
本章节旨在说明地平线J5算法工具链所提供的PTQ模型转换方案的工具包的介绍及使用方法。
小技巧
建议您在阅读本章内容之前先完成以下准备工作:
阅读 工具链概览 章节中PTQ方案的相关内容和 PTQ转换原理及流程 章节的内容, 以了解对PTQ方案和模型转换步骤。
根据 Docker容器部署 章节的内容完成了Docker环境安装配置和镜像拉取。
本章内容主要介绍地平线PTQ模型转换方案的工具包。该工具包可在开发机或Docker环境下运行。 如果您选择在开发机中运行该工具包,则需要在J5天工开物发布物(即:horizon_j5_open_explorer)的 ddk/package/host 路径下运行 install.sh 脚本进行安装。 安装完成后,运行 hb_mapper --help 命令验证工具安装是否成功。 如果您选择在Docker容器中运行该工具,则无需以上安装步骤,根据 Docker容器部署 章节内容, 进入Docker容器后,然后运行 hb_mapper --help 命令验证工具安装是否成功。
下面几节内容为您介绍各工具使用方法。
6.2.1. PTQ转换工具阅读概览
工具 | 工具简介 |
|---|---|
hb_mapper工具 | hb_mapper工具是地平线提供的将浮点模型映射为量化模型并附带验证功能的工具, 提供模型检查、模型转换以及各阶段卷积层向量输出的功能。 |
hb_perf工具 | hb_perf工具是地平线提供的用于分析量化混合模型性能的分析工具。 |
vec_diff工具 | vec_diff工具是地平线提供的向量比较工具,通过该工具, 可以比较不同阶段模型的卷积层输出差异,可用于定位精度异常问题。 |
hb_model_info工具 | hb_model_info工具是地平线提供的用于解析混合模型(*.bin)编译时的依赖及参数信息的工具。 |
hb_pack工具 | hb_pack工具是地平线提供的用于将多个混合模型(*.bin)文件打包为一个模型文件的工具。 |
hb_verifier工具 | hb_verifier工具是地平线提供的用于对指定的定点模型和runtime模型进行结果验证的工具。 |
hb_model_modifier工具 | hb_model_modifier工具是地平线提供的用于对runtime模型输入输出端一些特定类型节点进行删除的工具。 |
hb_custom_op工具 | hb_custom_op工具是地平线提供的用于生成包含自定义算子python模板文件的工具, 生成的模板文件中包含自定义算子的计算定义函数。 |
hb_eval_preprocess工具 | hb_eval_preprocess工具是地平线提供的用于对模型精度进行评估时, 在x86环境下对图片数据进行预处理 (包括图片resize、crop、padding等在图片数据送入模型前的特定处理操作)的工具。 |
HB_ONNXRuntime推理库 | HB_ONNXRuntime是地平线基于公版ONNXRuntime封装的一套x86端的ONNX模型推理库。 |
精度debug工具 | 精度debug工具是地平线提供的用于协助您自主定位模型量化过程中产生的精度问题的工具, 该工具能够协助您对校准模型进行节点粒度的量化误差分析,最终帮助您快速定位出现精度异常的节点。 |
6.2.2. hb_mapper工具
hb_mapper 工具是一个将浮点模型映射为量化模型,并附带验证功能的工具。 hb_mapper 包括三个子命令 checker、 makertbin 和 infer。 它们分别提供了的模型检查、模型转换,以及各阶段卷积层向量输出的功能。 接下来的内容逐一介绍上述子命令。
6.2.2.1. 模型检查命令(hb_mapper checker)
在实际工程中,由于并非所有浮点模型均能够转为量化模型,因此在转换之前需要进行一次检查, 这个check过程,会走一遍模型转换的过程,但是对于比较耗时的步骤,进行了简化处理。 该命令在完成模型的检查后,会输出检查结果和OP在设备上的部署情况。
6.2.2.1.1. 使用方法
hb_mapper checker的使用方法:
6.2.2.1.2. 命令行参数¶
hb_mapper checker的命令行参数:
--help
显示帮助信息并退出。
--model-type
用于指定检查输入的模型类型,目前只支持设置 caffe 或者 onnx。
--march
用于指定BPU的微架构。若使用X/J3系列处理器则设置为 bernoulli2,若使用J5处理器则设置为 bayes,默认值为 bayes。
--model
Caffe或ONNX浮点模型文件。
在 model-type 被指定为 caffe 时,取值为Caffe模型的caffemodel文件名称。
在 model-type 被指定为 onnx 时,取值为ONNX模型文件名称。
--proto
用于指定Caffe模型的prototxt文件,此参数仅在 model-type 指定 caffe 时有效。
--input-shape
可选参数,用于指定输入模型的输入节点以及该节点的输入的shape,其shape以 x 分隔。
取值为 {input_name} {NxHxWxC/NxCxHxW} , input_name 与shape之间以空格分隔。 例如模型输入节点名称为 data,输入shape为 [1,3,224,224],此时应设置为 data 1x3x224x224。 如果此处配置shape与模型内shape信息不一致,会以此处配置为准。
注解
注意,一个 --input-shape 只接受一个name和shape组合,如果您的模型有多个输入节点,在命令中多次配置 --input-shape 参数即可。
--output
该参数已经废弃,log信息存储于 hb_mapper_checker.log 中。
注解
如您在使用check过程中发现 The converted model node information 提示结果和在使用makertbin过程中得到的 The converted model node information 提示结果不一致, 可能是因为在做check的过程中,实际上是有一个默认的yaml配置的,而如果您在进行转换前进行了yaml的配置,一些参数的不同可能会导致此种情况的发生, 可能会导致此种情况发生的yaml配置参数包括: norm_type 、 mean_value 、 scale_value 、 calibration_type 、 run_on_bpu 、 run_on_cpu 、 optimization 、 set_node_data_type 、 node_info 。
6.2.2.2. 模型编译命令(hb_mapper makertbin)
该命令根据配置文件和模型的种类,会生成ONNX量化模型以及仿真上板情况的runtime模型,完成模型转换过程。
6.2.2.2.1. 使用方法
hb_mapper makertbin提供两种模式,开启 fast-perf 模式和不开启 fast-perf 模式。
fast-perf 模式开启后,会在转换过程中生成可以在板端运行最高性能的bin模型,工具内部主要进行以下操作:
将BPU可执行算子尽可能运行在BPU上(即可通过yaml文件中node_info参数指定在BPU上运行的算子)。
删除模型首尾可删除的CPU算子,包括:Quantize/Dequantize、Transpose、Cast、Reshape等。
以性能最高的O3优化等级编译模型。
hb_mapper makertbin的使用方法(不开启fast-perf模式):
hb_mapper makertbin的使用方法(开启fast-perf模式):
注意
请注意,如您需要开启fast-perf模式,由于该模式下,工具会使用内置的高性能配置,请勿对 --config 参数进行配置。
6.2.2.2.2. 命令行参数
hb_mapper makertbin的命令行参数:
--help
显示帮助信息并退出。
-c, --config
模型编译的配置文件,为yaml格式。
--model-type
caffe 或者 onnx。
--fast-perf
开启fast-perf模式,该模式开启后,会在转换过程中生成可以在板端运行最高性能的bin模型,方便您用于后续的模型性能评测。
如您开启了fast-perf模式,还需要进行如下配置:
--model Caffe或ONNX浮点模型文件。
--proto 用于指定Caffe模型prototxt文件。
--march BPU的微架构。若使用X/J3系列处理器则设置为 bernoulli2,若使用J5处理器则设置为 bayes,默认值为 bayes。
-i, --input-shape 可选参数,指定模型的输入节点的shape信息,目前此配置仅在开启fast-perf时生效。使用方式为:
指定单个输入节点的shape信息,使用方式为 --input-shape input_1 1x3x224x224。
指定多个输入节点的shape信息,使用方式为 --input-shape input_1 1x3x224x224 --input-shape input_2 1x3x224x224。
注意
如您未指定 --input-shape 参数,此时工具将仅支持动态输入节点第一维为[-1, 0, ?]的模型,默认会将动态输入节点的第一维设置为1。
编译产生的log文件会储存在命令执行路径下面,名称为 hb_mapper_makertbin.log。
6.2.2.2.3. 配置文件模板
一份完整的配置文件模板如下:
注解
此处配置文件仅作展示,在实际模型配置文件中 caffe_model 与 onnx_model 两种只存在其中之一。
即,要么是Caffe模型,要么是ONNX模型。即 caffe_model + prototxt 或者 onnx_model 二选一。
注解
在配置march为bayes,即在J5处理器上使用hb_mapper makertbin时,如您将优化等级optimize_level配置为O3, hb_mapper makerbin默认提供缓存能力。即在您第一次在上述场景下使用hb_mapper makerbin对模型进行编译时,会自动创建缓存文件cache.json, 后续在您的working_dir不变的情况下,在重复编译时会自动调用此文件,降低您的编译时间。
配置文件主要包含模型参数组、输入信息参数组、校准参数组、编译参数组和自定义算子参数组。 在您的配置文件中,每个参数组位置都需要存在,具体参数分为可选和必选,可选参数可以不配置。
以下是具体参数信息,参数会比较多,我们依照上述的参数组次序介绍。 可选/必选表示该参数项在配置文件中是否必须进行配置。
6.2.2.2.4. 配置文件具体参数信息
6.2.2.2.4.1. 模型参数组¶
编 号 | 参数名称 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|
1 | prototxt | 参数作用:指定Caffe浮点模型的prototxt文件名称。 取值范围:模型路径。 默认配置:无。 参数说明:在 hb_mapper makertbin 的 model-type 为 caffe 时必须配置。 | Caffe模型 必选 |
2 | caffe_model | 参数作用:指定Caffe浮点模型的caffemodel文件名称。 取值范围:模型路径。 默认配置:无。 参数说明:在 hb_mapper makertbin 的 model-type 为 caffe 时必须配置。 | Caffe模型 必选 |
3 | onnx_model | 参数作用:指定ONNX浮点模型的onnx文件名称。 取值范围:模型路径。 默认配置:无。 参数说明:在 hb_mapper makertbin 的 model-type 为 onnx 时必须配置。 | ONNX模型 必选 |
4 | march | 参数作用:指定产出混合异构模型需要支持的平台架构。 取值范围:'bayes' 或 'bernoulli2'。 默认配置: 无。 参数说明: 两个可选配置值依次对应J5和X3&J3处理器, 根据您使用的平台选择。 | 必选 |
5 | output_model_file_prefix | 参数作用:指定转换产出混合异构模型的名称前缀。 取值范围:无。 默认配置:'model'。 参数说明:输出的定点模型文件的名称前缀。 | 可选 |
6 | working_dir | 参数作用:指定模型转换输出的结果的存放目录。 取值范围:无。 默认配置:'model_output'。 参数说明:若该目录不存在,则工具会自动创建目录。 | 可选 |
7 | layer_out_dump | 参数作用:指定混合异构模型是否保留输出中间层值的能力。 取值范围:True、False。 默认配置:False。 参数说明:输出中间层的值是调试需要用到的手段, 常规状态下请不要开启。 注意: 请您注意,在layer_out_dump为True时,暂时不支持配置input_source为resizer。 | 可选 |
8 | output_nodes | 参数作用:指定模型的输出节点。 取值范围:模型中的节点名称。 默认配置:无。 参数说明:此参数用于支持您指定节点作为模型输出, 设置值需为模型中的具体节点名称。 多个值的配置方法请参考 param_value配置。 | 可选 |
