
6.3.1. 浮点模型准备
在您阅读本节内容前,我们建议您先阅读我们的 工具链算子支持约束列表 章节, 对地平线支持的算子及约束条件进行了解。 或在您导出ONNX模型后,可以先参考 验证模型 章节的内容, 验证模型是否能被地平线支持完成正常转换部署。
基于公开DL框架训练得到的浮点模型是转换工具的输入,目前转换工具支持的DL框架如下:
框架 | 地平线工具链 |
|---|---|
Caffe | 支持 |
PyTorch | 支持(转ONNX) |
TensorFlow | 支持(转ONNX) |
PaddlePaddle | 支持(转ONNX) |
MXNet | 支持(转ONNX) |
其他框架 | 请联系地平线 |
以上框架中,Caffe导出的caffemodel是直接支持的,PyTorch、TensorFlow和MXNet是通过转到ONNX实现间接支持,ONNX目前主要支持的opset版本是opset10和opset11。
对于不同框架到ONNX的转换,目前都有对应的标准化方案,参考如下:
🔗 Pytorch2Onnx:PytTorch官方API支持直接将模型导出为ONNX模型,参考链接:
https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html。
🔗 Tensorflow2Onnx:基于ONNX社区的 onnx/tensorflow-onnx 进行转换,参考链接:
https://github.com/onnx/tensorflow-onnx。
🔗 PaddlePaddle2Onnx:PaddlePaddle官方API支持直接将模型导出为ONNX模型,参考链接:
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/onnx/export_cn.html。
🔗 MXNet2Onnx:MXNet官方API支持直接将模型导出为ONNX模型,参考链接:
https://github.com/dotnet/machinelearning/blob/master/test/Microsoft.ML.Tests/OnnxConversionTest.cs。
🔗 更多框架的ONNX转换支持,参考链接:
https://github.com/onnx/tutorials#converting-to-onnx-format。
注意
原始模型限制:ir_version≤7, opset=10或11,ir_version与onnx版本的对应关系请参考 onnx官方文档 。
6.3.2. 验证模型
为了确保模型能顺利在地平线平台高效运行,模型中所使用的算子需要符合平台的算子约束。 算子约束部分给出了我们支持的具体算子,每个算子都给出了具体的参数限制, 具体详细信息请参考 工具链算子支持约束列表 章节的内容。
6.3.2.1. 使用hb_mapper checker工具验证模型¶
考虑到地平线支持的算子较多,为了避免人工逐条校对的麻烦,我们提供了 hb_mapper checker 工具用于验证模型所使用算子的支持情况。 工具使用方法请参考 模型检查命令(hb_mapper checker) 章节。
6.3.2.2. 检查异常处理
如果模型检查不通过, hb_mapper checker 工具会报出ERROR。 在当前工作目录下会生成 hb_mapper_checker.log 文件,从文件中可以查看到具体的报错。 例如以下配置中含不可识别算子类型 Accuracy:
使用 hb_mapper checker 检查这个模型,您会在 hb_mapper_checker.log 中得到如下信息:
6.3.2.3. 检查结果解读
