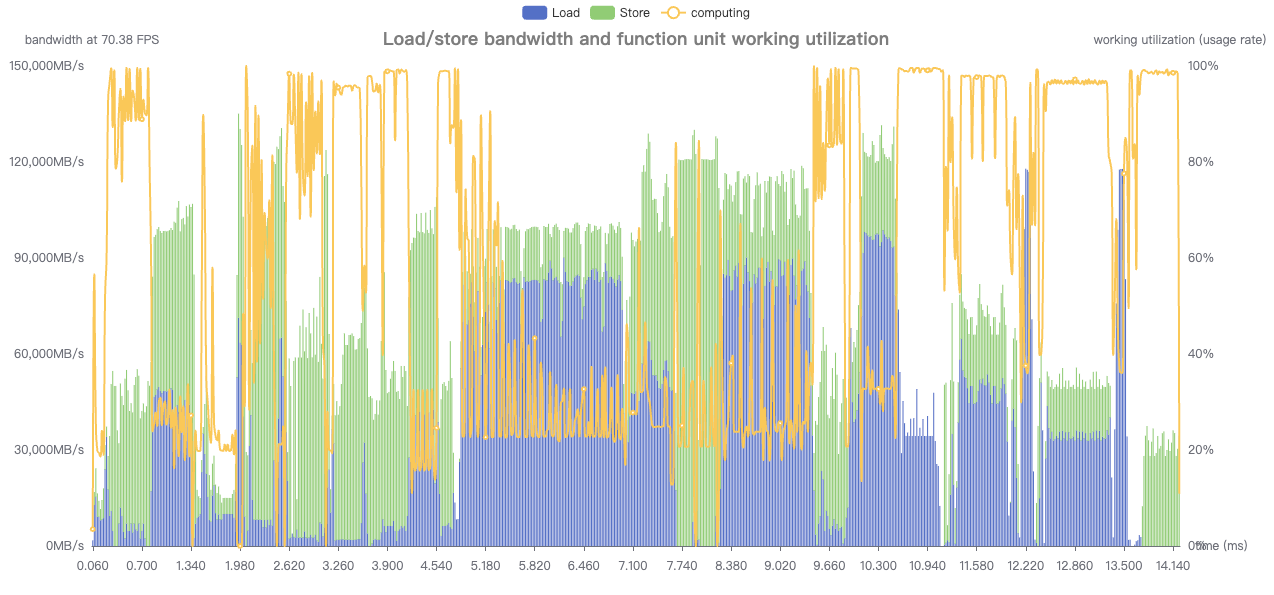
从这个图可以看到computing折线较低的地方,load store都较高,很明显是因为卡带宽导致计算受限。
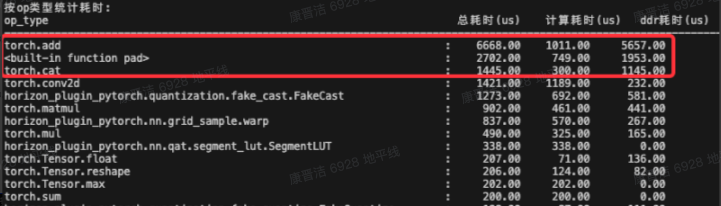
结合统计结果发现卡带宽的是这三个算子:add,pad,cat
从layer details表格里查看load/store cost远大于computing的算子

再查看模型结构可知卡带宽是因为多个vision拼接得到bev特征的操作不够高效,不断使用expand算子将尺寸较小的tensor升维与大尺寸tensor相加/concat。通过调整融合顺序,去掉使用expand算子,模型延时减少了3ms。
3.conv类计算利用率不高,或者本身conv类计算就太少
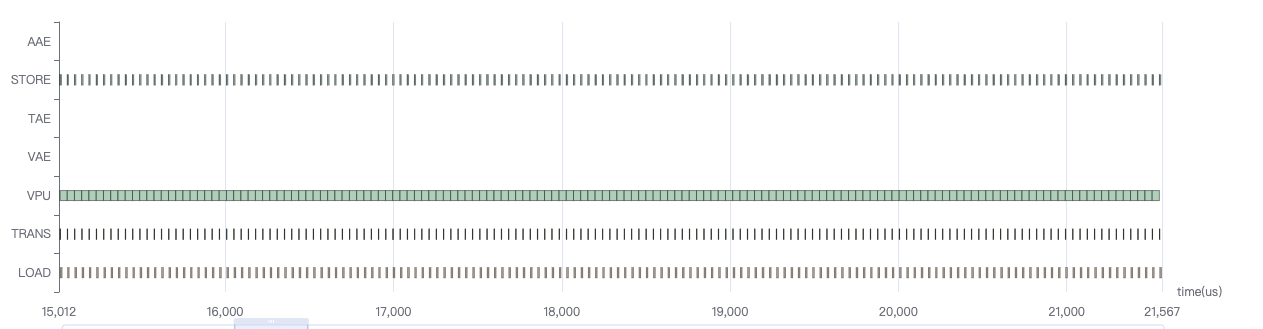
computing折线只统计了TAE器件的计算,因此computing折线下降,可能是因为其他计算器件的运行时间太长了,且无法与TAE并行。
如上图所示,有部分结构computing折线较低的地方,load/store开销也不大,观察时序图可发现是vpu器件运行时间太长,与TAE并行度不高,此时要想办法减少vpu上的计算,挪到其他器件上或者直接去掉。
4.其他
从Temporal Statistics和Timeline上已经很难找到明显瓶颈的话,就需要直接可视化quantized.bc依据经验找可优化的结构了:
看看是否有冗余的类型转换,或者没必要的高精度配置;
a.J6E/M使用新qconfig模板配置,前一个算子的输出和下一个算子输入dtype不一致时会引入rescale算子,存在耗时,对于耗时比较大的rescale可以考虑修改量化配置,统一dtype
依据算法经验判断某个结构物理含义上是否就不会超过int8,可避免使用int16/fp16
结合硬件对齐规则,看是否有h/w/c维度特别小,远不满足硬件对齐要求的算子;
算子 | 参数 | 对齐规则 |
Conv (group conv每组内都有对齐要求) | Kernel 1x1 | input channel 64 output channel 64 |
Kernel 3x3 stride 1 | input channel 8 output channel 32 | |
Kernel 3x3 stride 2 | input channel 8 output channel 64 | |
Kernel 5x5 | input channel 8 output channel 16 | |
warp/gather | - | 32C |
从数学原理上考虑等价优化:
模块输出部分通过slice裁剪feature大小的操作可以考虑前移;
充分利用elementwise的广播特性,减少前端expand
若以上都没有,就需要从算法角度考虑裁剪结构/模型容量了。
3.性能优化
3.1cpu算子清零
