
9.2.1. 概述
本文档主要介绍了地平线天工开物工具链Runtime的API、数据、结构体、排布及对齐规则等。 通过阅读本文档,用户可以在Horizon开发板上利用API完成模型的加载与释放,模型信息的获取,以及模型的推理等操作。
9.2.2. 数据类型和数据结构
9.2.2.1. 版本信息类¶
注解
注意,本小节中的版本信息类型的版本号随版本变化有所不同,此处的版本号仅供参考,实际版本请以您获取到的发布物为准。
9.2.2.1.1. HB_DNN_VERSION_MAJOR¶
DNN主版本号信息。
9.2.2.1.2. HB_DNN_VERSION_MINOR¶
DNN次版本号信息。
9.2.2.1.3. HB_DNN_VERSION_PATCH
DNN补丁版本号信息。
9.2.2.2. 模型类¶
9.2.2.2.1. HB_DNN_TENSOR_MAX_DIMENSIONS
张量最大的维度设置为 8。
9.2.2.2.2. HB_DNN_INITIALIZE_INFER_CTRL_PARAM
初始化控制参数。
9.2.2.2.3. hbPackedDNNHandle_t¶
DNN句柄,指向打包的多个模型。
9.2.2.2.4. hbDNNHandle_t
DNN句柄,指向单一模型。
9.2.2.2.5. hbDNNTaskHandle_t
任务句柄,指向一个任务。
9.2.2.2.6. hbDNNTaskDoneCb¶
用户自定义任务完成后需要执行的回调函数。
参数
[in] taskHandle 任务句柄指针。
[in] status 任务返回的状态码。
[in] userdata 用户自定义的数据。
9.2.2.2.7. hbDNNTensorLayout¶
张量的排布形式。
NHWC 分别代表Number、Height、Width和Channel。
成员
成员名称 | 描述 |
|---|---|
HB_DNN_LAYOUT_NONE | 没有定义排布形式。 |
HB_DNN_LAYOUT_NHWC | 排布形式为 NHWC。 |
HB_DNN_LAYOUT_NCHW | 排布形式为 NCHW。 |
9.2.2.2.8. hbDNNDataType¶
张量的类型。
S 代表有符号, U 代表无符号, F 代表浮点型,后面的数字代表bit数。
HB_DNN_IMG_TYPE_NV12 与 HB_DNN_IMG_TYPE_NV12_SEPARATE 都代表NV12的数据,只是在存储上有差异。
成员
成员名称 | 描述 |
|---|---|
HB_DNN_IMG_TYPE_Y | 张量类型为仅有Y通道的图片。 |
HB_DNN_IMG_TYPE_NV12 | 张量类型为一张NV12的图片。 |
HB_DNN_IMG_TYPE_NV12_SEPARATE | 张量类型为Y通道及UV通道为输入的图片。 |
HB_DNN_IMG_TYPE_YUV444 | 张量类型为YUV444为输入的图片。 |
HB_DNN_IMG_TYPE_RGB | 张量类型为RGB为输入的图片。 |
HB_DNN_IMG_TYPE_BGR | 张量类型为BGR为输入的图片。 |
HB_DNN_TENSOR_TYPE_S4 | 张量类型为有符号4bit。 |
HB_DNN_TENSOR_TYPE_U4 | 张量类型为无符号4bit。 |
HB_DNN_TENSOR_TYPE_S8 | 张量类型为有符号8bit。 |
HB_DNN_TENSOR_TYPE_U8 | 张量类型为无符号8bit。 |
HB_DNN_TENSOR_TYPE_F16 | 张量类型为浮点型16bit。 |
HB_DNN_TENSOR_TYPE_S16 | 张量类型为有符号16bit。 |
HB_DNN_TENSOR_TYPE_U16 | 张量类型为无符号16bit。 |
HB_DNN_TENSOR_TYPE_F32 | 张量类型为浮点型32bit。 |
HB_DNN_TENSOR_TYPE_S32 | 张量类型为有符号32bit。 |
HB_DNN_TENSOR_TYPE_U32 | 张量类型为无符号32bit。 |
HB_DNN_TENSOR_TYPE_F64 | 张量类型为浮点型64bit。 |
HB_DNN_TENSOR_TYPE_S64 | 张量类型为有符号64bit。 |
HB_DNN_TENSOR_TYPE_U64 | 张量类型为无符号64bit。 |
HB_DNN_TENSOR_TYPE_MAX | 代表最大的张量类型编号。 |
9.2.2.2.9. hbDNNTensorShape¶
张量的形状。