如果不存在ERROR,则顺利通过校验。 hb_mapper checker 工具将直接输出如下信息:
结果中每行都代表一个模型节点的check情况,每行含Node、ON、Subgraph和Type四列, 分别为节点名称、执行节点计算的硬件、节点所属子图和节点映射到的地平线内部实现名称。 如果模型在非输入和输出部分出现了CPU计算的算子,工具将把这个算子前后连续在BPU计算的部分拆分为两个Subgraph(子图)。
6.3.2.4. 检查结果的调优指导¶
在最理想的情况下,非输入和输出部分都应该在BPU上运行,也就是只有一个子图。 如果出现了CPU算子导致拆分多个子图, hb_mapper checker 工具会给出导致CPU算子出现的具体原因。 例如以下ONNX模型的出现了Mul + Add + Mul的结构,从算子约束列表中我们可以看到,Mul和Add算子在五维上支持BPU运行有约束条件。
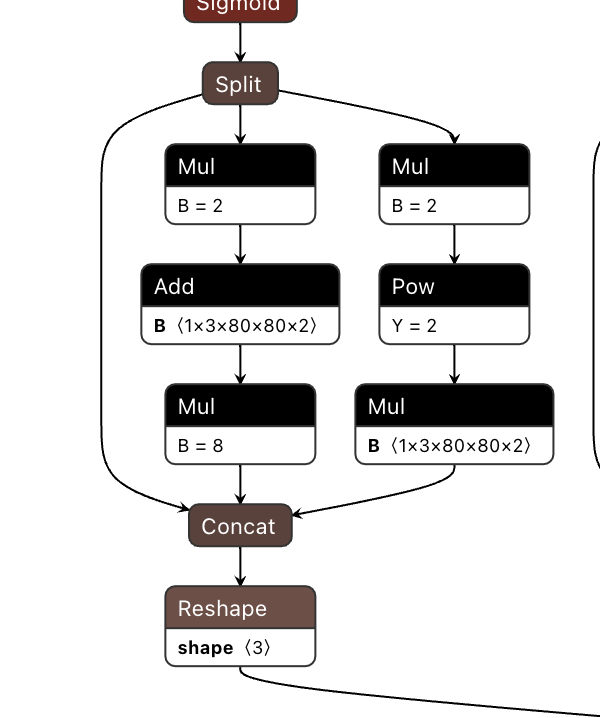
因此模型最终检查结果也会出现分段情况,如下:
注意
请注意,这里log结果仅用作示例,在使用过程中,请以您使用的版本实际打印的log情况为准。
根据 hb_mapper checker 给出的提示,一般来说算子运行在BPU上会有更好的性能表现。 当然,多个子图也不会影响整个转换流程,但会较大程度地影响模型性能,建议尽量调整至全BPU执行。
6.3.3. 校准数据准备
注解
如果本过程您需在示例文件夹内进行,那么您需要先执行文件夹中的 00_init.sh 脚本以获取对应的原始模型和数据集。
在进行模型转换时,校准阶段会需要20~100份的标定样本输入,每一份样本都是一个独立的数据文件。 为了确保转换后模型的精度效果,我们希望这些校准样本来自于您训练模型使用的训练集或验证集, 不要使用非常少见的异常样本,例如纯色图片、不含任何检测或分类目标的图片等。
转换配置文件中的 preprocess_on 参数,该参数启用和关闭状态下分别对应了两种不同的预处理样本要求。 有关参数的详细配置可参考 校准参数组 中的相关说明。
preprocess_on 关闭状态下,您需要把取自训练集/验证集的样本做与inference前一样的前处理, 处理完后的校准样本会与原始模型具备一样的数据类型( input_type_train )、尺寸( input_shape )和layout( input_layout_train ), 对于featuremap输入的模型,您可以通过 numpy.tofile 命令将数据保存为float32格式的二进制文件, 工具链校准时会基于 numpy.fromfile 命令进行读取。 例如,有一个使用ImageNet训练的用于分类的原始浮点模型,它只有一个输入节点,输入信息描述如下:
输入类型: BGR。
输入layout: NCHW。
输入尺寸: 1x3x224x224。
使用验证集做Inference时的数据预处理步骤如下:
图像长宽等比scale,短边缩放到256。
center_crop 方法获取224x224大小图像。
转换输入layout为模型所需的 NCHW 。
转换色彩空间为模型所需的 BGR 。
归一化处理。
依照 preprocess_on 关闭状态下的样本文件制作原则, 针对上述举例模型的样本处理代码如下(为避免过长代码篇幅,各种简单transformer实现代码未贴出,transformer使用方法可参考 图片处理transformer说明 ):
小技巧
preprocess_on 启用状态下,标定样本使用skimage支持读取的图片格式文件即可。 转换工具读取这些图片后,会将其缩放到模型输入节点要求的尺寸大小,以此结果作为校准的输入。 这样的操作会简单,但是对于量化的精度没有保障,因此我们强烈建议您使用关闭 preprocess_on 的方式。