9 | remove_node_type | 参数作用:设置删除节点的类型。 取值范围:"Quantize"、"Transpose"、"Dequantize"、 "Cast"、"Reshape"、"Softmax"。不同类型用 ; 分割。 默认配置:无。 参数说明:不设置或设置为空不影响模型转换过程。 此参数用于支持您设置待删除节点的类型信息。 被删除的节点必须在模型的开头或者末尾, 与模型的输入或输出连接。 注意: 待删除节点会按顺序依次删除,并动态更新模型结构; 同时在节点删除前还会判断该节点是否位于模型的输入输出处。 因此节点的删除顺序很重要。 | 可选 |
10 | remove_node_name | 参数作用:设置删除节点的名称。 取值范围:模型中待删除的节点名称,不同名称用 ; 分割。 默认配置:无。 参数说明:不设置或设置为空不影响模型转换过程。 此参数用于支持您设置待删除节点的类型信息。 被删除的节点必须在模型的开头或者末尾,与模型的输入或输出连接。 注意: 待删除节点会按顺序依次删除,并动态更新模型结构; 同时在节点删除前还会判断该节点是否位于模型的输入输出处。 因此节点的删除顺序很重要。 | 可选 |
11 | set_node_data_type | 参数作用:配置指定op的输出数据类型为int16。 取值范围:支持配置int16的算子范围您可参考 工具链算子支持约束列表。 默认配置:无。 参数说明:在模型转换过程中,大多数op的默认输入输出数据类型为int8, 通过该参数可以指定特定op的输出数据类型为int16(在满足一定的约束条件下)。 int16相关说明详见 int16配置说明 部分的描述。 具体算子int16支持情况详见 工具链算子支持约束列表 。 注意: 该参数相关功能已合并至 node_info 参数中。 | 可选 |
12 | debug_mode | 参数作用:保存用于精度debug分析的校准数据。 取值范围:"dump_calibration_data"。 默认配置:无。 参数说明:该参数作用为保存用于精度debug分析的校准数据,数据格式为.npy。 该数据通过np.load()可直接送入模型进行推理。 若不设置此参数,您也可自行保存数据并使用精度debug工具进行精度分析。 | 可选 |
13 | node_info | 参数作用:支持配置指定OP的输入输出数据类型为int16 以及强制指定算子在CPU或BPU上运行。 取值范围:支持配置int16的算子范围您可参考 工具链算子支持约束列表。 可指定在CPU或BPU运行的算子需为模型中包含的算子。 默认配置:无。 参数说明:基于减少yaml中的参数的原则,我们将 set_node_data_type 、 run_on_cpu 和 run_on_bpu 三个参数的能力融合到本参数中, 并在此基础上扩充支持配置指定op输入数据类型为int16的能力。 node_info 参数使用方式:
‘InputType’: ‘int16’代表指定算子的所有输入数据类型为int16。 如需指定算子特定输入的InputType,可在InputType后通过指定数字来进行配置。如: ‘InputType0’: ‘int16’代表指定算子的第一个输入数据类型为int16, ‘InputType1’: ‘int16’代表指定算子的第二个输入数据类型为int16,以此类推。 注意: ‘OutputType’ 不支持指定算子特定输出的OutputType,配置后对算子的所有输出生效, 不支持配置 ‘OutputType0’ 、 ‘OutputType1’等。 | 可选 |
6.2.2.2.4.2. 输入信息参数组¶
编 号 | 参数名称 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|
1 | input_name | 参数作用:指定原始浮点模型的输入节点名称。 取值范围:单输入时 "" 或输入节点名称,多输入时 "input_name1; input_name2; input_name3..."。 默认配置:无。 参数说明:浮点模型为单输入模型时不需要配置, 多输入模型时必须配置以保证后续类型及校准数据输入顺序的准确性。 多个值的配置方法请参考 param_value配置。 | 单输入时 可选 多输入时 必选 |
2 | input_type_train | 参数作用:指定原始浮点模型的输入数据类型。 取值范围: 'rgb'、 'bgr'、 'yuv444'、'gray'、 'featuremap'。 默认配置:无。 参数说明:每一个输入节点都需要配置一个确定的输入数据类型, 存在多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。 多个值的配置方法请参考 param_value配置。 数据类型的选择请参考: 转换内部过程解读 部分的介绍。 | 必选 |
3 | input_layout_train | 参数作用:指定原始浮点模型的输入数据排布。 取值范围:'NHWC' 、 'NCHW'。 默认配置:无。 参数说明:每一个输入节点都需要配置一个确定的输入数据排布, 这个排布必须与原始浮点模型所采用的数据排布相同。存在多个输入节点时, 设置的节点顺序需要与 input_name 里的顺序严格保持一致。 多个值的配置方法请参考 param_value配置。 什么是数据排布请参考: 转换内部过程解读 部分的介绍。 | 必选 |
4 | input_type_rt | 参数作用:转换后混合异构模型需要适配的输入数据格式。 取值范围:'rgb' 、 'bgr' 、 'yuv444' 、 'nv12' 、 'gray' 、 'featuremap'。 默认配置:无。 参数说明:这里是指明您需要使用的数据格式。 不要求与原始模型的数据格式一致。 但是需要注意在边缘平台喂给模型的数据是使用这个格式。 每一个输入节点都需要配置一个确定的输入数据类型,存在多个输入节点时, 设置的节点顺序需要与 input_name 里的顺序严格保持一致。 多个值的配置方法请参考 param_value配置。 数据类型的选择请参考: 转换内部过程解读 部分的介绍。 | 必选 |
5 | input_layout_rt | 参数作用:转换后混合异构模型需要适配的输入数据排布。 取值范围: 'NCHW' 、 'NHWC'。 默认配置:无。 参数说明:每一个输入节点都需要配置一个确定的输入数据排布。 这个输入是您希望给混合异构模型指定的排布。 不合适的输入数据的排布设置将会影响性能, 存在多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。 多个值的配置方法请参考 param_value配置。 什么是数据排布请参考: 转换内部过程解读 部分的介绍。 | 可选 |
6 | input_space_and_range | 参数作用:指定输入数据格式的特殊制式。 取值范围: 'regular'、 'bt601_video'。 默认配置: 'regular'。 参数说明:这个参数是为了适配不同ISP输出的yuv420格式, 在相应 input_type_rt 为 nv12 时,该配置才有效。
注意: 在没有明确需要的情况下,您不要配置此参数。 | 可选 |
7 | input_shape | 参数作用:指定原始浮点模型的输入数据尺寸。 取值范围:无。 默认配置:无。 参数说明:shape的几个维度以 x 连接,例如 '1x3x224x224'。 原始浮点模型只有一个输入节点情况时可以不配置, 工具会自动读取模型文件中的尺寸信息。 配置多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。 多个值的配置方法请参考 param_value配置。 | 可选 |
8 | input_batch | 参数作用:指定转换后混合异构模型需要适配的输入batch数量。 取值范围:1-4096。 默认配置:1。 参数说明:这里input_batch为转换后混合异构bin模型输入batch数量, 但不影响转换后onnx的模型的输入batch数量。 该参数仅支持配置一个数值,模型为多输入时,该值将作用于模型的所有输入。 此参数不配置时默认为1。 注意:
| 可选 |
9 | norm_type | 参数作用:在模型中添加的输入数据预处理方法。 取值范围: 'data_mean_and_scale' 、 'data_mean' 、 'data_scale' 、 'no_preprocess'。 默认配置:'no_preprocess'。 参数说明: no_preprocess 表示不添加任何数据预处理; data_mean 表示提供减均值预处理; data_scale 表示提供乘scale系数预处理; data_mean_and_scale 表示提供先减均值再乘scale系数前处理。 输入节点多于一个时,设置的节点顺序需要与 input_name 里的顺序严格保持一致, 多个值的配置方法请参考 param_value配置。 配置该参数的影响请参考: 转换内部过程解读 部分的介绍。 注意: 当 input_type_rt 配置为featuremap非四维输入时, norm_type只能配置为no_preprocess。 | 可选 |
10 | mean_value | 参数作用:指定预处理方法的图像减去的均值。 取值范围:无。 默认配置:无。 参数说明:当 norm_type 存在 data_mean_and_scale 或 data_mean 时需要配置该参数。 对于每一个输入节点而言,存在两种配置方式。 第一种是仅配置一个数值,表示所有通道都减去这个均值; 第二种是提供与通道数量一致的数值(这些数值以空格分隔开), 表示每个通道都会减去不同的均值。 配置的输入节点数量必须与 norm_type 配置的节点数量一致。 如果存在某个节点不需要 mean 处理,则为该节点配置 'None'。 多个值的配置方法请参考 param_value配置。 | 可选 |
11 | scale_value | 参数作用:指定预处理方法的数值scale系数。 取值范围:无。 默认配置:无。 参数说明:当 norm_type 存在 data_mean_and_scale 或 data_scale 时需要配置该参数。 对于每一个输入节点而言,存在两种配置方式。 第一种是仅配置一个数值,表示所有通道都乘以这个系数; 第二种是提供与通道数量一致的数值(这些数值以空格分隔开), 表示每个通道都会乘以不同的系数。 配置的输入节点数量必须与 norm_type 配置的节点数量一致。 如果存在某个节点不需要 scale 处理,则为该节点配置 'None'。 多个值的配置方法请参考 param_value配置。 | 可选 |
input_type_rt/ input_type_train补充说明
地平线的计算平台架构,在设计时为了提升性能,做了两点假设:
假设输入的数据都是int8的量化数据。
摄像头获取到的数据是nv12。
因此,如果您在模型训练时使用rgb(NCHW)输入格式,但是想使这个模型能够高效处理nv12数据,只需要在模型转换时做如下配置:
小技巧
若您在训练模型时使用gray格式,而实际使用中输入的数据格式为nv12格式, 则可以将模型转换时的 input_type_rt 及 input_type_train 均配置为 gray, 在嵌入式应用开发时仅使用nv12的y通道地址作为输入即可。
除了将输入数据转换为nv12,我们还支持您在训练和runtime infer时使用不同的rgb-order。 工具会根据 input_type_rt 和 input_type_train 指定的数据格式自动添加数据转换节点,根据地平线的实际生产经验, 并不是任意type组合都是需要的,为了避免您误用, 我们只开放了一些固定的type组合如下表(Y为已支持类型,N为暂不支持类型,表格中第一行是 input_type_rt 中支持的类型,第一列是 input_type_train 支持的类型):
input_type_train \ input_type_rt | nv12 | yuv444 | rgb | bgr | gray | featuremap |
|---|---|---|---|---|---|---|
yuv444 | Y | Y | N | N | N | N |
rgb | Y | Y | Y | Y | N | N |
bgr | Y | Y | Y | Y | N | N |
gray | N | N | N | N | Y | N |
featuremap | N | N | N | N | N | Y |
注解
为了配合计算平台对于输入数据类型的要求(int8),减小推理开销, 对于 input_type_rt 类型为 rgb(NHWC/NCHW)/bgr(NHWC/NCHW) 的配置, 转换工具转换出的模型,其输入数据类型均为 int8。 也就是说,对于常规的图像数据,需要-128使用(该操作在API中已自动进行,无需再进行该操作)。
在转换得到的最终产出bin模型中, input_type_rt 到 input_type_train 是一个内部的过程, 您只需要关注 input_type_rt 的数据格式即可。 正确理解每种 input_type_rt 的要求,对于嵌入式应用准备推理数据很重要,以下是对 input_type_rt 每种格式的说明:
rgb、bgr和gray都是比较常见的图像格式,注意每个数值都采用UINT8表示。
