
10.2.1. DSP简介
地平线J5处理器中包含两个DSP核,时钟频率为648MHz,使用的是Cadence公司的Tensilica Vision P6 DSP IP。
Vision P6 DSP专用于支持计算机视觉或图像处理等算法,超长指令字(VLIW)与单指令多数据流(SIMD)可以很大程度提升计算的速度。Vision P6 DSP采用5路VLIW架构,每条指令最多可以包含两个64字节加载或一个64字节加载和一个64字节存储;SIMD支持512bit的操作,如:64路8位整型,32路16位整型等。更多关于Vision P6 DSP的信息,可参见Cadence的Vision P6 用户手册。
DSP拥有强大的计算能力,在使用得当的情况下,将一些不能用BPU加速且ARM低效的计算部署到DSP上可以大大提高模型的推理性能。
10.2.2. Linux开发环境安装
10.2.2.1. 开发工具介绍¶
Xtensa Xplorer是Cadence为客户提供的针对其DSP进行软件开发的一个集成开发环境,具有软件开发(software development)、编译(compile)、调试(debugging)、仿真(simulation)、性能分析(profiling)、硬件跟踪(hardware trace)等功能。本开发文档中将只介绍Linux开发环境的安装,Windows开发环境的安装使用可参考Cadence提供的官方文档。
10.2.2.2. 安装DSP工具链以及配置核¶
您可以从地平线获取DSP开发包,开发包中包含 Xplorer-9.0.17-linux-x64-installer.bin 和 vdsp_vp6_RI4_linux.tgz 安装包。
安装 Xtensa Develop Tools
这里我们默认将 Xtensa Develop Tools 安装在 /opt/xtensa 目录下,您也可以自行指定其他目录。若安装在 /opt/xtensa 目录则需要root权限。执行如下命令:
安装 VP6 Core Configuration
将 vdsp_vp6_RI4_linux.tgz 安装包解压,解压后将其放在 Xtensa Develop Tools 安装目录下指定位置(如: /opt/xtensa/XtDevTools/install/builds/RI-2021.7-linux/ ),放到指定位置后进行安装。安装需要执行如下命令:
配置环境变量
为保证 Xtensa Develop Tools 的正常使用,您需要设置以下环境变量:
注解
Xtensa Develop Tools 的使用需要正确配置 License,申请和配置方式请联系地平线项目对接人。
Xtensa Develop Tools 测试
执行如下两个命令,如果此两命令可以正常执行,则表明linux开发环境安装成功:
10.2.2.3. DSP开发参考资料
为了更好地进行DSP开发,我们建议您参考以下文档,编译器安装成功后,主要开发工具文档可在路径 XtDevTools/downloads/RI-2021.7/docs 及 XtDevTools/install/builds/RI-2021.7-linux/vdsp_vp6_RI4/html/ISA 下找到,部分配套示例及库需要通过XPG(Xtensa Processor Generator)账号下载:
编号 | 文档名称及描述 | 文档目录 |
|---|---|---|
1 | VP6 DSP 介绍文档 | visionp6_ug.pdf |
2 | Dev Toolkit 使用介绍文档 | sw_dev_toolkit_ug.pdf |
3 | Compiler 使用介绍文档 | xtensa_xt_clang_compiler_ug.pdf |
4 | Profiler 使用说明文档 | gnu_profiler_ug.pdf |
5 | VP6 DSP 示例文档,位于示例工程Doc目录 | SW_Package_VisionP6_UserGuide.pdf(XPG下载) |
6 | Xi Library 文档,位于XI_Library_7.14.2.xws 工程 Doc目录 | XI_Library_UserGuide.pdf(XPG下载) |
7 | TileManager 使用说明文档 | TileManager.pdf(XPG下载) |
8 | VP6 DSP 指令 | NewISAhtml/index.html |
9 | 地平线图像数字信号处理器运行时API手册 | DSP运行时API手册 |
10.2.3. 开发流程