注意
请注意,yaml文件中input_shape参数作用为指定原始浮点模型的输入数据尺寸。若为动态输入模型则可通过这个参数设置转换后的输入大小,而校准数据的shape大小应与input_shape保持一致。
例如:若原始浮点模型输入节点shape为?x3x224x224(“?”号代表占位符,即该模型第一维为动态输入),转换配置文件中设置input_shape: 8x3x224x224,则需要准备的每份校准数据大小为8x3x224x224。 (请知悉,此类输入shape第一维不等于1的模型,不支持通过input_batch参数修改模型batch信息。)
6.3.4. 模型量化与编译
转换模型阶段会完成浮点模型到地平线混合异构模型的转换,经过这个阶段,您将得到一个可以在地平线计算平台上运行的模型。 在进行转换之前,请确保已经顺利通过了 验证模型 小节的过程。
模型转换期间会完成模型优化和校准量化等重要过程,校准需要依照模型预处理要求准备校准数据, 您可以参考 校准数据准备 章节内容对校准数据进行预先准备。
6.3.4.1. 使用hb_mapper makertbin工具转换模型
模型转换过程使用 hb_mapper makertbin 工具完成,工具的使用方法及相关的具体配置、参数请参考 模型编译命令(hb_mapper makertbin) 章节。
6.3.4.2. 转换内部过程解读
模型转换完成浮点模型到地平线混合异构模型的转换。 为了使得这个异构模型能快速高效地在嵌入式端运行, 模型转换重点在解决 输入数据处理 和 模型优化编译 两个问题,本节会依次围绕这两个重点问题展开。
输入数据处理 方面地平线的边缘计算平台会为某些特定类型的输入通路提供硬件级的支撑方案, 但是这些方案的输出不一定符合模型输入的要求。 例如视频通路方面就有视频处理子系统,为采集提供图像裁剪、缩放和其他图像质量优化功能,这些子系统的输出往往是yuv420格式图像, 而我们的算法模型往往是基于bgr/rgb等一般常用图像格式训练得到的。 地平线针对此种情况提供的固定解决方案是,每个转换模型都提供两份输入信息描述, 一份用于描述原始浮点模型输入( input_type_train 和 input_layout_train), 另一份则用于描述我们需要对接的边缘平台输入数据( input_type_rt 和 input_layout_rt)。
图像数据的mean/scale也是比较常见的操作,显然yuv420等边缘平台数据格式不再适合做这样的操作, 因此,我们也将这些常见图像前处理固化到了模型中。 经过以上两种处理后,转换产出的异构模型的输入部分将变成如下图状态。

上图中的数据排布就只有NCHW和NHWC两种数据排布格式,N代表数量、C代表channel、H代表高度、W代表宽度, 两种不同的排布体现的是不同的内存访问特性。在TensorFlow模型中,NHWC格式较常用,而Caffe模型中就都使用NCHW格式, 地平线平台不会限制使用的数据排布,但是有两条要求:
input_layout_train 必须与原始模型的数据排布一致。
需要在边缘平台准备好与 input_layout_rt 一致排布的数据,正确的数据排布指定是顺利解析数据的基础。
模型优化编译 方面完成了模型解析、模型优化、模型校准与量化、模型编译几个重要阶段,其内部工作过程如下图所示。
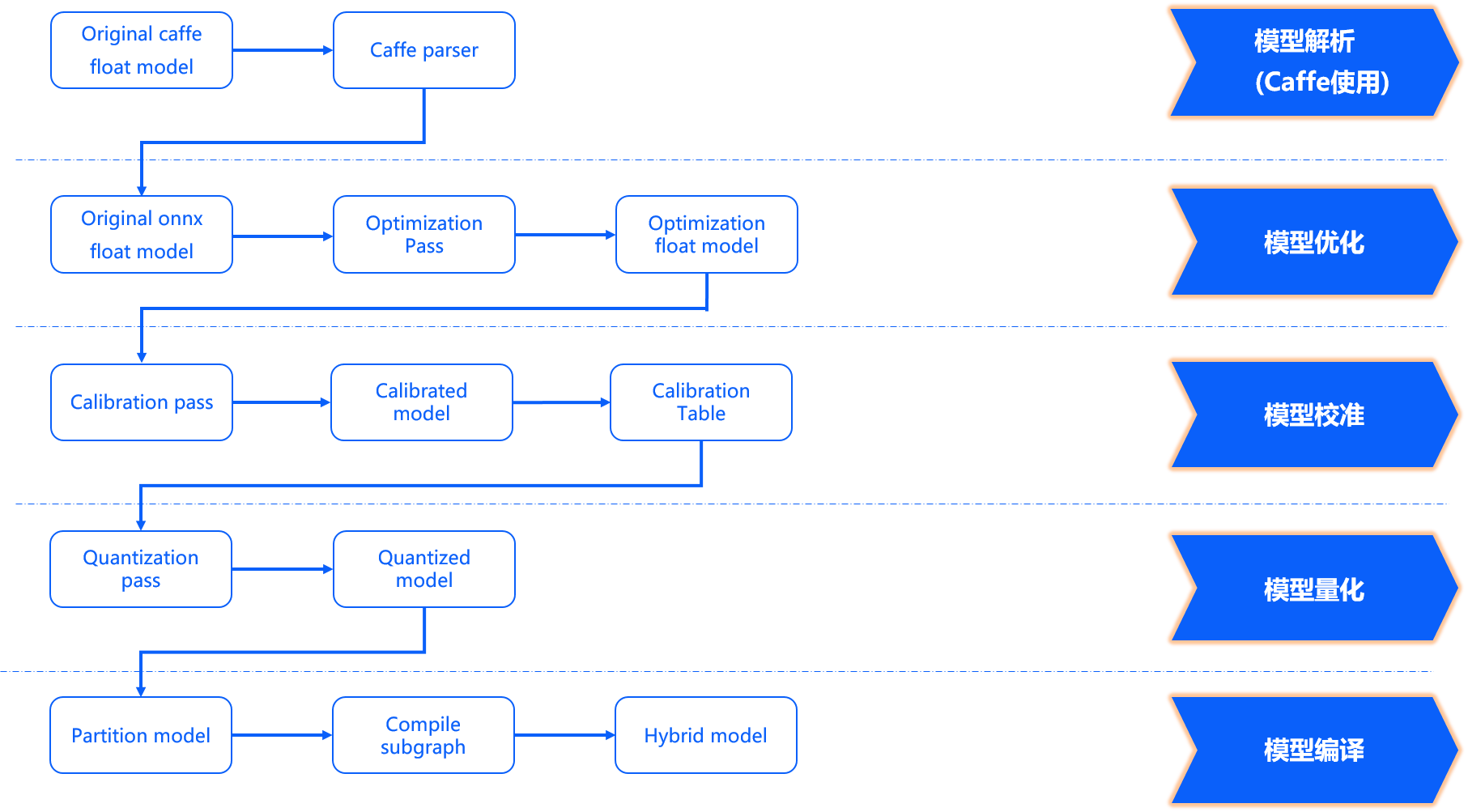
模型解析阶段 对于Caffe浮点模型会完成到ONNX浮点模型的转换。 在原始浮点模型上会根据转换配置中的配置参数决定是否加入数据预处理节点,此阶段产出一个original_float_model.onnx。 这个ONNX模型计算精度仍然是float32,在输入部分加入了一个数据预处理节点。