例如一张224x224的bgr彩色空间的图片 numDimensions=4,若排布形式为NHWC, 则 dimensionSize 数组中按顺序存储图片 Number=1、 Height=224、 Width=224、 Channel=3。
成员
成员名称 | 描述 |
|---|---|
dimensionSize | 张量每个维度的大小。 |
numDimensions | 张量的维度。 |
9.2.2.2.10. hbDNNQuantiShift¶
量化/反量化的移位数据。
对于输入 :若采集到浮点数据 data[i], 对应的移位数据是 shift[i], 则送入模型的推理数据为: data[i]∗(1<<shift[i]) 取整;
对于输出 :若推理结果 data[i], 对应的移位数据是 shift[i], 则最终的推理结果为: data[i]/(1<<shift[i])。
其中 shiftLen 由数据 data 按照 per-axis 或 per-tensor (反)量化方式决定。 当数据 data 按 per-tensor (反)量化时, shiftLen 等于 1,此时不需要关注 quantizeAxis 数值; 否则等于数据 data 的第 quantizeAxis 维度大小。
成员
成员名称 | 描述 |
|---|---|
shiftLen | 移位数据的长度。 |
shiftData | 移位数据的首地址。 |
9.2.2.2.11. hbDNNQuantiScale¶
量化/反量化的缩放数据。
对于输入 :若采集到浮点数据 data[i], 对应的缩放数据是 scale[i], 零点偏移数据是 zeroPoint[i],则送入模型的推理数据为: g((data[i]/scale[i])+zeroPoint[i]) , 其中: g(x)=clip(round(x)), 截断到:U8: g(x)∈[0,255], S8: g(x)∈[−128,127];
对于输出 :若推理结果 data[i], 对应的缩放数据是 scale[i], 零点偏移数据是 zeroPoint[i],则最终的推理结果为: (data[i]−zeroPoint[i])∗scale[i]。
其中 scaleLen 由数据 data 按照 per-axis 或 per-tensor (反)量化方式决定。 当数据 data 按 per-tensor (反)量化时, scaleLen 等于 1,此时不需要关注 quantizeAxis 数值; 否则等于数据 data 第 quantizeAxis 维度大小。 zeroPointLen 与 scaleLen 保持一致。
成员
成员名称 | 描述 |
|---|---|
scaleLen | 缩放数据的长度。 |
scaleData | 缩放数据的首地址。 |
zeropointLen | 零点偏移数据的长度。 |
zeropointData | 零点偏移数据的首地址。 |
9.2.2.2.12. hbDNNQuantiType¶
定点浮点转换的量化/反量化类型。
NONE 代表不需要对数据做任何处理;
SHIFT 类型对应的量化/反量化参数存储在 hbDNNQuantiShift 结构体中;
SCALE 对应的量化/反量化参数存储在 hbDNNQuantiScale 结构体中。
成员
成员名称 | 描述 |
|---|---|
NONE | 没有量化。 |
SHIFT | 量化类型为 SHIFT。 |
SCALE | 量化类型为 SCALE。 |
9.2.2.2.13. hbDNNTensorProperties
张量的信息。
成员
成员名称 | 描述 |
|---|---|
validShape | 张量有效内容的形状。 |
alignedShape | 张量对齐内容的形状。 |
tensorLayout | 张量的排布形式。 |
tensorType | 张量的类型。 |
shift | 量化偏移量。 |
scale | 量化缩放量。 |
quantiType | 量化类型。 |
quantizeAxis | 量化通道,仅按per-axis量化时生效。 |
alignedByteSize | 张量对齐内容的内存大小。 |
stride | 张量中validShape各维度步长。 |
注解
通过接口获取的张量信息为模型要求的,您可以根据实际输入修改对应的张量信息,目前只允许修改 alignedShape 和 tensorType 的信息,而且必须符合要求。
alignedShape:
若您根据 alignedShape 准备输入,则无需更改 alignedShape 。