yuv444是一种常见的图像格式,注意每个数值都采用UINT8表示。
nv12是常见的yuv420图像格式,每个数值都采用UINT8表示。
nv12有个比较特别的情况是 input_space_and_range 设置 bt601_video 时, 较于常规nv12情况,它的数值范围由[0,255]变成了[16,235],每个数值仍然采用UINT8表示。 请注意, bt601_video 仅在 input_type_train 为 bgr 或 rgb 时支持通过 input_space_and_range 进行配置。
featuremap适用于以上列举格式不满足您需求的情况,此type每个数值采用float32表示。例如雷达和语音等模型处理就常用这个格式。
小技巧
以上 input_type_rt 与 input_type_train 是固化在工具链的处理流程中,如果您非常确定不需要转换, 将两个 input_type 设置成一样就可以了,一样的 input_type 会做直通处理,不会影响模型的实际执行性能。
同样的,数据前处理也是固化在流程中,如果您不需要做任何前处理,通过 norm_type 配置关闭这个功能即可,不会影响模型的实际执行性能。
6.2.2.2.4.3. 校准参数组¶
编 号 | 参数名称 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|
1 | cal_data_dir | 参数作用:指定模型校准使用的标定样本的存放目录。 取值范围:无。 默认配置:无。 参数说明:目录内校准数据需要符合输入配置的要求。 具体请参考 校准数据准备 部分的介绍。配置多个输入节点时, 设置的节点顺序需要与 input_name 里的顺序严格保持一致。 多个值的配置方法请参考 param_value配置。 当calibration_type为 load、 skip 时,cal_data_dir无需配置。 注意: 为了方便您的使用,如果未发现cal_data_type的配置,我们将根据文件夹 后缀对数据类型进行配置。如果文件夹后缀以 _f32 结尾,则认为数据 类型是float32,否则认为数据类型是uint8。 当然,我们强烈建议您通过cal_data_type参数对数据类型进行约束。 | calibration_type 非 load、skip 时必选 |
2 | cal_data_type | 参数作用:指定校准数据二进制文件的数据存储类型。 取值范围:'float32'、'uint8'、'int32'、'int16'、'int8'。 默认配置:无。 参数说明:指定模型校准时使用的二进制文件的数据存储类型。 没有指定值的情况下将会使用文件夹名字后缀来做判断。 多个值的配置方法请参考 param_value配置。 | 可选 |
3 | preprocess_on | 参数作用:开启图片校准样本自动处理。 取值范围: True 、 False。 默认配置: False。 参数说明:该选项仅适用于4维图像输入的模型, 非4维模型不要打开该选项。 在启动该功能时,cal_data_dir 目录下存放的都是jpg/bmp/png 等图片数据,工具会使用skimage读取图片, 并resize到输入节点需要的尺寸。 为了保证校准的效果,建议您保持该参数关闭。 使用的影响请参考 校准数据准备 部分的介绍。 | 可选 |
4 | calibration_type | 参数作用:校准使用的算法类型。 取值范围:'default'、'mix'、'kl'、'max' 、 'load' 和 'skip'。 默认配置:'default'。 参数说明: kl 和 max 都是公开的校准量化算法, 其基本原理可以通过网络资料查阅。 使用 load 方式校准时, qat模型必须是通过plugin 导出的模型。详情参见 使用QAT量化感知训练方案进一步提升模型精度 。 default 是一个自动搜索的策略, 会尝试从系列校准量化参数中获得一个相对效果较好的组合。 mix 是一个集成多种校准方法的搜索策略, 能够自动确定量化敏感节点,并在节点粒度上从不同的校准方法 中挑选出最佳方法,最终构建一个融合了多种校准方法优势的组合校准方式。 如果您使用的是QAT导出的模型,则应选择 load。 建议您先尝试 default, 如果最终的精度结果不满足预期, 再根据 PTQ模型精度调优 章节的建议配置不同的校准参数。 若您只想尝试对模型性能进行验证,但对精度没有要求, 则可以尝试 skip 方式进行校准。 该方式会使用max+内部生成的随机校准数据进行校准, 不需要您准备校准数据,比较适合初次尝试对模型结构进行验证。 注意: 使用skip方式时,因其使用max+内部生成的随机校准数据进行校准, 得到的模型不可用于精度验证。 | 可选 |
5 | max_percentile | 参数作用:该参数为 max 校准方法的参数,用以调整 max 校准的截取点。 取值范围: 0.5 ~ 1.0。 默认配置: 1.0。 参数说明:此参数仅在 calibration_type 为 max 时有效。 常用配置选项有:0.99999/0.99995/0.99990/0.99950/0.99900。 建议您先尝试 calibration_type 配置 default, 如果最终的精度结果不满足预期, 再根据 PTQ模型精度调优 部分建议调整该参数。 | 可选 |
6 | per_channel | 参数作用:控制是否针对featuremap的每个channel进行校准。 取值范围: True 、 False。 默认配置: False。 参数说明: calibration_type 设置非default、非mix时有效。 建议您先尝试 default, 如果最终的精度结果不满足预期, 再根据 PTQ模型精度调优 部分建议调整该参数。 | 可选 |
7 | run_on_cpu | 参数作用:强制指定算子在CPU上运行。 取值范围:模型中的节点名称。 默认配置:无。 参数说明:CPU上虽然性能不及BPU,但是提供的是float精度计算。 如果您确定某些算子需要在CPU上计算, 可以通过该参数指定。 设置值为模型中的具体节点名称。 多个值的配置方法请参考 param_value配置。 注意: 该参数相关功能已合并至 node_info 参数中。 | 可选 |
8 | run_on_bpu | 参数作用:强制指定OP在BPU上运行。 取值范围:模型中的节点名称。 默认配置:无。 参数说明:为了保证最终量化模型的精度,少部分情况下, 转换工具会将一些具备BPU计算条件的算子放在CPU上运行。 如果您对性能有较高的要求,愿意以更多一些量化损失为代价, 则可以通过该参数明确指定算子运行在BPU上。 设置值为模型中的具体节点名称。 多个值的配置方法请参考 param_value配置。 注意: 该参数相关功能已合并至 node_info 参数中。 | 可选 |
9 | optimization | 参数作用:此参数为您提供一些调优可配置选项, 通过该参数可配置不同的模式对模型精度/性能进行调优。 取值范围:set_model_output_int8、 set_model_output_int16、 set_{NodeKind}_input_int16、 set_{NodeKind}_output_int16、 set_Softmax_input_int8、 set_Softmax_output_int8、 asymmetric、 bias_correction、 lstm_batch_last。 注:此处Nodekind为标准ONNX算子类型写法如Conv,Mul,Sigmoid等(区分大小写)。 具体请参考onnx官方op文档或 工具链算子支持约束列表。 默认配置:无。 参数说明: 注:具体算子类型的int16支持情况可参考 工具链算子支持约束列表。
| 可选 |
preprocess_on补充说明
如果指定配置参数 preprocess_on=True:
工具可通过该设置 preprocess_on 为 True 来自动完成的校准图片的前处理。 该模式下需在 cal_data_dir 中指定校准JPEG图片的存放路径。 则在模型校准时,工具内部会通过skimage方式读入的JPEG图片,通过skimage resize的方式缩放图片到配置文件指定的 input_shape, 并把图像格式调整为 input_type_rt 指定的格式。
举一个例子,假如输入的JPEG图像的尺寸为608x608,则通过默认的预处理后,图像被缩放为224x224, 图像的内存格式调整为bgr(NCHW)的格式,像素值调整为0-255范围。
默认的预处理,请参考如下代码:
如果指定配置参数 preprocess_on=False:
您需要自行处理图片,将图片处理为 input_type_train 指定的格式,并且将数据以二进制形式保存为文件。 工具内部会自动增加从 input_type_train 到 input_type_rt 的格式转换。
注解
文件格式为: Row-major order 的uint8/float32数据存储。
6.2.2.2.4.4. 编译参数组¶
编 号 | 参数名称 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|
1 | compile_mode | 参数作用:编译策略选择。 取值范围: 'latency'、 'bandwidth'、 'balance'。 默认配置: 'latency'。 参数说明: latency 以优化推理时间为目标。 bandwidth 以优化ddr的访问带宽为目标。 balance 平衡优化目标latency和bandwidth,设置为此项需指定balance_factor。 如果模型没有严重超过预期的带宽占用,建议您使用 latency 策略。 | 可选 |
2 | balance_factor | 参数作用:当compile_mode被指定为balance时,用于指定balance比率。 取值范围:0-100。 默认配置:无。 参数说明:该参数仅在compile_mode被指定为balance时配套使用, 其余模式下配置不生效。
| compile_mode 为 balance 时必选 |
3 | debug | 参数作用:是否打开编译的debug信息。 取值范围: True 、 False。 默认配置: True。 参数说明:默认开启该参数的场景下, 模型的静态分析的性能结果将保存在模型中。 您可以在模型成功转换后生成的静态性能评估文件html页和hb_perf时产生的html页内, 在Layer Details选项卡中查看模型逐层BPU算子的性能信息, 包括计算量、原始算子输出shape、对齐后的算子输出shape、计算耗时、 数据搬运耗时以及以及编译后layer活跃时间段 (不代表该layer执行时间,通常为多个layer交替/并行执行)。 | 可选 |
4 | core_num | 参数作用:模型运行核心数。 取值范围: 1、 2。 默认配置: 1。 参数说明:地平线平台支持利用多个加速器核心同时完成一个推理任务。 多核心适用于输入尺寸较大的情况, 理想状态下的双核速度可以达到单核的1.5倍左右。 如果您的模型输入尺寸较大,对于模型速度有极致追求, 可以配置 core_num=2。 该选项在J5上仅支持配置为1! | 可选 |
5 | optimize_level | 参数作用:模型编译的优化等级选择。 取值范围: 'O0' 、 'O1' 、 'O2' 、 'O3'。 默认配置:'O0'。 参数说明:优化等级可选范围为 O0 ~ O3。 O0 不做任何优化, 编译速度最快,优化程度最低。 O1 - O3 随着优化等级提高, 预期编译后的模型的执行速度会更快, 但是所需编译时间也会变长。 正常用于生产和验证性能的模型, 必须使用 O3 级别优化才能保证得到最优性能。 某些流程验证或精度调试过程中, 可以尝试使用更低级别优化加快过程速度。 | 可选 |
6 | input_source | 参数作用:设置上板bin模型的输入数据来源。 取值范围: ddr, pyramid, resizer。 默认配置: 无,默认会根据input_type_rt的值从可选范围中自动选择:
参数说明:这个参数是适配工程环境的选项, 建议您已经全部完成模型检查后再配置。 ddr 表示数据来自内存,pyramid 和 resizer 表示来自处理器上的固定硬件。 在具体的工程环境中适配resizer数据源需要调用专有接口, 相关约束条件及说明请您参考 hbDNNRoiInfer接口说明。 此参数配置有些特殊,例如模型输入名称为 data, 数据源为内存(ddr), 则此处应该配置值为 {"data": "ddr"}。 | 可选 |
7 | max_time_per_fc | 参数作用:指定模型的每个function call的最大可连续执行时间(单位μs)。 取值范围:0或1000-4294967295。 默认配置:0。 参数说明:编译后的数据指令模型在BPU上进行推理计算时, 它将表现为1个或者多个function-call(BPU的执行粒度)的调用。 取值为0代表不做限制。 该参数用来限制每个function-call最大的执行时间, 模型只有在单个function-call执行完时才有机会被抢占。 详情参见 模型优先级控制 部分的介绍。 注意:
| 可选 |