理想状态下,这个预处理节点应该完成 input_type_rt 到 input_type_train 的完整转换, 实际情况是整个type转换过程会配合地平线处理器硬件完成,ONNX模型里面并没有包含硬件转换的部分。 因此ONNX的真实输入类型会使用一种中间类型,这种中间类型就是硬件对 input_type_rt 的处理结果类型, 数据layout(NCHW/NHWC)会保持原始浮点模型的输入layout一致。 每种 input_type_rt 都有特定的对应中间类型,如下表:
nv12 | yuv444 | rgb | bgr | gray | featuremap |
|---|---|---|---|---|---|
yuv444_128 | yuv444_128 | RGB_128 | BGR_128 | GRAY_128 | featuremap |
注解
表格中第一行加粗部分是 input_type_rt 指定的数据类型,第二行是特定 input_type_rt 对应的中间类型, 这个中间类型就是original_float_model.onnx的输入类型。其中:
*_128指的是其数据类型减去128的结果,每个数值采用int8表示。
featuremap 是一个张量数据,每个数值采用float32表示。
模型优化阶段 实现模型的一些适用于地平线平台的算子优化策略,例如BN融合到Conv等。 此阶段的产出是一个optimized_float_model.onnx,这个ONNX模型的计算精度仍然是float32,经过优化后不会影响模型的计算结果。 模型的输入数据要求还是与前面的original_float_model一致。
模型校准阶段 会使用您提供的校准数据来计算必要的量化参数,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中,此阶段的产出是calibrated_model.onnx。
模型量化阶段 使用校准得到的参数完成模型量化,此阶段的产出是一个quantized_model.onnx。 这个模型的计算精度已经是int8,使用这个模型可以评估到模型量化带来的精度损失情况。 这个模型要求输入的基本数据格式和layout仍然与 original_float_model 一样,不过取值范围已经发生了变化, 整体较于 original_float_model 输入的变化情况描述为:
当 input_type_rt 的取值为非 featuremap 时,则输入的数据类型均使用INT8, 反之, 当 input_type_rt 取值为 featuremap 时,则输入的数据类型则为float32。
数据排布layout关系为:input_layout_train以及origin.onnx、calibrated_model.onnx、quanti.onnx输入的layout与原模型输入的layout一致。
注意
请注意,如果input_type_rt为nv12,对应quanti.onnx的输入layout都是NHWC。
模型编译阶段 会使用地平线模型编译器,将量化模型转换为地平线平台支持的计算指令和数据, 这个阶段的产出一个*.bin模型,这个bin模型是后续将在地平线边缘嵌入式平台运行的模型,也就是模型转换的最终产出结果。
6.3.4.3. 转换结果解读
本节将依次介绍模型转换成功状态的解读、转换不成功的分析方式。
确认模型转换成功,需要您从 makertbin 状态信息、相似度信息和 working_dir 产出三个方面确认。 makertbin 状态信息方面,转换成功将在控制台输出信息尾部给出明确的提示信息如下:
相似度信息也存在于 makertbin 的控制台输出内容中,在 makertbin 状态信息之前,其内容形式如下:
上面列举的输出内容中:
Node、ON、Subgraph、Type与 hb_mapper checker 工具的解读是一致的,请参考前文 检查结果解读 。
Cosine Similarity反映的Node指示的节点中,原始浮点模型与量化模型输出结果的余弦相似度。
Threshold是每个层次的校准阈值,用于异常状态下向地平线技术支持反馈信息,正常状况下不需要关注。
注意
需要您特别注意的是,Cosine Similarity只是指明量化后数据稳定性的一种参考方式,对于模型精度的影响不存在明显的直接关联关系。 一般情况下,输出节点的相似度低于0.8就有了较明显的精度损失,当然由于与精度不存在绝对的直接关联, 完全准确的精度情况还需要您参考 模型精度分析 的介绍。
转换产出存放在转换配置参数 working_dir 指定的路径中,成功完成模型转换后, 您可以在该目录下得到以下文件(*部分是您通过转换配置参数 output_model_file_prefix 指定的内容):
*_original_float_model.onnx
*_optimized_float_model.onnx
*_calibrated_model.onnx
*_quantized_model.onnx
*.bin
转换产出物解读 介绍了每个产出物的用途。 不过在上板运行前,我们强烈建议您完成 模型性能分析 和 模型精度分析 章节介绍的性能&精度评测过程,避免将模型转换问题延伸到后续嵌入式端。
如果以上验证模型转换成功的三个方面中,有任一个出现缺失都说明模型转换出现了错误。 一般情况下, makertbin 工具会在出现错误时将错误信息输出至控制台, 例如我们在Caffe模型转换时不配置 prototxt 和 caffe_model 参数,工具给出如下提示。
如果以上步骤不能帮助您发现问题,欢迎在 地平线智能汽车开发者社区 提出您的问题, 我们将在24小时内给您提供支持。
6.3.4.4. 转换产出物解读
上文提到模型成功转换的产出物包括以下部分,本节将介绍每个产出物的用途:
*_original_float_model.onnx
*_optimized_float_model.onnx
*_calibrated_model.onnx
*_quantized_model.onnx
*.bin
*_original_float_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型计算精度与转换输入的原始浮点模型是一模一样的,有个重要的变化就是为了适配地平线平台添加了一些数据预处理计算。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
*_optimized_float_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型经过一些算子级别的优化操作,常见的就是算子融合。 通过与original_float模型的可视化对比,您可以明显看到一些算子结构级别的变化,不过这些都不影响模型的计算精度。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
*_calibrated_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型是模型转换工具链将浮点模型经过结构优化后,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中得到的中间产物。