若您根据 validShape 准备输入,则需更改 alignedShape 为 validShape ,推理库内部会对数据进行padding操作。
tensorType:
推理NV12输入的模型时,您可根据实际情况更改张量的 tensorType 属性为 HB_DNN_IMG_TYPE_NV12 或 HB_DNN_IMG_TYPE_NV12_SEPARATE 。
9.2.2.2.14. hbDNNTaskPriority
Task优先级配置,提供默认参数。
9.2.2.2.15. hbDNNTensor
张量。
用于存放输入输出的信息。其中 NV12_SEPARATE 类型的张量需要用2个 hbSysMem,其余都为1个。
成员
成员名称 | 描述 |
|---|---|
sysMem | 存放张量的内存。 |
properties | 张量的信息。 |
9.2.2.2.16. hbDNNRoi
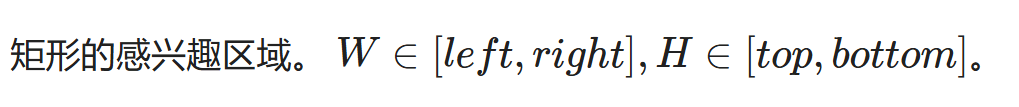
成员
成员名称 | 描述 |
|---|---|
left | 感兴趣区域左上点宽度像素点。 |
top | 感兴趣区域左上点高度像素点。 |
right | 感兴趣区域右下点宽度像素点。 |
bottom | 感兴趣区域右下点高度像素点。 |
9.2.2.2.17. hbDNNInferCtrlParam¶
模型推理的控制参数。
bpuCoreId 与 dspCoreId 用于控制推理模型BPU和DSP节点使用的核;目前DSP节点使用较少,dspCoreId 暂时作为占位符使用。
more 参数用于小模型批量处理场景,当希望所有任务都执行完再获得输出时,除最后一个任务设置 more 为 0 外, 之前的任务 more 都设置为 1,最多支持255个不同小模型的批量推理,小模型为resizer模型时,每一个roi都可能会被算作一个小模型。
customId 参数用于用户自定义优先级,定义task的优先级大小,例如:时间戳、frame id等,数值越小优先级越高。优先级:priority > customId。
成员
成员名称 | 描述 |
|---|---|
bpuCoreId | BPU核ID。 |
dspCoreId | DSP核ID。 |
priority | 任务优先级。 |
more | 该任务后续是否有跟随任务。 |
customId | 自定义优先级。 |
reserved1 | 保留字段1。 |
Reserved2 | 保留字段2。 |
9.2.2.3. 系统类
9.2.2.3.1. hbBPUCore¶
BPU核枚举。
成员
成员名称 | 描述 |
|---|---|
HB_BPU_CORE_ANY | 任意的BPU核。 |
HB_BPU_CORE_0 | BPU核0。 |
HB_BPU_CORE_1 | BPU核1。 |
9.2.2.3.2. hbDSPCore¶
DSP核枚举。
成员
成员名称 | 描述 |
|---|---|
HB_DSP_CORE_ANY | 任意的DSP核。 |
HB_DSP_CORE_0 | DSP核0。 |
HB_DSP_CORE_1 | DSP核1。 |
9.2.2.3.3. hbSysMem¶
系统内存结构体,用于申请系统内存。
成员
成员名称 | 描述 |
|---|---|
phyAddr | 物理地址。 |
virAddr | 虚拟地址。 |
memSize | 内存大小。 |
9.2.2.3.4. hbSysMemFlushFlag¶
系统内存与缓存同步参数。
CPU与内存之间有一个缓存区,导致缓存中内容与内存中内容会出现不同步的情况,为了每次都能够拿到最新的数据, 我们需要在CPU读前、写后进行数据更新。CPU读前,将内存中数据更新到缓存中。CPU写后,将缓存中数据更新到内存中。
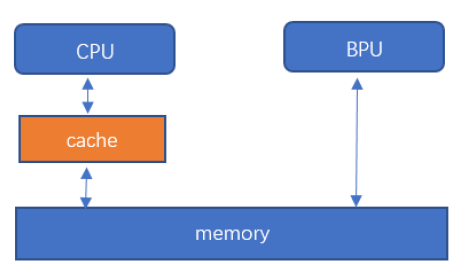
成员
成员名称 | 描述 |
|---|---|
HB_SYS_MEM_CACHE_INVALIDATE | 将内存同步到缓存中,CPU读前使用。 |
HB_SYS_MEM_CACHE_CLEAN | 将缓存数据同步到内存中,CPU写后使用。 |
9.2.2.4. 插件类
9.2.2.4.1. hbDNNLayerCreator¶
用户自定义Layer创建方法。
9.2.3. API接口¶
9.2.3.1. 版本信息¶
9.2.3.1.1. hbDNNGetVersion()¶
获取 DNN 预测库版本信息。
返回值
返回版本信息。
9.2.3.2. 模型加载/释放¶
9.2.3.2.1. hbDNNInitializeFromFiles()