8 | jobs | 参数作用:设置编译bin模型时的进程数。 取值范围:机器支持的最大核心数范围内。 默认配置:无。 参数说明:在编译bin模型时,用于设置进程数。 一定程度上可提高编译速度。 | 可选 |
9 | advice | 参数作用:用于提示模型编译后预估的耗时增加的情况,单位是微秒。 取值范围:自然数。 默认配置:无。不设置或设置为0则表示不开启。 参数说明:模型在编译过程中,工具链内部会进行耗时分析。而实际过程中, 如算子做数据对齐等操作时会导致耗时有所增加,设置该参数后, 当某个OP的实际计算耗时与理论计算耗时的偏差大于您指定的值时,会打印相关log, 包括耗时变化的信息、数据对齐前后的shape以及padding比例等信息。 | 可选 |
6.2.2.2.4.5. 自定义算子参数组¶
编 号 | 参数名称 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|
1 | custom_op_method | 参数作用:自定义算子策略选择。 取值范围:register。 默认配置:无。 参数说明:目前仅支持register策略,具体使用请参考 自定义算子开发。 | 可选 |
2 | op_register_files | 参数作用:指定自定义算子的Python实现文件名称。 取值范围:无。 默认配置:无。 参数说明:多个文件可用 ; 分隔,算子如何实现请参考 自定义算子开发。 | 可选 |
3 | custom_op_dir | 参数作用:指定自定义算子的Python实现文件存放路径。 取值范围:无。 默认配置:无。 参数说明:如果自定义算子的Python实现文件与工作目录在同一目录下,可不做设置。 设置路径时,请使用相对路径。 | 可选 |
6.2.2.2.5. param_value配置¶
具体参数的设置形式为:param_name: 'param_value' ,参数存在多个值时使用 ';' 符号分隔: param_name: 'param_value1; param_value2; param_value3' 。
小技巧
当模型为多输入模型时,强烈建议您将 input_shape 等参数们显式的写出,以免造成参数对应顺序上的错误。
注意
请注意,如果设置 input_type_rt 为 nv12 ,则模型的输入尺寸中不能出现奇数。
6.2.2.2.6. int16配置说明
在模型转换的过程中,模型中的大部分算子都会被量化到int8进行计算,而通过配置 node_info 参数, 可以详细指定某个op的输入/输出数据类型为int16计算(具体支持的算子范围可参考 工具链算子支持约束列表), 基本原理如下:
在您配置了某个op输入/输出数据类型为int16后,模型转换内部会自动进行op输入输出上下文(context)int16配置的更新和检查。 例如,当配置op_1输入/输出数据类型为int16时,实际上潜在同时指定了op_1的上/下一个op需要支持以int16计算。 对于不支持的场景,模型转换工具会打印log提示该int16配置组合暂时不被支持并回退到int8计算。
6.2.2.3. 模型推理命令(hb_mapper infer)¶
注意
hb_mapper infer 受 onnxruntime 限制,不支持动态的shape infer,因此要求输入的模型shape信息明确。
该工具不支持 infer 含有 shape信息为 ? 的模型。
该工具仅支持输入为四维且输出小于等于四维的非featuremap模型。
该命令利用浮点和量化模型进行推理,并保存推理结果到 --output-dir 指定的目录里面。
为了验证分析模型编译是否正确,可将配置文件中 layer_out_dump 设置为 True,它将会输出conv和输出节点的推理结果, 之后可以借助向量比较工具来分析模型编译的正确与否。
6.2.2.3.1. 使用方法
hb_mapper infer的使用方法:
在使用 hb_mapper infer 命令时,请输入与 hb_mapper makertbin 命令相同的配置文件,以保证输入数据处理的部分的设置是相同的。 简单地说,您在 hb_mapper makertbin 时使用的校准数据是什么样的图片或数据,那么在 hb_mapper infer 时也需要使用相同格式的图片或数据。
6.2.2.3.2. 命令行参数¶
hb_mapper infer的命令行参数:
--help
显示帮助信息并退出。
-c, --config
模型编译时的配置文件。
--model-file
进行推理的模型文件,可以是浮点和量化ONNX模型。
--model-type
指定推理的原始浮点模型类型,可指定为 caffe 或 onnx。
--image-file
输入节点名称和其对应的用于推理的图像文件。
--input-layout
模型输入的layout(此为可选参数)。
--output-dir
推理结果的保存路径,如果是量化模型,推理结果为反量化的浮点数据。
输出内容在 output_dir 目录里,输出文件命名规则: ${layername}_float.bin。
6.2.3. hb_perf工具
hb_perf 是用于分析地平线量化混合模型性能的分析工具。
6.2.3.1. 使用方法¶
6.2.3.2. 命令行参数
hb_perf的命令行参数:
--version
显示版本并退出。
-m
后接模型名称。在BIN_FILE为pack模型时指定所需模型,用于输出该指定模型的模型编译信息。
--help
显示帮助信息。
6.2.3.3. 输出内容说明
模型的信息会输出在当前目录的 hb_perf_result 文件夹中。 其中会有以该模型为名的文件夹,该模型信息将会展示在以其模型名称命名的 html 和 json 文件中。目录结构如下示例所示:
6.2.4. vec_diff工具
vec_diff 工具旨在帮助您定位精度异常问题。当出现精度异常时,可能有几种原因:
校准或者量化导致某一layer的输出存在误差,经过可能的误差放大,导致最终结果差异较大。
模型转换工具的某一步存在未知问题,浮点模型到定点模型转换过程中,经过了几次优化和变换,这些变换可能会存在问题,导致异常。
软件bug:在应该保证数值一致的地方,因为软件bug,导致误差。
为了定位这些问题,我们开发了向量比较工具。使用向量比较工具,可以比较不同阶段模型的卷积层输出差异。
6.2.4.1. 使用方式
vec_diff 工具,可以比较不同阶段模型的输出feature的差异,所以,第一步,需要得到模型的 infer 输出结果。
对于模型转换工具(hb_mapper)输出的模型,可以使用 infer 命令得到模型的输出向量文件。 具体使用,请参考 模型推理命令(hb_mapper infer) 。
对于*.bin模型,您可以上板运行,得到中间向量输出。 此过程请参考runtime工具文档 hrt_bin_dump工具介绍 。
6.2.4.2. 命令行参数¶
vec_diff的命令行参数:
--version
显示版本并退出。
left_file/folder
文件名,或者文件夹名。
right_file/folder
文件名,或者文件夹名。
-o, --output-file FILENAME
输出结果文件的文件名。
--help
打印帮助信息。
6.2.4.3. 输出内容说说明
由 vec_diff -o 指定的CSV文件,列表(表项为:左侧文件名,右侧文件名,余弦相似度、相对欧拉距、最大绝对误差、方差),参考如下:
Left Files | Right Files | Cosine Similarity | Relative Euclidean Distance | Max Absolute Error | Mean Square Error |
|---|---|---|---|---|---|
Layerxxx-quanti-input.txt | Layerxxx-float-input.txt | xxx | xxx | xxx | xxx |
Layerxxx-quanti-param.txt | Layerxxx-float-param.txt | xxx | xxx | xxx | xxx |
6.2.5. hb_model_info工具¶
hb_model_info 是用于解析混合模型(*.bin)编译时的依赖及参数信息的工具。
6.2.5.1. 使用方方法
6.2.5.2. 命令行参数¶
hb_model_info的命令行参数:
--version
显示版本并退出。
-m
后接模型名称。在BIN_FILE为pack模型时指定所需模型,用于输出该指定模型的模型编译信息。
--help
显示帮助信息。
6.2.5.3. 输出内容说明¶
输出部分将会是模型编译时的一些输入信息,如下所示:
注解
以下代码块中的版本号信息等内容将随发布包版本变化,此处仅为示例。
注解
当模型中存在被删除节点时,模型信息输出末尾会打印被删除节点的名称,同时会生成 deleted_nodes_info.txt 文件,文件中每一行记录了对应被删除节点的初始信息。打印被删除节点的名称如下所示:
6.2.6. hb_pack工具¶
hb_pack 是用于将多个混合模型(*.bin)文件打包为一个模型文件的工具。
6.2.6.1. 使用方法
6.2.6.2. 命令行参数¶
hb_pack的命令行参数:
--version
显示版本并退出。
-o, --output_name
pack模型的输出名称
--help
显示帮助信息。
6.2.6.3. 输出内容说明¶
打包的模型会输出在当前目录文件夹中,该模型会被命名为 output_name 指定名称。 该打包模型中所有子模型的编译信息及性能信息均可通过 hb_model_info 及 hb_perf 获取得到。
注意
注意,hb_pack 不支持对已经打包的模型再次进行打包,否则工作台将会产生以下提示:
6.2.7. hb_verifier工具
hb_verifier 工具是用于对指定的定点模型和runtime模型进行结果验证的工具。
若您使用工具前指定了图片,则 hb_verifier 工具会使用指定图片进行定点模型推理、runtime模型板端和X86端模拟器上的推理,并对结果进行两两比较, 给出是否通过的结论(此过程支持自选,您可以根据需要选择进行对比的内容)。
若您在使用工具前未指定图片,则 hb_verifier 工具会默认使用随机生成的tensor数据进行推理。
注意
在进行runtime模型在板端的推理时,需要确认给定ip可以ping通且板端已经安装 hrt_tools ,若无则可以使用OE包中 ddk/package/board 下的 install.sh 脚本进行安装。
在进行runtime模型在x86端的推理时,需要确保host端已经安装 hrt_tools,若无则可以使用OE包中 ddk/package/host/host_package/ 下的 install_host_package.sh 脚本进行安装。
在使用本工具前,以下内容需要请您注意:
注意
hb_verifier工具不支持除Dequantize节点外,有其他节点变化的bin模型与quanti.onnx进行对比。
如果在使用本工具前,您使用hb_model_modifier工具删除了bin模型的输出前的最后一个节点且该节点为非Dequantize节点,或者yaml文件中配置了 remove_node_type 参数, 从而删除了bin模型的输出前的最后一个节点且该节点为非Dequantize节点,那么hb_verifier工具将不再支持quanti.onnx和删除节点后的bin模型做对比。
如您想解决上述问题,需要避免出现上述删除bin模型的输出前的最后一个节点且该节点为非Dequantize节点的情况。
由于hb_verifier工具与板端通过SSH进行交互,故如您在OE Docker容器内使用本工具,请勿使用 docker attach 命令连接容器,使用此命令连接容器会导致与板端交互的SSH认证失败。
建议您运行OE包内部提供的 run_docker.sh 或使用 docker exec -it {容器 ID} /bin/bash 命令进入容器后再使用本工具。
6.2.7.1. 使用方式¶
6.2.7.2. 命令行参数
hb_verifier的命令行参数:
--version
显示版本并退出。
--help, -h
显示帮助信息。
--model, -m
定点模型名称和bin模型名称,多模型之间用”,”进行区分。
--board-ip, -b
上板测试使用的arm board ip地址。
--run-sim, -s
设置是否使用X86环境的libdnn做bin模型推理,默认为False。
当该参数设置为 True 时,工具将会使用x86环境的libdnn做bin模型推理。
当该参数设置为 False 时,工具不会使用x86环境的libdnn做bin模型推理。
--input-img, -i
指定推理测试时使用的图片。
若不指定则会使用随机生成的tensor数据。
若指定图片为二进制形式的图片文件,其文件形式需要为后缀名为 .bin 形式。
多输入模型添加图片的方式有以下两种传参方式,多张图片之间用”,”分割:
input_name1:image1,input_name2:image2, …
image1,image2…
注意
在多batch模型场景下,hb_verifier工具不支持输入配置为binary数据,建议直接指定为单batch图片,或者不指定输入使用随机数据进行一致性验证。
--compare_digits, -c