*_quantized_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型已经完成了校准和量化过程,量化后的精度损失情况可以从这里查看。 这个模型是精度验证过程中必须要使用的模型,具体使用方式请参考 模型精度分析 部分的介绍。
*.bin就是可以用于在地平线计算平台上加载运行的模型, 配合 嵌入式应用开发指导 部分介绍的内容, 您就可以将模型快速在计算平台上部署运行。不过为了确保模型的性能与精度效果是符合您的预期的, 我们强烈建议完成 模型性能分析 和 模型精度分析 介绍的性能和精度分析过程后再进入到应用开发和部署。
6.3.5. 模型性能分析
本节介绍了如何使用地平线提供的工具评估模型性能。 如果此阶段发现评估结果不符合预期,强烈建议您尽量在此阶段参考 模型性能调优 章节的内容尝试调优,解决性能问题, 不建议将模型的问题延伸到应用开发阶段。
6.3.5.1. 使用 hb_perf 工具估计性能¶
地平线提供的 hb_perf 以模型转换得到的 *.bin为输入,可以直接得到模型预期上板性能(不含CPU部分的计算评估),工具使用方式如下:
注解
如果分析的是 pack 后模型,需要加上一个 -p 参数,命令为 hb_perf -p ***.bin。 关于模型 pack,请查看 hb_pack 工具 部分的介绍。
命令中的 *.bin就是模型转换产出的bin模型,命令执行完成后, 在当前工作目录下会得到一个 hb_perf_result 目录,分析结果以html形式提供。
以下是我们分析一个MobileNet的示例结果,其中mobilenetv1_224x224_nv12.html就是查看分析结果的主页面。
通过浏览器打开结果主页面,其内容如下图:
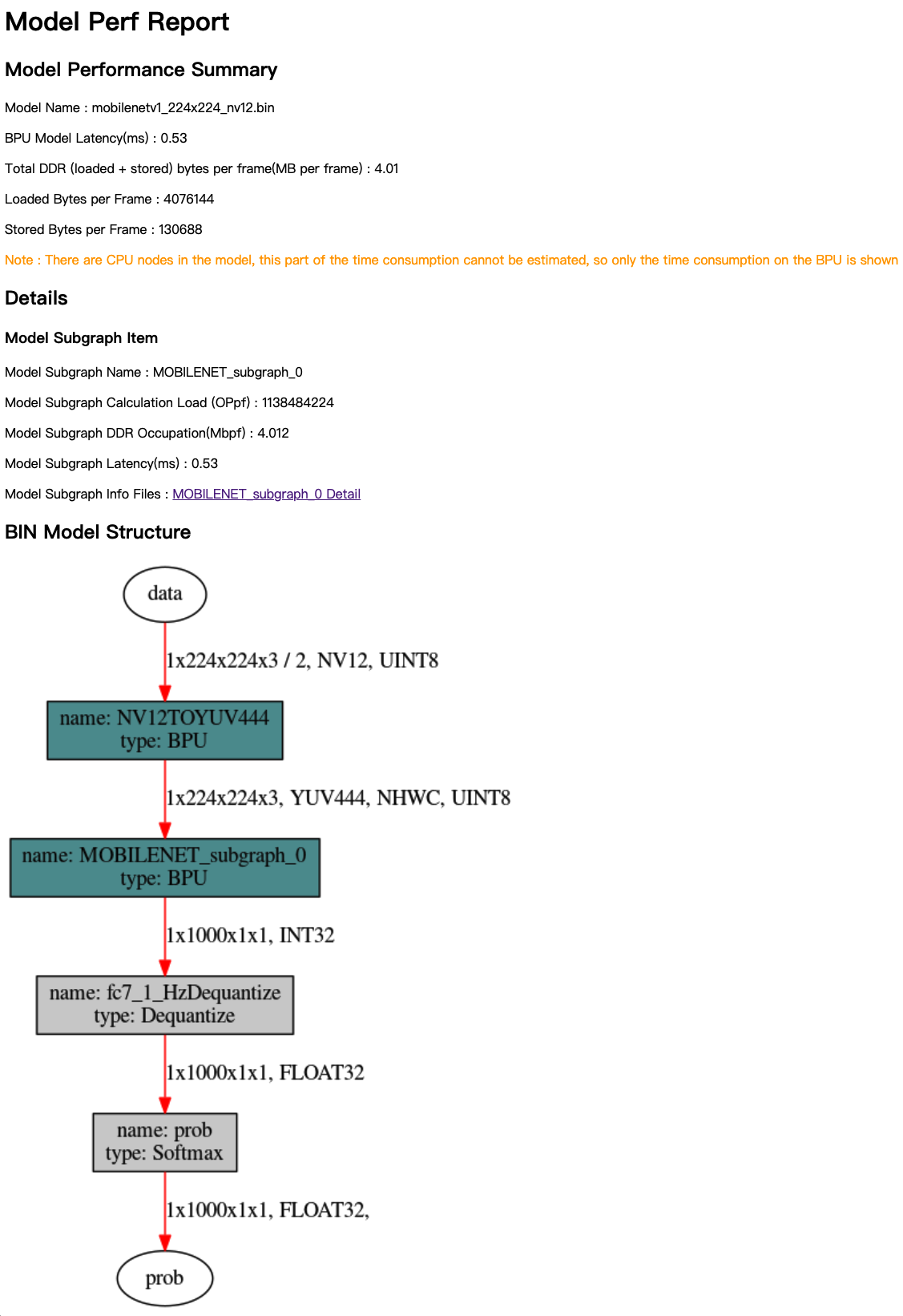
分析结果主要由Model Performance Summary、Details和BIN Model Structure三个部分组成。 Model Performance Summary是整个bin模型的整体性能评估结果,其中各项指标为:
Model Name:模型名称。
BPU Model Latency(ms):模型整体单帧计算耗时(单位为ms)。
Total DDR (loaded+stored) bytes per frame(MB per frame):模型整体BPU部分数据加载和存储所占用的DDR总量(单位为MB/frame)。
Loaded Bytes per Frame:模型运行每帧读取数据量。
Stored Bytes per Frame:模型运行每帧存储数据量。
在了解Details和BIN Model Structure前,您需要了解子图(subgraph)的概念。 如果模型在非输入和输出部分出现了CPU计算的算子,模型转换工具将把这个算子前后连续在BPU计算的部分拆分为两个独立的子图(subgraph)。 具体可以参考 验证模型 部分的介绍。
Details是每份模型BPU子图的具体信息,在主页面中,每个子图提供的指标解读如下:
Model Subgraph Name:子图名称。
Model Subgraph Calculation Load (OPpf):子图的单帧计算量。
Model Subgraph DDR Occupation(Mbpf):子图的单帧读写数据量(单位为MB)。
Model Subgraph Latency(ms):子图的单帧计算耗时(单位为ms)。
每份子图结果提供了一个明细入口,以上指标都是明细页面提取到的,进入到明细页面可以给您更加细致的参考信息。
注意