当前示例库中已经封装了一部分cv和nn算子,算子列表可点击 此处 查看。在地平线提供的Softmax算子示例中,展示了如何通过调度RPC框架和接口实现DSP自定义算子的功能封装, RPC通过rpmsg进行ARM与DSP的通信,且RPC存在通信延迟,参考 RPC模式 ,您可以在OE包中的 ddk/samples/vdsp_rpc_sample/ 处获取示例源码进行同步阅读理解。
10.2.3.1. 整体框架
模型推理时DSP调度的整体框架如下图所示:
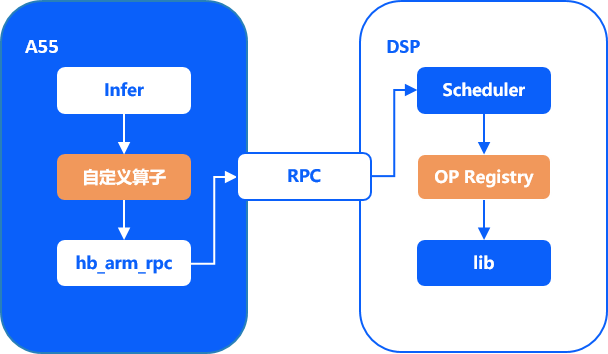
DSP与ARM是相对独立的两个系统,两者通过RPC进行交互。为简化RPC的使用,地平线为您提供了相应的接口, 具体使用方式详见 DSP运行时API手册 。
其中ARM端主要负责计算资源的分配以及DSP任务的发起和回收。 DSP端主要负责执行计算逻辑,将ARM端分配的计算任务按照调度逻辑逐个完成,并返回计算结果。 算子的执行过程如下:
1.实现DSP端自定义算子,注册该op并启动DSP镜像;
2.实现ARM端用户自定义算子的推理类;
3.ARM端初始化推理资源,准备进行模型推理;
4.ARM端准备好DSP调度需要的资源,并封装需要传递给DSP的参数,通过用户自定义算子发起RPC调用任务;
5.DSP schedule接收到RPC命令,根据调度优先级顺序执行已注册的DSP op进行运算;
6.DSP计算结束后,通过RPC将计算结果返回至ARM端;
7.ARM端接收到DSP返回的算子计算结果,根据返回值继续执行后续逻辑。
在整个流程中,用户需要保证ARM端算子调用接口和DSP端算子执行op的正确性,此架构与流程只展示了算子总体的框架和执行逻辑, 具体实现细节请参考后续的Softmax算子开发段落。
10.2.3.2. ARM Softmax算子开发¶
此章节展示了如何实现自定义算子Softmax的ARM端开发,对应地平线dsp sample中的 vdsp_rpc_sample/arm/nn/src/custom_dsp_softmax.cc 部分。 通过实现DSPSoftmax推理类实现了模型推理时的DSP调用,其中Forward函数实现了调用RPC API向DSP提交任务,并获取DSP返回值的功能。 在示例中,我们自定义DSP Softmax算子并重新注册,使模型在推理到Softmax算子时调用该自定义算子。
DSPSoftmax::Forward实现指令如下:
hbDSPRpcCtrlParam.rpcCmd = HB_DSP_RPC_CMD_NN_SOFTMAX 中,HB_DSP_RPC_CMD_NN_SOFTMAX为DSP侧Softmax算子的编号(DSP侧Softmax算子编号的注册过程详见 地平线工具链实测DSP性能 )。
注解
设计好DSPSoftmax自定义算子之后使用hbDNNRegisterLayerCreator接口注册替换原有的Softmax算子即可。
由于hbDSPRpc接口参数限制(只传输入输出数据地址参数),故直接调用hbDSPRpc接口访问自定义DSP算子,需要将DSP算子(输入输出)参数进行封装,传递到DSP端。例如:softmax需要输入输出数据地址及数据大小,所以将输入数据地址以及数据尺寸封装为hbDSPSoftmaxParam,传给hbDSPRpc接口。
10.2.3.3. DSP Softmax算子开发
本章节主要以DSP Softmax算子开发为例为您介绍DSP侧算子开发的流程,对应地平线dsp sample中的 vdsp_rpc_sample/dsp/src/softmax_ivp.cc 部分。
10.2.3.3.1. Softmax分析¶
Softmax算子可以拆分为以下四个基础计算:
1.计算输入元素中的最大值max。
2.计算并更新输入的每个元素: input = exp(input - max) 。
3.计算更新后input的和sum。
4.计算 output = input / sum 。
10.2.3.3.2. DSP Softmax实现
本章节将对如何实现上一节中提到的四个基础运算从而实现DSP Softmax算子进行介绍。
Cadence实现了一些基础数学运算,方便用户进行开发。您可以从Cadence的基础示例中获取源码,也可从地平线直接获取编译好的依赖库dsp_math。
为了充分利用硬件性能,开发人员需要了解DSP特性并使用好这些特性(VLIW、SIMD)。在进行开发时,可参照Cadence本身已实现的基础运算。
步骤1:vecmaxf指令如下:
步骤2:vecexpf_max指令如下:
步骤3:vecsum指令如下:
步骤4:除法运算可变为乘法运算,且实现乘法运算比较容易且性能较好。实现vecmul指令如下:
至此,可实现DSP侧Softmax算子hb_dsp_softmax。
10.2.3.3.3. DSP算子性能分析及优化
在进行DSP算子性能分析及优化前,您需要明确知悉以下四点内容:
1.DSP的两块DRAM(DRAM0和DRAM1)为TCM内存,存储在TCM中的数据读取较快,因此,算子相关的数据、代码应该存储在TCM中进行计算。
2.算子的输入和输出内存是在DDR上,DDR和TCM之间可通过DMA进行数据搬运,而DMA传输需要时间,因此,常用PINGPONG DMA来减少由于数据搬运而产生的等待时间。
3.LSP:链接支持包。其中在memmap.xmm文件中可以看到每个段所处的内存地址,可通过调整LSP或对依赖库和目标文件重置段信息两种方式对代码和数据在内存中的位置进行调整。详细信息见Xtensa Linker Support Packages (LSPs) Reference Manual(lsp_rm.pdf)。
4.printf会十分耗时,统计性能的时候请将printf放在合适的位置。
DSP算子性能可以从以下三部分进行分析优化:
1.DSP SIM:DSP工具链提供了仿真功能,可通过仿真获取算子运行的时钟周期从而估计出实际运行时间。开发人员可优先通过SIM信息来查看算子性能是否达到要求,是否需要对算子进一步进行优化。
2.使用地平线DSP工具链上板来实测性能。
3.使用PINGPONG DMA完成大数据搬运。
10.2.3.3.4. DSP SIM
在 <xtensa/tie/xt_timer.h> 头文件中,我们提供了 XT_RSR_CCOUNT() 函数获取当前的周期计数,从而通过差值可以获得算子运行的时钟周期。时钟周期cycle*1.5可估计出该算子需要运行的时间(ns)。示例代码如下:
其中, dsp_softmax 为DSP侧实现的Softmax算子。
在上述示例中,需尽量保证所有的计算数据都在TCM中,提高性能。
注解
输入和输出均直接申请在TCM(DRAM)中,但因DRAM内存大小有限,只能测试小数据量的性能;若需测试大数据量,请用DMA进行数据搬运。
算子的实现中,可能使用一些全局或者局部变量,要想进一步提高算子性能,需要对LSP进行修改,将 .rodata 、 .data 、 .bss 字段以及STACK放到DRAM上。对LSP进行修改之后可能会导致内存不够,此种情况下不可直接修改LSP,需要修改相应目标文件段的位置,详情见Xtensa Linker Support Packages (LSPs) Reference Manual(lsp_rm.pdf)。
10.2.3.3.5. 地平线工具链实测DSP性能
地平线提供了DSP工具链,方便用户将实现好的算子注册到DSP调度系统中,具体可参见 DSP运行时API手册 。
DSPmain函数实现指令如下:
其中,用户只需要关心 hb_dsp_register_fn 部分,其余部分均为模板数据,不可进行更改。0x400为DSP侧Softmax算子的编号。
hb_dsp_softmax为算子执行入口,示例代码如下(宏定义OPT部分表示Pingpong搬运内存到TCM的优化实现):
input与output的virAddr中存储的是 ARM Softmax算子开发 内提及的hbDSPRpc函数中传入的input_mem.virAddr中的数据,该数据存储在DDR中。由于示例中算子直接使用输入输出会导致运行时间变长,因此需要使用DMA功能将数据搬运至TCM,在数据量比较大的时候需要用到PINGPONG DMA。TCM内存可以通过tm进行申请。
10.2.3.3.6. PINGPONG DMA
在进行DMA数据传输时,如果只有一个buffer接收数据,那么就只能是”DMA传输->处理数据->DMA传输->处理数据”串行处理。 而如果有两个buffer接收数据(一个称为ping buffer,一个称为pong buffer),就可以在处理ping buffer时,DMA传输pong buffer, 理想的情况是当处理完ping buffer的数据时,pong buffer的数据已通过DMA传输完成,紧接着可以处理pong buffer的数据,这样就大大提高了传输处理效率。
开发人员可以阅读 Xtensa System Software Reference Manual(sys_sw_rm.pdf)的第七章熟悉DMA相关知识,利用原始接口完成pingpong DMA。
针对Softmax示例的每个计算步骤,都可以使用Pingpong操作,故提取出hb_dsp_ping_pong_frame函数,代码如下:
10.2.3.4. 模型运行¶
有关于模型运行的相关内容,您可以参考 运行NN示例 部分的相关描述。