从文件完成对 packedDNNHandle 的创建和初始化。调用方可以跨函数、跨线程使用返回的 packedDNNHandle。
参数
[out] packedDNNHandle Horizon DNN句柄,指向多个模型。
[in] modelFileNames 模型文件的路径。
[in] modelFileCount 模型文件的个数。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.2.2. hbDNNInitializeFromDDR()
从内存完成对 packedDNNHandle 的创建和初始化。调用方可以跨函数、跨线程使用返回的 packedDNNHandle。
参数
[out] packedDNNHandle Horizon DNN句柄,指向多个模型。
[in] modelData 模型文件的指针。
[in] modelDataLengths 模型数据的长度。
[in] modelDataCount 模型数据的个数。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.2.3. hbDNNRelease()
将 packedDNNHandle 所指向的模型释放。
参数
[in] packedDNNHandle Horizon DNN句柄,指向多个模型。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3. 模型信息
9.2.3.3.1. hbDNNGetModelNameList()
获取 packedDNNHandle 所指向模型的名称列表和个数。
参数
[out] modelNameList 模型名称列表。
[out] modelNameCount 模型名称个数。
[in] packedDNNHandle Horizon DNN句柄,指向多个模型。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.2. hbDNNGetModelHandle()
从 packedDNNHandle 所指向模型列表中获取一个模型的句柄。调用方可以跨函数、跨线程使用返回的 dnnHandle。
参数
[out] dnnHandle DNN句柄,指向一个模型。
[in] packedDNNHandle DNN句柄,指向多个模型。
[in] modelName 模型名称。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.3. hbDNNGetInputCount()¶
获取 dnnHandle 所指向模型输入张量的个数。
参数
[out] inputCount 模型输入张量的个数。
[in] dnnHandle DNN句柄,指向一个模型。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.4. hbDNNGetInputName()
获取 dnnHandle 所指向模型输入张量的名称。
参数
[out] name 模型输入张量的名称。
[in] dnnHandle DNN句柄,指向一个模型。
[in] inputIndex 模型输入张量的编号。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.5. hbDNNGetInputTensorProperties()
获取 dnnHandle 所指向模型特定输入张量的属性。
参数
[out] properties 输入张量的信息。
[in] dnnHandle DNN句柄,指向一个模型。
[in] inputIndex 模型输入张量的编号。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.6. hbDNNGetOutputCount()¶
获取 dnnHandle 所指向模型输出张量的个数。
参数
[out] outputCount 模型输出张量的个数。
[in] dnnHandle DNN句柄,指向一个模型。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.7. hbDNNGetOutputName()
获取 dnnHandle 所指向模型输出张量的名称。
参数
[out] name 模型输出张量的名称。
[in] dnnHandle DNN句柄,指向一个模型。
[in] outputIndex 模型输出张量的编号。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.3.8. hbDNNGetOutputTensorProperties()¶