需要特别注意的是,明细页面会根据您是否启用调试参数( debug )而有所区别, 下方的Layer Details仅当在配置文件中设置 debug 参数为 True 时才可以拿到, 这个 debug 参数配置方法请参考 编译参数组 内对该参数的介绍。
BIN Model Structure部分提供的是bin模型的子图级可视化结果,图中深色节点表示运行在BPU上的节点,灰色节点表示在CPU上计算的节点。
Layer Details提供到了具体算子级别的分析,在调试分析阶段也是比较不错的参考, 如果是某些BPU算子导致性能低,可以帮助您定位到这个具体算子。
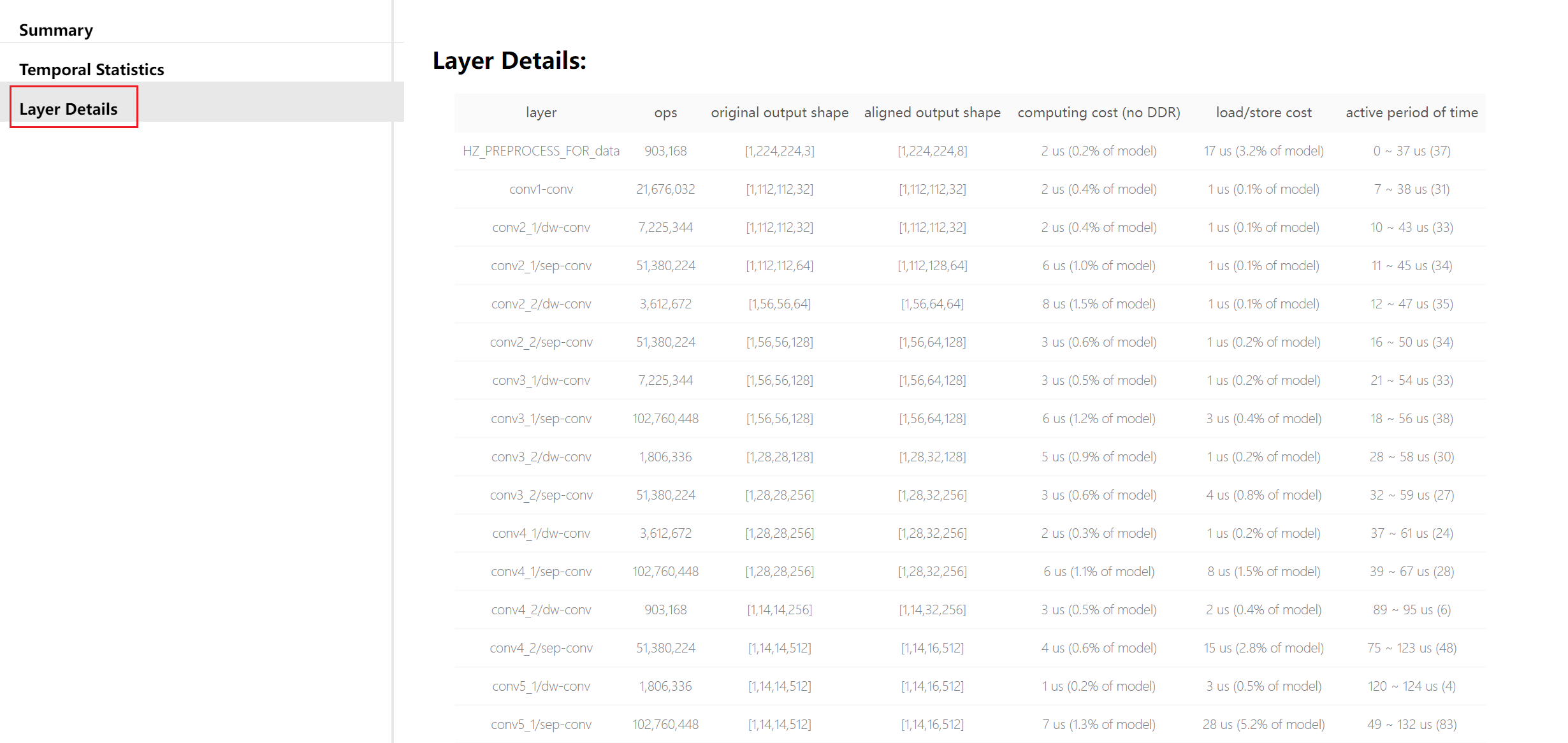
其中,每项指标解读如下:
layer:layer名。
ops:计算量。
original output shape:原始算子输出shape。
aligned output shape:对齐后的算子输出shape。
computing cost (no DDR):计算耗时。
load/store cost:数据搬运耗时。
active period of time:编译后layer活跃时间段(不代表该layer执行时间,通常为多个layer交替/并行执行)。
使用 hb_perf 的意义在于了解bin模型子图结构,对于BPU上计算部分,该工具也能提供较全面的静态分析指标。 不过 hb_perf 不含CPU部分的计算评估,如果CPU计算仅限于模型输入或输出部分的常规性处理,不含计算密集型计算节点,这个影响不大。 否则,您就一定需要利用开发板工具实测性能。
6.3.5.2. 开发板实测性能
开发板上实测模型性能使用的是开发板上 hrt_model_exec perf 工具, hrt _model_exec 是一个模型执行工具,可直接在开发板上评测模型的推理性能、获取模型信息。 一方面可以让您在拿到模型时实际了解模型真实性能,另一方面也可以帮助您了解模型可以做到的速度极限,对于应用调优的目标极限具有指导意义。
使用 hrt_model_exec perf 工具前,有两个准备工作。
确保您已经参考 环境部署 介绍完成了开发板上工具安装。
第二是需要将Ubuntu开发机上得到的bin模型拷贝到开发板上(建议放在/userdata目录), 开发板上是一个Linux系统,可以通过 scp 等Linux系统常用方式完成这个拷贝过程。
注解
此时使用的模型不需要打开debug,debug打开会影响模型在开发板的测试结果。
使用 hrt_model_exec perf 实测性能的参考命令如下(注意是在开发板上执行):
其中,各参数含义如下:
参数 | 说明 |
|---|---|
model_file | 需要分析性能的bin模型名称。 |
model_name | 需要分析性能的bin模型名字。若 model_file 只含一个模型,则可以省略。 |
core_id | 默认值 0,运行模型使用的核心id, 0 代表任意核心, 1 代表核心0, 2 代表核心1。若要分析双核极限帧率,请将此处设为 0。 |
frame_count | 默认值 200,设置推理帧数,工具会执行指定次数后再分析平均耗时。 当 perf_time 为 0 时生效。 |
perf_time | 默认值 0,单位分钟。设置推理时间,工具会执行指定时间后再分析平均耗时。 |
thread_num | 默认值 1,设置运行的线程数,取值范围 [1,8]。若要分析极限帧率,请将线程数改大。 |
profile_path | 默认关闭,统计工具日志产生路径。该参数引入的分析结果会存放在指定目录下的profiler.log和profiler.csv文件中。 |