设置比较推理结果的数值精确度(即比较数值小数点后的位数),若不进行指定则工具会默认比较至小数点后五位。
--dump-all-nodes-results, -r
设置是否保存模型中各个算子的输出结果,并对算子输出名称相同的结果进行对比,默认为False。
当该参数设置为 True 时,工具将会获取模型中所有节点的输出,并根据节点输出的名字做匹配,从而进行对比。
当该参数设置为 False 时,工具将会只获取模型最终输出的结果,并进行对比。
注意
请您注意,目前基于性能考虑,暂不支持您在X86环境下使用dump功能。
--username, -u
用于指定开发板用户名,默认为 root 。
--password, -p
如您所使用的开发板带有密码,需键入板端密码。
注意
如所使用的开发板未设置密码,请勿主动输入此项。
6.2.7.3. 参考使用场景样例
1.quanti.onnx模型推理、bin模型在板端推理,bin模型在X86环境下进行推理,并对三方推理结果做对比:
2.quanti.onnx模型推理、bin模型在板端推理,并对两方推理结果做对比:
3.quanti.onnx模型推理、bin模型在板端推理,过程中会保存两方模型中各个算子的输出,并对算子输出名称相同的结果进行对比:
4.quanti.onnx模型推理、bin模型在X86环境下进行推理,并对两方推理结果做对比:
6.2.7.4. 输出内容说明
结果对比最终会在终端展示,工具会对比多个模型在不同场景下的运行结果,若无问题应显示如下:
在定点模型和runtime模型精度不一致时会输出不一致结果的具体信息,如下方log所示:
其中:
mismatch result num 为两种模型精度不一致结果的个数,包括三种不一致情况:
mismatch.line_miss num 为输出结果数量不一致的个数。
mismatch.line_diff num 为输出结果差距过大的个数。
mismatch.line_nan num 为输出为nan的个数。
total result num 为输出数据的总个数。
mismatch rate 为不一致数据个数占输出数据总个数的比例。
relative mismatch ratio 为相对误差比例,取误差比例最大的值进行展示。
max abs error 为最大绝对误差。
6.2.8. hb_model_modifier工具¶
hb_model_modifier 工具用于对指定的runtime模型中输入端的Transpose、Quantize、Cast、Reshape节点和输出端的Transpose、Dequantize、DequantizeFilter、Cast、Reshape、Softmax节点进行删除操作, 并将删除节点的信息存放在BIN模型中,可以通过 hb_model_info 进行查看。
注解
hb_model_modifier工具只能删除紧挨着模型输入或输出的节点。如果待删除节点后面如果接的是其他节点,则不能进行删除操作。
模型节点名称需要注意不要包括 “;” “,” 等特殊符号,否则可能会影响工具的使用。
工具不支持对打包的模型进行处理,否则将提示: ERROR pack model is not supported。
待删除节点会按顺序依次删除,并且会动态更新模型结构; 同时在节点删除前还会判断该节点是否位于模型的输入输出处,因此节点的删除顺序很重要。
由于删除特定节点后会对模型的输入情况有影响,因此工具只对模型输入后只有一条通路的情况适用,若如下图中所示,同一输入对应了多个节点的情况尚不支持。
6.2.8.1. 使用方式¶
查看可删除的节点:
删除单个指定节点(以node1为例):
删除多个指定节点(以node1、node2、node3为例):
删除某类节点(以Dequantize为例):
删除多种类型节点(以Reshape、Cast、Dequantize为例):
组合使用:
6.2.8.2. 命令行参数¶
hb_model_modifier的命令行参数:
model_file
runtime 模型文件名称。
-r
后接指定删除节点的名称。若有多个节点需要删除,需要指定多次。
-o
后接修改后的模型输出名称(仅在有 -r 参数时生效)。
-a, --all
后接节点类型。支持一键删除所有对应类型的功能。若有多个类型节点需要删除,需要指定多次。
6.2.8.3. 输出内容说明¶
若工具后不接任何参数,则工具会打印出可供候选的可删除节点(即模型中的位于输入输出位置的所有Transpose、Quantize、Dequantize、DequantizeFilter、Cast、Reshape、Softmax节点)。
其中Quantize节点用于将模型float类型的输入数据量化至int8类型,其计算公式如下:
round(x) 实现浮点数的四舍五入。
clamp(x) 函数实现将数据钳位在-128~127之间的整数数值。
scale 为量化比例因子。
zero_point 为非对称量化零点偏移值,对称量化时 zero_point = 0 。
C++的参考实现如下:
Dequantize节点则用于将模型int8或int32类型的输出数据反量化回float或double类型,其计算公式如下:
C++的参考实现如下:
注解
目前工具支持删除:
输入部位的节点为Quantize、Transpose、Cast、Reshape节点。
输出部位的节点为Transpose、Dequantize、DequantizeFilter、Cast、Reshape、Softmax节点。
工具打印信息如下:
在指定 -r 选项后,工具会打印模型中该节点的类型,储存在bin文件中的节点信息以及告知指定节点已被删除:
之后可以通过 hb_model_info 工具查看被删除节点信息,输出信息末尾会打印被删除节点的名称,同时会生成 deleted_nodes_info.txt 文件, 文件中每一行记录了对应被删除节点的初始信息(此处仅会记录Quantize、Dequantize、DequantizeFilter和Transpose类型的节点信息)。
打印被删除节点的名称步骤如下所示:
6.2.9. hb_custom_op工具
hb_custom_op 用于生成自定义算子的模板文件,生成python模板文件中包含了自定义OP(算子)的计算定义函数。 该文件在转换阶段会被使用。若没有此定义函数则无法完成转换中的校准阶段。
6.2.9.1. 使用方法¶
6.2.9.2. 命令行参数¶
hb_custom_op的命令行参数:
该命令会生成相应的python自定义OP的模板文件。
6.2.9.3. 输出内容说明
hb_custom_op create 命令将会生成含有自定义OP模板的python文件。
6.2.10. hb_eval_preprocess工具¶
用于对模型精度进行评估时,在x86环境下对图片数据进行预处理。所谓预处理是指图片数据在送入模型之前的特定处理操作。比如:图片resize、crop和padding等。
6.2.10.1. 使用方法¶
6.2.10.2. 命令行参数¶
hb_eval_preprocess的命令行参数:
--version
显示版本并退出。
-m, --model_name
设置模型名称,支持的模型范围可通过 hb_eval_preprocess --help 查看。
-i, --image_dir
输入图片路径。
-o, --output_dir
输出路径。
-v, --val_txt
设置评测所需图片的文件名称,预处理生成的图片将与此文件中的图片名称对应。
-h, --help
显示帮助信息。
6.2.10.3. 输出内容说明
hb_eval_preprocess 命令将会在 --output_dir 指定的路径下生成图片二进制文件。
小技巧
更多关于 hb_eval_preprocess 工具在上板模型精度评估中的应用示例请参见 数据预处理 一节内容。
6.2.11. HB_ONNXRuntime推理库¶
HB_ONNXRuntime是地平线基于公版ONNXRuntime封装的一套x86端的ONNX模型推理库。 除支持Pytorch、TensorFlow、PaddlePaddle、MXNet等各训练框架直接导出的ONNX原始模型外,还支持对地平线工具链进行PTQ转换过程中产出的各阶段ONNX模型进行推理。 使用流程如下图所示:
注解
请注意,地平线BPU架构的计算平台使用的是int8的计算精度(业内计算平台的通用精度),使用地平线工具链进行PTQ转换过程中, 虽然对于最终转换生成的bin模型的输入对于 input_type_rt 到 input_type_train 颜色空间的转换会配合处理器硬件完成, 但是对于转换过程中生成的onnx模型(非featuremap输入且 norm_type 未配置为 no_preprocess)前端插入的预处理节点却不包含硬件转换逻辑, 因此onnx模型的实际输入只是一种中间类型(除featuremap输入外,其他类型输入均需做-128操作,即由unit8转为int8), HB_ONNXRuntime内部会对此数据转换进行处理,但仅限如下不涉及数据损失的转换场景:
模型输入为int8:支持传入int8、uint8。
模型输入为uint8:支持传入为int8、uint8。
模型输入为float32:支持传入为int8、uint8及float32。
如涉及混合类型输入等会出现数据损失的转换,需先自行完成对应数据转换的处理,再进行推理。
6.2.11.1. 使用方法
使用HB_ONNXRuntime加载ONNX模型推理的基本流程如下所示,这份示例代码适用于所有ONNX模型的推理, 根据不同模型的输入类型和layout要求准备数据即可:
6.2.11.2. 参数说明¶
output_names:
用于配置输出名称,支持配置为None或自定义配置。
如配置为None,工具内部会读取模型内的输出节点信息并按解析的顺序给出推理结果。
如自定义配置,可以配置全量或部分output_name,且支持修改输出顺序。则推理完成后,会按您配置的输出名称和顺序返回输出。
input_info:
按照输入类型和layout准备模型运行的输入,配置格式要求为字典形式,输入名称和输入数据组成键值对,参考配置示例:{“input_name” : data}。
6.2.12. 精度debug工具¶
模型转换工具链会基于您提供的校准样本对模型进行校准量化并保障模型高效的部署在地平线计算平台上。 而在模型转换的过程中,难免会因为浮点到定点的量化过程而引入精度损失,通常情况下造成精度损失的主要原因可能有以下几点:
1.模型中的一部分节点对量化比较敏感会引入较大误差,即敏感节点量化问题。
2.模型中各个节点的误差累积导致模型整体出现较大的校准误差,主要包含:权重量化导致的误差累积、激活量化导致的误差累积以及全量量化导致的误差累积。
针对该情况,地平线提供了精度debug工具用以协助您自主定位模型量化过程中产生的精度问题。 该工具能够协助您对校准模型进行节点粒度的量化误差分析,最终帮助您快速定位出现精度异常的节点。
精度debug工具提供多种分析功能供您使用,例如:
获取节点量化敏感度。
获取模型累积误差曲线。
获取指定节点的数据分布。
获取指定节点输入数据通道间数据分布箱线图等。
6.2.12.1. 快速上手¶
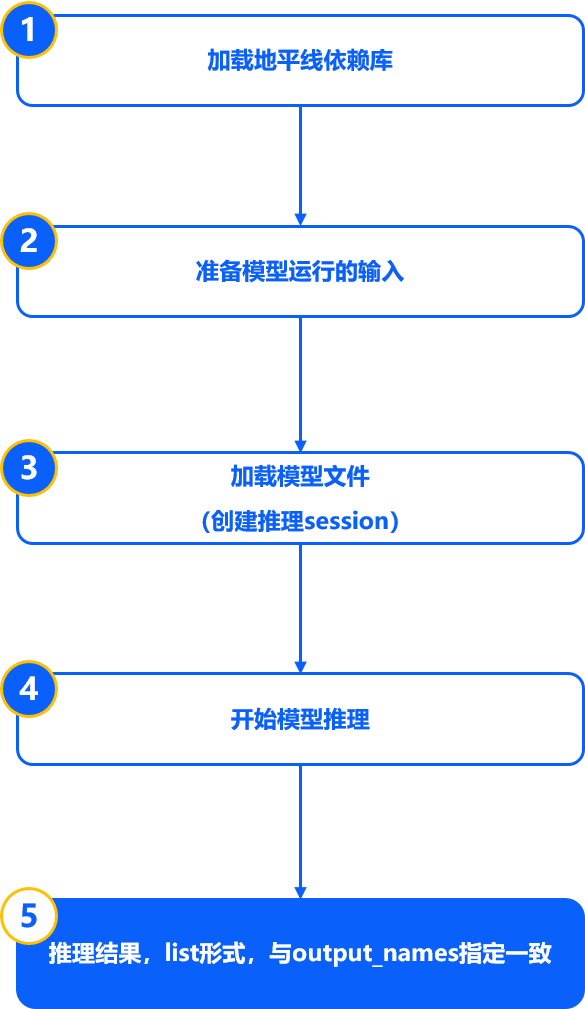
使用精度debug工具主要有以下几个步骤:
1.在yaml中的 模型参数组(model_parameters) 配置参数 debug_mode: "dump_calibration_data" ,保存校准数据。
2.导入debug模块,加载校准模型和数据。
3.通过精度debug工具提供的API或命令行,对精度损失明显的模型进行分析。
整体流程如下图所示:
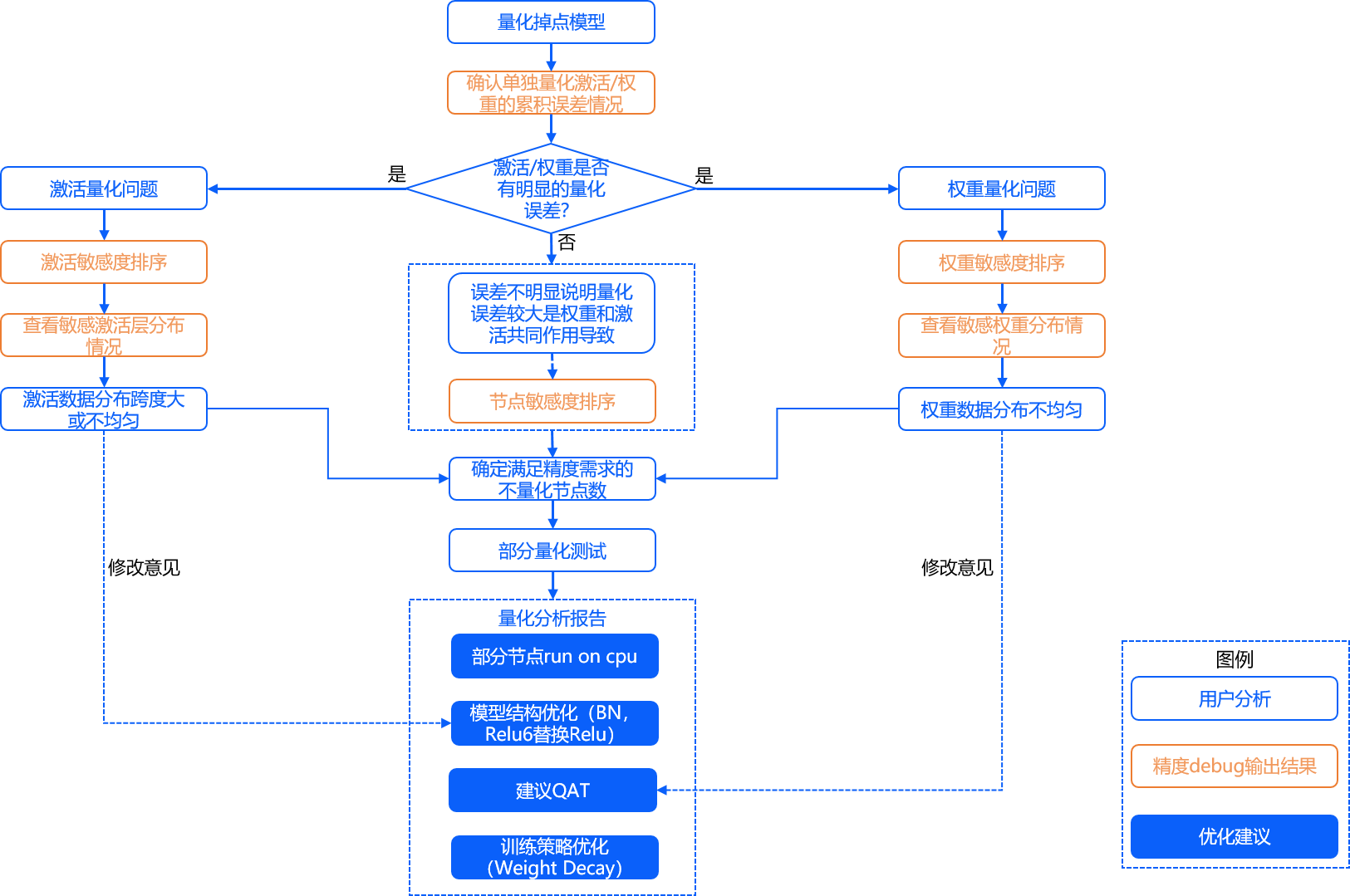
确认单独量化激活/权重的累积误差情况,详见:plot_acc_error 章节。
激活敏感度排序,详见:get_sensitivity_of_nodes 章节。
权重敏感度排序,详见:get_sensitivity_of_nodes 章节。
节点敏感度排序,详见:get_sensitivity_of_nodes 章节。
查看敏感激活层分布情况,详见:plot_distribution 章节以及 get_channelwise_data_distribution 章节。
查看敏感权重分布情况,详见:plot_distribution 章节以及 get_channelwise_data_distribution 章节。
敏感节点单独量化及部份量化测试,详见:sensitivity_analysis 章节。
6.2.12.1.1. 校准模型与数据的保存¶
首先需要在yaml文件中配置 debug_mode: "dump_calibration_data" ,以开启精度debug功能, 并保存校准数据(calibration_data),对应的校准模型(calibrated_model.onnx)为常态化保存。其中:
校准数据(calibration_data):在校准阶段,模型通过对这些数据进行前向推理来获取每个被量化节点的量化参数,包括:缩放因子(scale)和阈值(threshold)。
校准模型(calibrated_model.onnx):将在校准阶段计算得到的每个被量化节点的量化参数保存在校准节点中,从而得到校准模型。
注解
此处保存的校准数据与02_preprocess.sh生成的校准数据的区别?