获取 dnnHandle 所指向模型特定输出张量的属性。
参数
[out] properties 输出张量的信息。
[in] dnnHandle DNN句柄,指向一个模型。
[in] outputIndex 模型输出张量的编号。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.4. 模型推理
9.2.3.4.1. hbDNNInfer()
根据输入参数执行推理任务。调用方可以跨函数、跨线程使用返回的 taskHandle。
参数
[out] taskHandle 任务句柄指针。
[in/out] output 推理任务的输出。
[in] input 推理任务的输入。
[in] dnnHandle DNN句柄指针。
[in] inferCtrlParam 控制推理任务的参数。
返回值
返回 0 则表示API成功执行,否则执行失败。
注解
使用该接口提交任务时应提前将 taskHandle 置为 nullptr,除非是给指定 taskHandle 追加任务(即使用 inferCtrlParam::more 功能)。
最多支持同时存在32个模型任务。
对于batch模型,允许分开设置输入张量的内存地址。例如:模型的输入validShape/alignedShape为[4, 3, 224, 224], 可以申请四个hbDNNTensor, 每个hbDNNTensor的validShape/alignedShape都设置为[1, 3, 224, 224],存放每个batch的数据。当模型有多个输入时, input 的顺序应为input0[batch0], input0[batch1], …, inputn[batch0], inputn[batch1], …。
9.2.3.4.2. hbDNNRoiInfer()
根据输入参数执行ROI推理任务。调用方可以跨函数、跨线程使用返回的 taskHandle。
参数
[out] taskHandle 任务句柄指针。
[in/out] output 推理任务的输出。
[in] input 推理任务的输入。
[in] rois Roi框信息。
[in] roiCount Roi框数量。
[in] dnnHandle dnn句柄指针。
[in] inferCtrlParam 控制推理任务的参数。
返回值
返回 0 则表示API成功执行,否则执行失败。
注解
概念说明:
input_count : 模型输入分支数量
output_count : 模型输出分支数量
resizer_count : 模型输入源为 resizer 的分支数量(≤input_count),模型处理一批数据时,一个 resizer 输入源分支处理一个 roi
roiCount : roi 总数,其数值应大于等于 resizer_count
data_batch : 模型需要推理的数据批数,其数值为 roiCount / resizer_count
model_batch : 模型内部的 batch 数量。即模型实际推理时,输入给模型的 batch_size。地平线工具链支持将模型编译为 batch model
输入/输出示例说明:
以较为复杂的多输入模型为例,假设模型有 3 个输入分支(2个resizer输入源,1个ddr输入源)和 1 个输出分支,并以 model_batch=2 编译,模型共需处理 3 批数据共 6 个 roi(即每批数据有2个roi),那么现有如下信息:
input_count = 3
output_count = 1
resizer_count = 2
roiCount = 6
data_batch = 3
model_batch = 2
所以模型推理这 3 批数据需要准备独立地址的 input_tensor 数量为 input_count * data_batch = 9。
另假设模型输入/输出的静态信息如下:
模型输入(model_info):
tensor_0_resizer: [2, 3, 128, 128]
tensor_1_resizer: [2, 3, 256, 256]
tensor_2_ddr: [2, 80, 1, 100]
模型输出(model_info):
tensor_out:[2, 100, 1, 56]
那么模型在推理时的动态信息则为:
模型输入(input_tensors):
[1x3x128x128, 1x3x256x256, 1x80x1x100, 1x3x128x128, 1x3x256x256, 1x80x1x100, 1x3x128x128, 1x3x256x256, 1x80x1x100]