由于J6P支持较多浮点计算以及不同计算精度之间的相互切换,所以并非所有fp32的算子都会被回退cpu,除了算子约束中明确不支持的算子外,常见的cpu算子主要是下面三类:
1.Scatternd
详情请见社区文章:
Onnx中ScatterND的产生与去除 - 地平线开发者社区
2.int64 index
此外如果对延时没有比较高的要求,也可以不改源码,导出qat.bc之后,用下面代码把模型里int64的数据替换成int32即可,也可避免因为int64计算引入cpu cast:
3.高精度的resize,warp等硬件不支持的算子
3.2构建量化友好的浮点,减少高精度配置的需要
- 对输入做关于0对称的归一化。雷达点云以及部分有明确物理含义的输入,通常原始数值都较大,建议这类输入都做一下归一化再送入模型,可一定程度上有效降低量化难度。
- 尽可能在每个conv like算子后面加bn,避免数值被放大。
- 部分relu换relu6,进一步控制数值范围。
- mask不要使用1e10,65536等过大的数字,一般给100(以能起到区分作用,不影响浮点精度为准),或者30000(能让softmax后的值为1就行),不要超过fp16数值范围,否则导出或者qat的时候会出现问题。
3.3提高bpu内各个器件的并行度及利用率
1.卡带宽的常见原因
- 算子的原因:
比如warp算子,数据局部性不好(访问的输入数据可能在内存中不是连续的),不好做Tiling;
大量使用concat,pad,slice等对layout要求较高的算子,容易导致数据量膨胀;
- 模型结构的问题:
模型结构较"宽":需要同时alive的tensor较多,L1M放不下;
模型结构太"长":如shortcut跨层太多,数据无法长时间驻留在L1M
2.优化建议
对于warp算子,如果有多个尺寸相同的并行结构,建议沿着batch合并,因为warp只有沿着batch拆分是等价的,h和w都无法拆分,沿着batch维度合并可提高利用率;此外,在满足32C对齐的情况下,减小feature channel大小也能明显减少warp耗时。
对于concat,pad,slice算子,建议尽可能减少和避免使用,比如利用elementwise广播的特性,减少手动使用expand对齐tensor形状等。
vpu/vae瓶颈明显:
- softmax:sima替换self-attention(论文:https://arxiv.org/pdf/2206.08898)
- layernorm:Dyt替换layernorm(论文:https://arxiv.org/abs/2503.10622)
尽量避免使用fp32精度,fp32只能运行在vpu上,vpu算力相较于vae和tae小了好几个数量级,且fp32相较于fp16/int16带宽需求膨胀了一倍
其他优化建议阅读:
【地平线J6工具链进阶教程】算子优化方案集锦 - 地平线开发者社区



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)