02_preprocess.sh 得到的校准数据是bgr颜色空间的数据,在工具链内部会将数据从bgr转换到yuv444/gray等模型实际输入的格式。 而此处保存的校准数据则是经过颜色空间转换以及预处理之后保存的.npy格式的数据,该数据可以通过np.load()直接送入模型进行推理。
注解
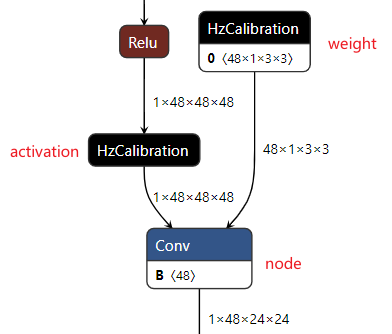
校准模型(calibrated_model.onnx)解读
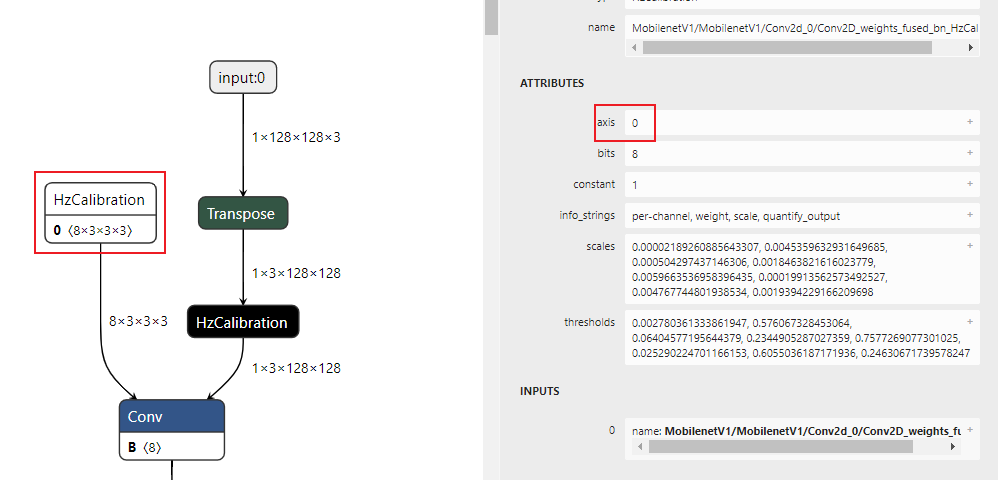
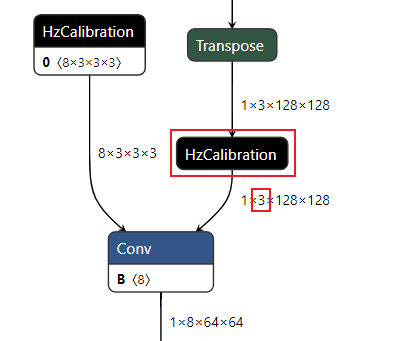
校准模型是模型转换工具链将浮点模型经过结构优化后,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中得到的中间产物。 校准模型的主要特点是模型中包含校准节点,校准节点的节点类型为HzCalibration。 这些校准节点主要分为两类: 激活(activation)校准节点 和 权重(weight)校准节点 。
激活校准节点 的输入是当前节点的上一个节点的输出,并基于当前激活校准节点中保存的量化参数(scales和thresholds)对输入数据进行量化及反量化后输出。
权重校准节点 的输入为模型的原始浮点权重,基于当前权重校准节点中保存的量化参数(scales和thresholds)对输入的原始浮点权重进行量化及反量化后输出。
除却上述的校准节点,校准模型中的其他节点,精度debug工具将其称为 普通节点(node) 。 普通节点 的类型包括:Conv、Mul、Add等。
calibration_data的文件夹结构如下:
6.2.12.1.2. 精度debug模块导入与使用
接下来需要在代码中导入debug模块,并通过 get_sensitivity_of_nodes 接口获取节点量化敏感度(默认使用模型输出的余弦相似度)。 get_sensitivity_of_nodes 的详细参数说明可见 get_sensitivity_of_nodes 章节。
6.2.12.1.3. 分析结果展示¶
下方为 verbose=True 时的打印结果:
除此之外,该API会以字典(Dict)的形式将节点量化敏感度信息返回给您以供后续使用分析。
更多功能详见 功能说明文档 章节。
为了方便您使用,精度debug工具还支持通过命令行进行使用,可通过 hmct-debugger -h/--help 查看 每个功能对应的子命令。各个子命令的详细参数和用法详见 功能说明文档 章节。
6.2.12.2. 功能说明文档¶
6.2.12.2.1. get_sensitivity_of_nodes¶
功能:获取节点量化敏感度。
命令行格式:
可通过 hmct-debugger get-sensitivity-of-nodes -h/--help 查看相关参数。
参数组:
编 号 | 参数名称 | 命令行参数缩写 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|---|
1 | model_or_file | 固定参数 | 参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 | 必选 |
2 | metrics | -m | 参数作用:节点量化敏感度的度量方式。 取值范围: 'cosine-similarity' , 'mse' , 'mre' , 'sqnr' , 'chebyshev' 。 默认配置: 'cosine-similarity'。 参数说明:指定节点量化敏感度的计算方式,该参数可以为列表(List), 即以多种方式计算量化敏感度, 但是输出结果仅以列表中第一位的计算方式进行排序, 排名越靠前说明量化该节点引入的误差越大。 | 可选 |
3 | calibrated_data | 固定参数 | 参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 | 必选 |
4 | output_node | -o | 参数作用:指定输出节点。 取值范围:校准模型中的具有对应校准节点的普通节点。 默认配置:None。 参数说明:此参数支持您指定中间节点作为输出并计算节点量化敏感度。 若保持默认参数None,则精度debug工具会获取模型的最终输出 并在此基础上计算节点的量化敏感度。 | 可选 |
5 | node_type | -n | 参数作用:节点类型。 取值范围: 'node' , 'weight' , 'activation'。 默认配置: 'node'。 参数说明:需要计算量化敏感度的节点类型,包括:node(普通节点)、 weight(权重校准节点)、activation(激活校准节点)。 | 可选 |
6 | data_num | -d | 参数作用:计算量化敏感度需要的数据数量。 取值范围:大于0,小于等于calibration_data中数据的总数。 默认配置:1 参数说明:设置计算节点量化敏感度时所需要的数据数量。 默认为None,此时默认使用calibration_data中的所有数据进行计算。 最小设置为1,最大为 calibration_data中的数据数量。 | 可选 |
7 | verbose | -v | 参数作用:选择是否将信息打印在终端上。 取值范围: True 、 False。 默认配置: False。 参数说明:若为True,则将量化敏感度信息打印在终端上。 若metrics包含多种度量方式,则按照第一位进行排序。 | 可选 |
8 | interested_nodes | -i | 参数作用:设置感兴趣节点。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:若指定则只获取该节点的量化敏感度,其余节点不获取。 同时,若该参数被指定,将忽视node_type指定的节点类型, 也就是说该参数的优先级要高于node_type。 若保持默认参数None,则计算模型中所有可被量化节点的量化敏感度。 | 可选 |
API使用方法:
命令行使用方法:
分析结果展示:
描述:首先您通过node_type设置需要计算敏感度的节点类型,然后工具获取校准模型中所有符合node_type的节点,并获取这些节点的量化敏感度。 当verbose设置为True时,工具会将节点量化敏感度进行排序后打印在终端,排序越靠前,说明该节点量化引入的量化误差越大。同时对于不同的node_type,工具会显示不同的节点量化敏感度信息。
verbose=True且node_type=’node’时,打印结果如下:
其中:
node:节点名。
cosine-similarity、mse:各个节点的量化敏感度数值。
verbose=True且node_type=’weight’时,打印结果如下:
其中:
weight:权重校准节点名。
node:权重校准节点对应的普通节点名,即权重校准节点的输出为其输入。
cosine-similarity、mse:各个节点的量化敏感度数值。
verbose=True且node_type=’activation’时,打印结果如下:
其中:
activation:激活校准节点名。
node:在模型结构中在激活校准节点后的普通节点,即激活校准节点的输出为其输入。
threshold:校准阈值,若有多个阈值则取最大值。
bit:量化比特。
cosine-similarity、mse:各个节点的量化敏感度数值。
API返回值:
API返回值为以字典格式(Key为节点名称,Value为节点的量化敏感度信息)保存的量化敏感度,格式如下:
6.2.12.2.2. plot_acc_error
功能:只量化浮点模型中的某一个节点,并依次计算该模型与浮点模型中节点输出的误差,获得累积误差曲线。
命令行格式:
可通过 hmct-debugger plot-acc-error -h/--help 查看相关参数。
参数组:
编 号 | 参数名称 | 命令行参数缩写 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|---|
1 | save_dir | -s | 参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:可选,指定分析结果的保存路径。 | 可选 |
2 | calibrated_data | 固定参数 | 参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准数据。 | 必选 |
3 | model_or_file | 固定参数 | 参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 | 必选 |
4 | quantize_node | -q | 参数作用:只量化模型中指定的节点,查看误差累积曲线。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:可选参数。指定模型中需要量化的节点,同时保证其余节点均不量化。 通过判断该参数是否为嵌套列表进而决定是单节点量化还是部分量化。 例如:
注:quantize_node和non_quantize_node不可同时为None,必须指定其一。 | 可选 |
5 | non_quantize_node | -nq | 参数作用:指定累积误差的类型。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:可选参数。指定模型中不量化的节点,同时保证其余节点全都量化。 通过判断该参数是否为嵌套列表进而决定是单节点不量化还是部分量化。 例如:
注:quantize_node和non_quantize_node不可同时为None,必须指定其一。 | 可选 |
6 | metric | -m | 参数作用:误差度量方式。 取值范围: 'cosine-similarity' , 'mse' , 'mre' , 'sqnr' , 'chebyshev' 默认配置: 'cosine-similarity'。 参数说明:设置计算模型误差的计算方式。 | 可选 |
7 | average_mode | -a | 参数作用:指定累积误差曲线的输出模式。 取值范围: True 、 False。 默认配置: False。 参数说明:默认为False。若为True,那么获取累积误差的平均值作为结果。 | 可选 |
分析结果展示
1.指定节点量化累积误差测试
指定单节点量化
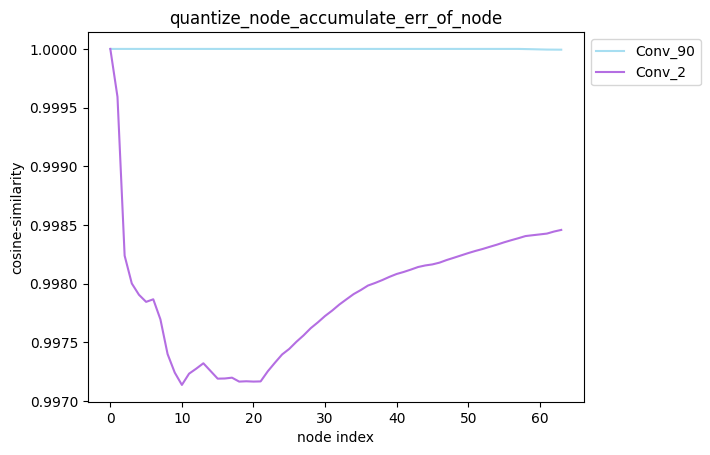
配置方式:quantize_node=[‘Conv_2’, ‘Conv_90’],quantize_node为单列表。