模型输出(output_tensors):
[4x100x1x56]
其中,因为 model_batch = 2,所以底层 BPU 单次执行可处理 2 批数据;又因为 data_batch = 3,所以 output_tensor 最高维的计算公式为 ceil[(data_batch) / model_batch] * model_batch,可见其一定为 model_batch 的整数倍,这也是 BPU 硬件指令要求,缺少的输入会自动忽略计算。这里模型输出[0~2x100x1x56]是有效数据,最后一组是无效数据。
接口限制说明:
关于 data_batch 数量限制:其范围应该在[1, 255]。
使用该接口提交任务时应提前将 taskHandle 置为 nullptr,除非是给指定 taskHandle 追加任务(即使用 inferCtrlParam::more 功能)。
roi 大小要求是 2<=width<=4096, 2<=height<=4096。
原图尺寸要求是 1<=W<=4096, 16<=stride<=131072, stride 必须是16的倍数。
输出尺寸要求是 2<=Wout, 2<=Hout。
roi缩放倍数限制 0<=step<=262143,step计算公式 step=((src_len−1)∗65536+(dst_len−1)/2)/(dst_len−1),其中src_len为roi的W或H,dst_len为模型要求的W或H。
最多支持同时存在32个模型任务。
若模型有BPU batch推理的需求,请将模型编译为batch模型,不支持多个单batch resizer + batch DDR输入的方式推理。例如两个单batch resizer输入+一个2batch DDR输入:[1x3x128x128, 1x3x128x128, 2x100x1x56], 建议改为[2x3x128x128, 2x100x1x56]。
9.2.3.4.3. hbDNNWaitTaskDone()
等待任务完成或超时。
参数
[in] taskHandle 任务句柄指针。
[in] timeout 超时配置(单位:毫秒)。
返回值
返回 0 则表示API成功执行,否则执行失败。
注解
timeout > 0 表示等待时间;
timeout <= 0 表示一直等待,直到任务完成。
9.2.3.4.4. hbDNNReleaseTask()¶
释放任务,如果任务未执行则会直接取消并释放任务,如果已经执行则会在运行到某些节点后取消并释放任务。
参数
[in] taskHandle 任务句柄指针。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.4.5. hbDNNSetTaskDoneCb()
注册一个回调函数,这个回调函数在任务完成后自动执行。
参数
[in] taskHandle 任务句柄指针。
[in] cb 回调函数指针。
[in] userdata 用户自定义的数据。
返回值
返回 0 则表示回调函数注册成功,否则注册失败。
注解
该接口可以注册一个回调函数,任务执行完成后会调用这个回调函数去执行用户自定义的功能。如果不需要自定义输入,可以将userdata设为nullptr。
9.2.3.5. 内存操作
9.2.3.5.1. hbSysAllocMem()
申请BPU内存。
参数
[in] size 申请内存的大小。
[out] mem 内存指针。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.2. hbSysAllocCachedMem()
申请缓存的BPU内存。
参数
[in] size 申请内存的大小。
[out] mem 内存指针。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.3. hbSysFlushMem()
对缓存的BPU内存进行刷新。
参数
[in] mem 内存指针。
[in] flag 刷新标志符。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.4. hbSysFreeMem()
释放BPU内存。
参数
[in] mem 内存指针。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.5. hbSysWriteMem()¶
写入BPU内存。
参数
[out] dest 内存指针。
[in] src 数据指针。
[in] size 数据大小。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.6. hbSysReadMem()
读取BPU内存。
参数
[out] dest 数据指针。
[in] src 内存指针。
[in] size 数据大小。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.7. hbSysRegisterMem()
将已知物理地址的内存区间注册成可被BPU使用的内存标识,得到的内存是cacheable的。
参数
[in/out] mem 内存指针。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.5.8. hbSysUnregisterMem()
注销由 hbSysRegisterMem 注册的内存标识。
参数
[in] mem 内存指针。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.6. 插件¶
9.2.3.6.1. hbDNNRegisterLayerCreator()
注册Layer创建方法。
参数
[in] layerType Layer类型。
[in] layerCreator Layer创建方法。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.6.2. hbDNNUnregisterLayerCreator()
注销Layer。
参数
[in] layerType Layer类型。
返回值
返回 0 则表示API成功执行,否则执行失败。
9.2.3.7. 状态码¶
9.2.3.7.1. hbDNNGetErrorDesc()
将错误码翻译成自然语言。
参数
[in] errorCode dnn错误码。
返回值
返回 char * ,将内部错误码翻译成自然语言。
9.2.4. 数据排布及对齐规则¶
9.2.4.1. 数据排布¶
硬件内部为了提高计算效率,其数据使用特殊的排布方式以使得卷积运算中同一批次乘加用到的feature map和kernel在内存中相邻排放。 下面简要介绍J5中数据排布(layout)的概念。
神经网络模型中的变量可以用一个4维的张量表示,每个数字是这个张量中的元素,我们称之为自然排布。 将不同维度的不同元素按一定规则紧密排列在一起,形成一个独立的小块(block),然后将这些小块看成新的元素,组成新的4维张量, 我们称之为带有数据排布的张量。
输入输出数据会用到不同的layout数据排布,用户可通过API获取layout描述信息,不同的layout数据不可以直接比较。
注解
需要注意的是,在进行数据排布转换时,如果需要padding,则padding的值建议设置为零。
此处介绍两种数据排布: NHWC_NATIVE 和 NCHW_NATIVE ,以 NHWC_NATIVE 为例,其数据排布如下:
N0H0W0C0 | N0H0W0C1 | …… |
N0H0W1C0 | N0H0W1C1 | …… |
…… | …… | …… |
N0H1W0C0 | N0H1W0C1 | …… |
…… | …… | …… |
N1H0W0C0 | N1H0W0C1 | …… |
…… | …… | …… |
一个N*H*W*C大小的张量可用如下4重循环表示:
其中 NCHW_NATIVE 和 NHWC_NATIVE 相比,只是排布循环顺序不一样,此处不再单独列出。
注意
下文中提到的native都特指该layout。
9.2.4.2. BPU对齐限制规则¶
本节内容介绍使用BPU的对齐限制规则。
9.2.4.2.1. 模型输入要求¶
BPU不限制模型输入大小或者奇偶。既像YOLO这种416x416的输入可以支持,对于像SqueezeNet这种227x227的输入也可以支持。 对于NV12输入比较特别,要求HW都是偶数,是为了满足UV是Y的一半的要求。
9.2.4.2.2. 对齐和有效数据¶
BPU对数据有对齐限制。对齐要求和真实的数据排布用 hbDNNTensorProperties 中的 validShape , alignedShape 和 stride 表示。
validShape 是有效的shape;
alignedShape 是满足对齐要求的shape, 由于硬件特性, alignedShape 均由四维数据表示;
stride 表示 validShape 各维度的步长,其中,NV12输入的模型比较特殊,其 stride 均为0,因为NV12输入的模型只要求W 16对齐。