API使用方法:
命令行使用方法:
描述:当quantize_node为单列表时,针对您设置的quantize_node, 分别单独量化quantize_node中的节点并保持模型中其他节点不量化,得到对应的模型后, 对该模型中每个节点的输出计算其与浮点模型中对应节点输出的之间的误差,并得到对应的累积误差曲线。
average_mode = False时:
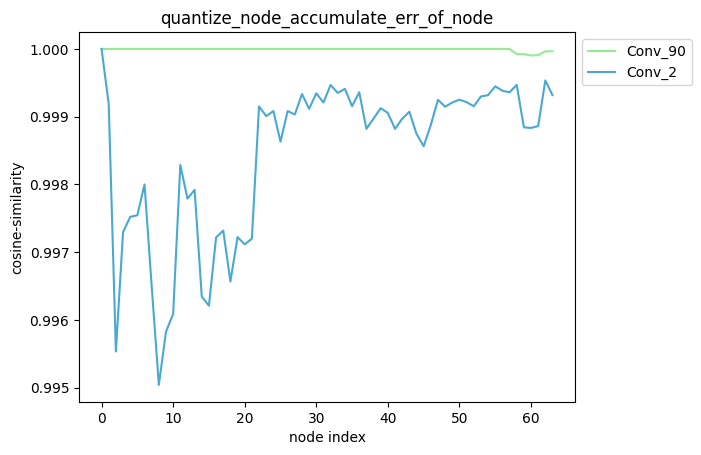
average_mode = True时:
注解
average_mode
average_mode默认为False。对于一些模型,此时无法通过累积误差曲线判断哪种量化策略更加有效, 因此需要将average_mode设置为True,此时会对前n个节点的累积误差求均值作为第n个节点的累积误差。
具体计算方式如下,例如:
average_mode=False时,accumulate_error=[1.0, 0.9, 0.9, 0.8]。
而将average_mode=True后,accumulate_error=[1.0, 0.95, 0.933, 0.9]。
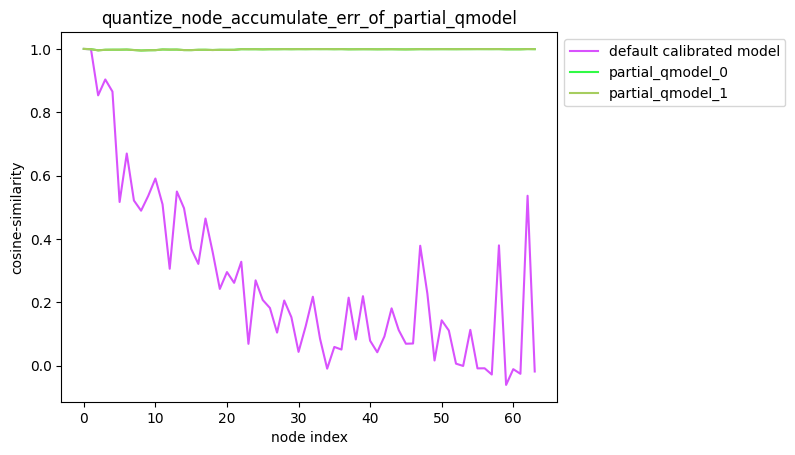
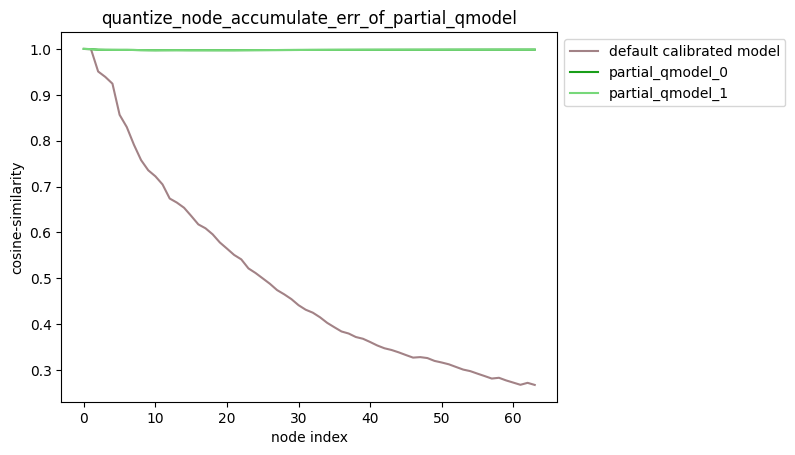
指定多个节点量化
配置方式:quantize_node=[[‘Conv_2’], [‘Conv_2’, ‘Conv_90’]],quantize_node为嵌套列表
API使用方法:
命令行使用方法:
描述:当quantize_node为嵌套列表时,针对您设置的quantize_node,分别量化quantize_node中的 每个单列表指定的节点并保持模型中其他节点不量化,得到对应的模型后,对该模型中每个节点的输出计算 其与浮点模型中对应节点输出的之间的误差,并得到对应的累积误差曲线。
partial_qmodel_0:只量化Conv_2节点,其余节点不量化;
partial_qmodel_1:只量化Conv_2和Conv_90节点,其余节点不量化。
average_mode=False时:
average_mode=True时:
2.解除模型部分节点量化后累积误差测试
指定单节点不量化
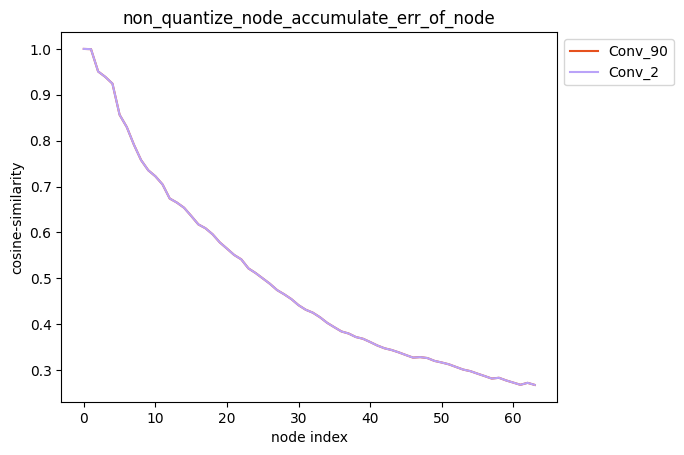
配置方式:non_quantize_node=[‘Conv_2’, ‘Conv_90’],non_quantize_node为单列表。
API使用方法:
命令行使用方法:
描述:当non_quantize_node为单列表时,针对您设置的non_quantize_node, 分别解除non_quantize_node中各个节点的量化同时保持其他节点全部量化,得到对应的模型后, 对该模型中每个节点的输出计算其与浮点模型中对应节点输出的之间的误差,并得到对应的累积误差曲线。
average_mode = False时:
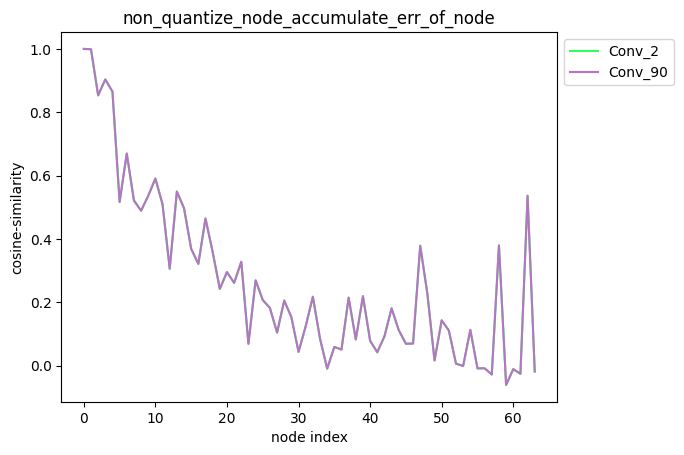
average_mode = True时:
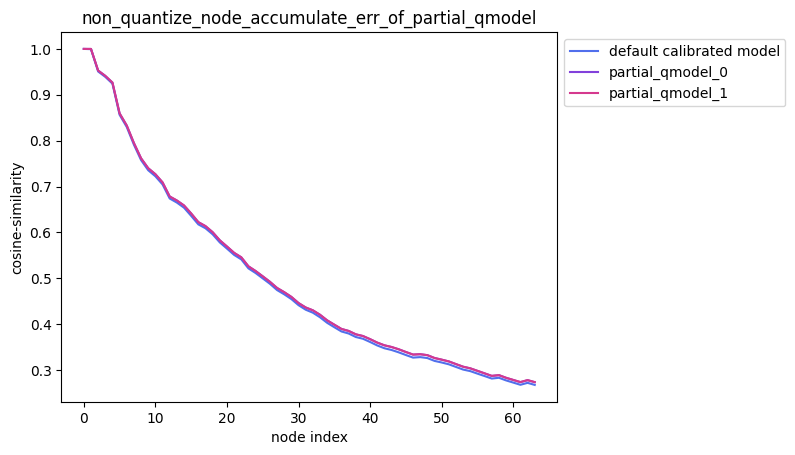
指定多个节点不量化
配置方式:non_quantize_node=[[‘Conv_2’], [‘Conv_2’, ‘Conv_90’]],non_quantize_node为嵌套列表。
API使用方法:
命令行使用方法:
描述:当non_quantize_node为嵌套列表时,针对您设置的non_quantize_node, 分别不量化non_quantize_node中的每个单列表指定的节点并保持模型中其他节点均量化, 得到对应的模型后,对该模型中每个节点的输出计算其与浮点模型中对应节点输出的之间的误差, 并得到对应的累积误差曲线。
partial_qmodel_0:不量化Conv_2节点,其余节点量化;
partial_qmodel_1:不量化Conv_2和Conv_90节点,其余节点量化。
average_mode = False时:
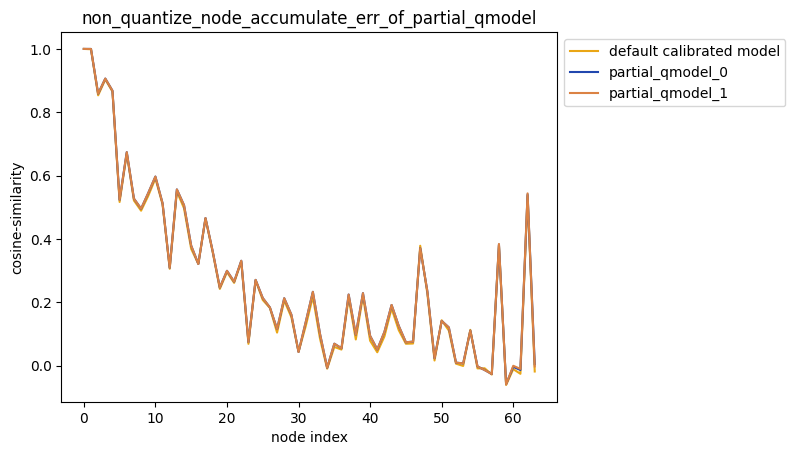
average_mode = True时:
测试技巧:
测试部分量化精度时,您可能会按照量化敏感度排序进行多组量化策略的精度对比,此时可以参考以下用法:
3.激活权重分别量化
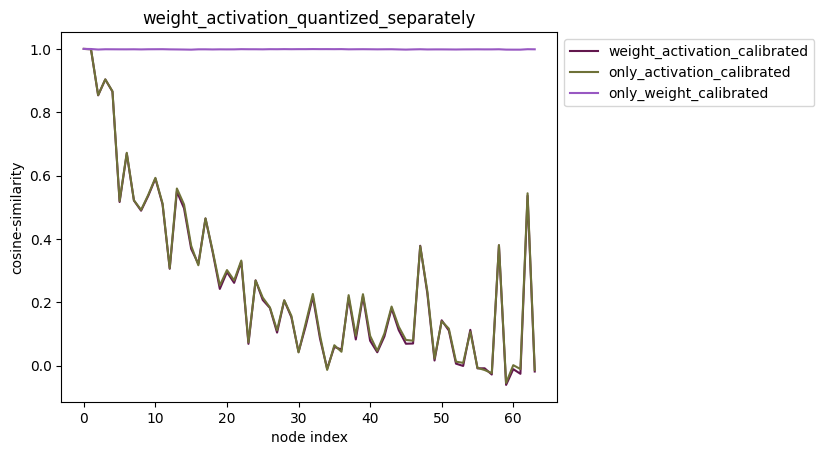
配置方式:quantize_node=[‘weight’,’activation’]。
API使用方法:
命令行使用方法:
描述:quantize_node也可直接指定’weight’或者’activation’。当:
quantize_node = [‘weight’]:只量化权重,不量化激活。
quantize_node = [‘activation’]:只量化激活,不量化权重。
quantize_node = [‘weight’, ‘activation’]:权重和激活分别量化。
注解
通常情况下,建议您对累积误差曲线图中靠近模型输出位置的曲线部分多加关注。 当采用某种量化方法后测试得到的累计误差曲线靠近模型输出位置的累积误差较小,即相似度较高时,我们建议您优先测试此种量化方法。
6.2.12.2.3. plot_distribution¶
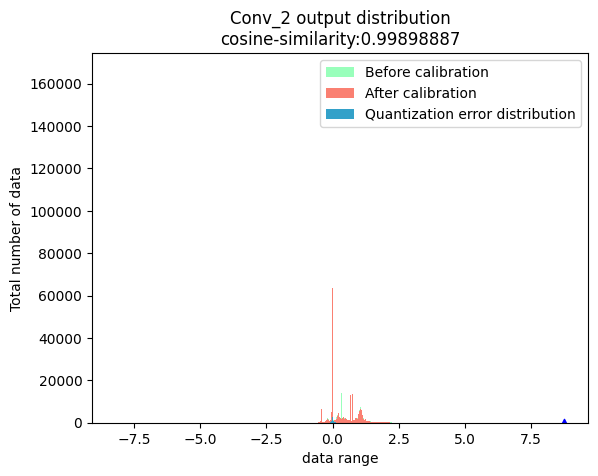
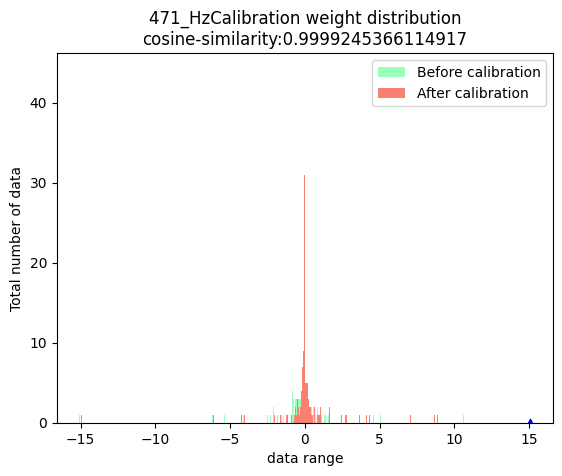
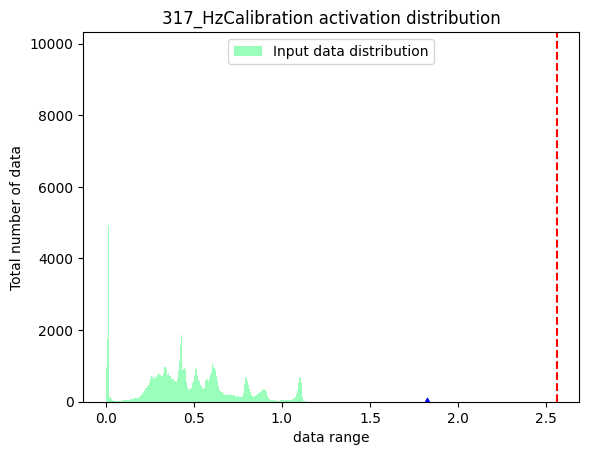
功能:选取节点,分别获取该节点在浮点模型和校准模型中的输出,得到输出数据分布。另外,将两个输出结果做差,获取两个输出之间的误差分布。
命令行格式:
可通过 hmct-debugger plot-distribution -h/--help 查看相关参数。
参数组:
编 号 | 参数名称 | 命令行参数缩写 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|---|
1 | save_dir | -s | 参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:可选,指定分析结果的保存路径。 | 可选 |
2 | model_or_file | 固定参数 | 参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 | 必选 |
3 | calibrated_data | 固定参数 | 参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 | 必选 |
4 | nodes_list | -n | 参数作用:指定需要分析的节点。 取值范围:校准模型中的所有节点。 默认配置:无。 参数说明:必选,指定需要分析的节点。若nodes_list中的节点类型为:
注:nodes_list为 list 类型,可指定一系列节点,并且上述三种类型节点 可同时指定。 | 必选 |
分析结果展示:
API使用方法:
命令行使用方法:
node_output:
weight:
activation:
注解
上方三幅图中,蓝色三角表示:数据绝对值的最大值。红色虚线表示:最大的校准阈值。
6.2.12.2.4. get_channelwise_data_distribution¶
功能:绘制指定校准节点输入数据通道间数据分布的箱线图。
命令行格式:
可通过 hmct-debugger get-channelwise-data-distribution -h/--help 查看相关参数。
参数组:
编 号 | 参数名称 | 命令行参数缩写 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|---|
1 | save_dir | -s | 参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:可选,指定分析结果的保存路径。 | 可选 |
2 | model_or_file | 固定参数 | 参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 | 必选 |
3 | calibrated_data | 固定参数 | 参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 | 必选 |
4 | nodes_list | -n | 参数作用:指定校准节点。 取值范围:校准模型中的所有权重校准节点和激活校准节点。 默认配置:无。 参数说明:必选,指定校准节点。 | 必选 |
5 | axis | -a | 参数作用:指定channel所在的维度。 取值范围:小于节点输入数据的维度。 默认配置:None。 参数说明:channel信息所在shape中的位置。 参数默认为None,此时对于激活校准节点, 默认认为节点输入数据的第二个维度表示channel信息,即axis=1; 对于权重校准节点,会读取该节点属性中的axis参数作为channel信息。 | 可选 |
分析结果展示:
描述:针对您设置的校准节点列表node_list,从参数axis中获取channel所在的维度,获取节点输入数据通道间的数据分布。 其中axis默认为None,此时若节点为权重校准节点,则channel所在的维度默认为0;若节点为激活校准节点,则channel所在的维度默认为1。
权重校准节点:
激活校准节点:
输出结果如下图所示:

图中:
横坐标表示节点输入数据的通道数,图例中输入数据有96个通道。
纵坐标表示每个channel的数据分布范围,其中红色实线表示该channel数据的中位数,蓝色虚线表示均值。每个箱子的上下限分别表示上四分位数和下四分位数,上下限之外的离散点表示异常值,通过观察这些异常值绝对值的最大值来判断当前节点输入数据是否出现较大波动的情况。
关于如何通过观察箱线图判断节点是否存在量化风险,请参考PTQ精度debug示例: MobileVit_s精度问题分析。
6.2.12.2.5. sensitivity_analysis
功能:针对量化敏感节点,分别分析测试单独量化以及部分量化这些节点后的模型精度。
命令行格式:
可通过 hmct-debugger sensitivity-analysis -h/--help 查看相关参数。
参数组:
编 号 | 参数名称 | 命令行参数缩写 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|---|