目前四维模型的张量可以通过 validShape 和 alignedShape 获取正确的数据排布,大于四维模型的张量可以通过 validShape 和 stride 获取正确的数据排布。
在后续场景使用时,考虑到对齐要求,建议按照 alignedByteSize 大小来申请内存空间。
9.2.4.3. NV12介绍¶
9.2.4.3.1. YUV格式¶
YUV格式主要用于优化彩色视频信号的传输。
YUV分为三个分量:Y表示明亮度,也就是灰度值;而U和V表示的则是色度,作用是描述影像色彩及饱和度,用于指定像素的颜色。
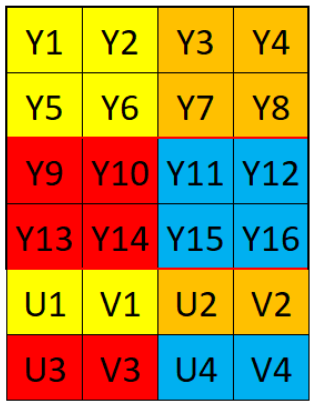
9.2.4.3.2. NV12排布
NV12图像格式属于YUV颜色空间中的YUV420SP格式,每四个Y分量共用一组U分量和V分量,Y连续排序,U与V交叉排序。
排列方式如下:
9.2.5. 错误码
9.2.6. 配置信息
9.2.6.1. 常用环境变量
9.2.6.2. 日志等级设置说明
日志等级。 dnn 中的日志主要分为4个等级:
HB_DNN_LOG_NONE = 0,不输出日志;
HB_DNN_LOG_WARNING = 3,该等级主要用来输出代码中的告警信息;
HB_DNN_LOG_ERROR = 4,该等级主要用来输出代码中的报错信息;
HB_DNN_LOG_FATAL = 5,该等级主要用来输出代码中的导致退出的错误信息。
日志等级设置规则:
若发生的LOG等级 >= 设置的等级,则该LOG可以被打印,反之被屏蔽;
设置的LOG等级越小,打印信息越多(等级0除外,0不输出日志)。 例如:设置LOG等级为3,即为 WARNING 级别,则3,4,5等级的LOG均可以被打印; 预测库默认LOG等级为 HB_DNN_LOG_WARNING ,则以下LOG级别的信息可以被打印: WARNING 、 ERROR 、 FATAL。
9.2.6.3. Trace日志配置说明¶
工具链Runtime中,预先插入了Trace日志语句,这样在程序运行时就可以输出与任务调度执行相关的重要信息,帮助您更加深入地了解代码的执行过程,并有效地排查问题和优化性能。 Runtime使用了第三方工具perfetto实现Trace日志。perfetto是一款强大的性能追踪工具,它可以提供详细的系统和应用程序性能数据。有关perfetto的详细信息,请参考 perfetto 官网。
默认情况下trace日志功能不开启,如您有使用需要,可通过环境变量开启此功能:
export HB_DNN_ENABLE_PERFETTO=true ,使能Trace日志。
export HB_DNN_PERFETTO_CONFIG_PATH=config.json ,指定runtime trace日志配置文件路径。
Trace工具和配置文件位于 ~/.horizon/ddk/j5_aarch64/dnn/ 路径下,目录结构为:
其中 config.json 的信息如下:
注意
config.json 中指定了 Perfetto 的配置文件 all.cfg ,其中 trace_record_file 指定了 trace 文件的输出路径。由于 Perfetto 不支持直接覆盖原有的 trace 文件,若该文件已经存在,则需要先将其删除。
由于指定的文件路径是相对路径,因此trace配置文件和脚本需要放置在运行程序的同级目录下。同时,需要确保在同一个shell环境中配置环境变量和运行程序。
in_process 只需打开环境变量即可:
system 模式请按照下述步骤执行:
用户进程终端:
数据抓取终端:
Trace数据抓取完成后会在用户指定路径下生成数据二进制文件 dnn.pftrace,使用 Perfetto UI 打开该文件即可查看程序运行过程中的任务调度执行信息。
关于 Perfetto UI 的使用,请参考 perfetto 官网 。
9.2.6.4. x86模拟器模拟平台配置说明¶
x86模拟器通过设置不同的选项模拟地平线不同的计算平台架构,其中:
export HB_DNN_SIM_PLATFORM=BERNOULLI ,表示模拟地平线 xj2 平台;
export HB_DNN_SIM_PLATFORM=BERNOULLI2 ,表示模拟地平线 xj3 平台;
export HB_DNN_SIM_PLATFORM=BAYES ,表示模拟地平线 j5 平台。
如果不设置 HB_DNN_SIM_PLATFORM 环境变量,会根据第一次加载的模型架构来设置模拟器平台,例如:第一次加载的模型是 BAYES 架构,则程序默认设置的平台为 j5。