1 | model_or_file | 固定参数 | 参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 | 必选 |
2 | calibrated_data | 固定参数 | 参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 | 必选 |
3 | pick_threshold | -p | 参数作用:设置选取节点的敏感度阈值。 取值范围:无。 默认配置:0.999。 参数说明:可选,此功能计算普通节点的量化敏感度,选择敏感度小于 pick_threshold的节点作为敏感节点进行分析测试。 注:当设置sensitive_nodes时,则直接对sensitive_nodes进行测试,不再 另行计算节点敏感度并根据pick_threshold选择敏感节点。 | 可选 |
4 | data_num | -d | 参数作用:计算量化敏感度需要的数据数量。 取值范围:大于0,小于等于calibration_data中数据的总数。 默认配置:1。 参数说明:设置计算节点量化敏感度时所需要的数据数量。 | 可选 |
5 | sensitive_nodes | -sn | 参数作用:指定需要分析的敏感节点。 取值范围:校准模型中的所有节点。 默认配置:无。 参数说明:可选,指定需要分析的敏感节点。 注:当设置此参数时,则直接对此参数中的节点进行测试,不再另行计算 节点敏感度并根据pick_threshold选择敏感节点。 | 可选 |
6 | save_dir | -sd | 参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:可选,指定分析结果的保存路径。 | 可选 |
API使用方法:
命令行使用方法:
分析结果展示:
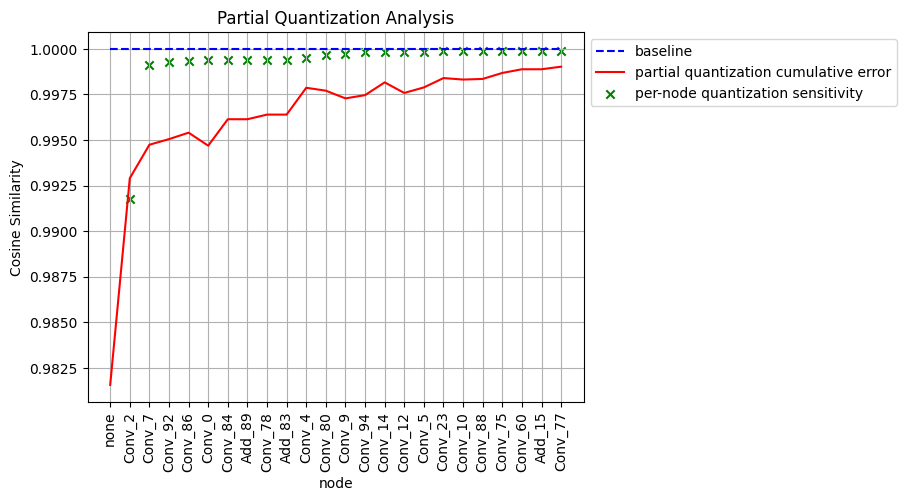
图中:
蓝色虚线:baseline,即浮点模型输出与自身的余弦相似度,为1。
绿色x :只量化当前节点得到部分量化模型,计算部分量化模型与浮点模型最终输出的相似度。
红色实线:不量化当前节点以及当前节点前的所有节点,计算部分量化模型与浮点模型最终输出的相似度。例如:上图中 Conv_92对应的相似度数值大概在0.995左右,表明解除Conv_2、Conv_7和Conv_92节点的量化并保持其余所有节点量化得到部分量化模型,该部分量化模型的最终输出与浮点模型的最终输出之间的余弦相似度为0.995左右。 横坐标第一个none,在红色实线中的含义为calibrated_model。
6.2.12.2.6. runall
功能:一键运行原本debug工具中的所有功能。
命令行格式:
可通过 hmct-debugger runall -h/--help 查看相关参数。
参数组:
编 号 | 参数名称 | 命令行参数缩写 | 参数配置说明 | 可选/ 必选 |
|---|---|---|---|---|
1 | model_or_file | 固定参数 | 参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 | 必选 |
2 | calibrated_data | 固定参数 | 参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 | 必选 |
3 | save_dir | -s | 参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:指定分析结果的保存路径。 | 可选 |
4 | ns_metrics | -nm | 参数作用:节点量化敏感度的度量方式。 取值范围: 'cosine-similarity' , 'mse' , 'mre' , 'sqnr' , 'chebyshev' 。 默认配置: 'cosine-similarity'。 参数说明:指定节点量化敏感度的计算方式,该参数可以为列表(List), 即以多种方式计算量化敏感度, 但是输出结果仅以列表中第一位的计算方式进行排序, 排名越靠前说明量化该节点引入的误差越大。 | 可选 |
5 | output_node | -o | 参数作用:指定输出节点。 取值范围:校准模型中的具有对应校准节点的普通节点。 默认配置:None。 参数说明:此参数支持您指定中间节点作为输出并计算节点量化敏感度。 若保持默认参数None,则精度debug工具会获取模型的最终输出 并在此基础上计算节点的量化敏感度。 | 可选 |
6 | node_type | -nt | 参数作用:节点类型。 取值范围: 'node' , 'weight' , 'activation'。 默认配置: 'node'。 参数说明:需要计算量化敏感度的节点类型,包括:node(普通节点)、 weight(权重校准节点)、activation(激活校准节点)。 | 可选 |
7 | data_num | -dn | 参数作用:计算量化敏感度需要的数据数量。 取值范围:大于0,小于等于calibration_data中数据的总数。 默认配置:None 参数说明:设置计算节点量化敏感度时所需要的数据数量。 默认为None,此时默认使用calibration_data中的所有数据进行计算。 最小设置为1,最大为 calibration_data中的数据数量。 | 可选 |
8 | verbose | -v | 参数作用:选择是否将信息打印在终端上。 取值范围: True 、 False。 默认配置: False。 参数说明:若为True,则将量化敏感度信息打印在终端上。 若metrics包含多种度量方式,则按照第一位进行排序。 | 可选 |
9 | interested_nodes | -i | 参数作用:设置感兴趣节点。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:若指定则只获取该节点的量化敏感度,其余节点不获取。 同时,若该参数被指定,将忽视node_type指定的节点类型, 也就是说该参数的优先级要高于node_type。 若保持默认参数None,则计算模型中所有可被量化节点的量化敏感度。 | 可选 |
10 | dis_nodes_list | -dnl | 参数作用:指定需要分析的节点。 取值范围:校准模型中的所有节点。 默认配置:无。 参数说明:指定需要分析的节点。若nodes_list中的节点类型为:
注:nodes_list为 list 类型,可指定一系列节点,并且上述三种类型节点 可同时指定。 | 可选 |
11 | cw_nodes_list | -cn | 参数作用:指定校准节点。 取值范围:校准模型中的所有权重校准节点和激活校准节点。 默认配置:无。 参数说明:指定校准节点。 | 可选 |
12 | axis | -a | 参数作用:指定channel所在的维度。 取值范围:小于节点输入数据的维度。 默认配置:None。 参数说明:channel信息所在shape中的位置。 参数默认为None,此时对于激活校准节点, 默认认为节点输入数据的第二个维度表示channel信息,即axis=1; 对于权重校准节点,会读取该节点属性中的axis参数作为channel信息。 | 可选 |
13 | quantize_node | -qn | 参数作用:只量化模型中指定的节点,查看误差累积曲线。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:可选参数。指定模型中需要量化的节点,同时保证其余节点均不量化。 通过判断该参数是否为嵌套列表进而决定是单节点量化还是部分量化。 例如:
注:quantize_node和non_quantize_node不可同时为None,必须指定其一。 | 可选 |
14 | non_quantize_node | -nqn | 参数作用:指定累积误差的类型。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:可选参数。指定模型中不量化的节点,同时保证其余节点全都量化。 通过判断该参数是否为嵌套列表进而决定是单节点不量化还是部分量化。 例如:
注:quantize_node和non_quantize_node不可同时为None,必须指定其一。 | 可选 |
15 | ae_metric | -am | 参数作用:累积误差度量方式。 取值范围: 'cosine-similarity' , 'mse' , 'mre' , 'sqnr' , 'chebyshev' 默认配置: 'cosine-similarity'。 参数说明:设置计算模型误差的计算方式。 | 可选 |
16 | average_mode | -avm | 参数作用:指定累积误差曲线的输出模式。 取值范围: True 、 False。 默认配置: False。 参数说明:默认为False。若为True,那么获取累积误差的平均值作为结果。 | 可选 |
17 | pick_threshold | -pt | 参数作用:设置选取节点的敏感度阈值。 取值范围:无。 默认配置:0.999。 参数说明:可选,此功能计算普通节点的量化敏感度,选择敏感度小于 pick_threshold的节点作为敏感节点进行分析测试。 注:当设置sensitive_nodes时,则直接对sensitive_nodes进行测试,不再 另行计算节点敏感度并根据pick_threshold选择敏感节点。 | 可选 |
18 | sensitive_nodes | -sn | 参数作用:指定需要分析的敏感节点。 取值范围:校准模型中的所有节点。 默认配置:无。 参数说明:可选,指定需要分析的敏感节点。 注:当设置此参数时,则直接对此参数中的节点进行测试,不再另行计算 节点敏感度并根据pick_threshold选择敏感节点。 | 可选 |
API使用方法:
命令行使用方法:
runall流程:

当所有参数保持默认时,工具会依次执行以下功能:
step1和step2:分别获取权重校准节点和激活校准节点的量化敏感度。
step3:根据step1和step2的结果,分别取权重校准节点的top5和激活校准节点的top5绘制其数据分布。
step4:针对step3获取的节点,分别绘制其通道间数据分布的箱线图。
step5:绘制分别只量化权重和只量化激活的累积误差曲线。
step6:针对敏感节点进行部分量化以及单节点量化精度分析,由于图中示例并没有指定sensitive_nodes,因此需要debug工具自行计算普通节点的量化敏感度并选取敏感度小于指定pick_threshold的节点进行测试分析。
当指定 node_type='node' 时,工具会获取top5节点,并分别找到每个节点对应的校准节点,并获取校准节点的数据分布和箱线图。