命令执行完成后,您将在控制台得到如下结果。 最终的评估结果就是 Average latency 和 Frame rate,分别表示平均单帧推理延时和模型极限帧率。 如果想获得模型在板子上运行的极限帧率,需将 thread_num 设置得足够大。
控制台得到的信息只有整体情况,通过 profile_path 控制产生的 profiler.log 和 profiler.csv 文件记录了更加丰富的信息如下:
这里的内容会对应到 使用hb_perf工具估计性能 中的BIN Model Structure部分介绍的bin可视化图中, 图中每个节点都有一个对应节点在profiler.log文件中, 可以通过 name 对应起来。 profiler.log 文件中记录了每个节点的执行时间,对优化节点有重要的参考意义。
由于模型中的BPU节点对输入输出有特殊要求,如特殊的layout和padding对齐要求,因此需要对BPU节点的输入、输出数据进行处理:
Preprocess:表示对模型输入数据进行padding和layout转换操作,其耗时统计在Preprocess中。
xxxx_input_layout_convert: 表示对BPU节点的输入数据进行padding和layout转换的操作,其耗时统计在xxxx_input_layout_convert中。
xxxx_output_layout_convert: 表示对BPU节点输出数据进行去掉padding和layout转换的操作,其耗时统计在xxxx_output_layout_convert中。
profiler 分析是经常使用的操作,前文 检查结果解读 部分提到检查阶段不用过于关注CPU算子, 此阶段就能看到CPU算子的具体耗时情况了,如果根据这里的评估认为CPU耗时太长,那就值得优化了。
6.3.6. 模型精度分析
基于几十或上百张校准数据实现浮点模型到定点模型转换的后量化方式,不可避免地会存在一定的精度损失。 但经过大量实际生产经验验证,如果能筛选出最优的量化参数组合,地平线的转换工具在大部分情况下,都可以将精度损失保持在1%以内。
本节先介绍了如何正确地进行模型精度分析,如果通过评估发现不及预期,则可以参考 PTQ模型精度调优 章节的内容尝试调优, 实在无法解决可寻求地平线的技术支持。
在进入到此部分介绍前,我们希望您已经了解如何对一个模型进行精度评测。本节介绍的内容是如何使用模型转换的产出物进行推理。
前文提到模型成功转换的产出物包括以下几个部分:
*_original_float_model.onnx
*_optimized_float_model.onnx
*_calibrated_model.onnx
*_quantized_model.onnx
*.bin
虽然最后的bin模型才是将部署到计算平台的模型,考虑到方便在Ubuntu开发机上完成精度评测, 我们提供了*_quantized_model.onnx完成这个精度评测的过程。 quantized模型已经完成了量化,与最后的bin模型具有一致的精度效果。 使用地平线开发库加载ONNX模型推理的基本流程如下所示,这份示意代码不仅适用于quantized模型, 对original和optimized模型同样适用,根据不同模型的输入类型和layout要求准备数据即可。
此外,输入数据准备过程是最容易出现误操作的部分。 较于您设计&训练原始浮点模型的精度验证过程,我们需要您在数据预处理后将推理输入数据进一步调整, 这些调整主要是数据格式(RGB、NV12等)、数据精度(int8、float32等)和数据排布(NCHW或NHWC)。 至于具体怎么调整,这个是由您在模型转换时设置的 input_type_train 、 input_layout_train 、 input_type_rt 和 input_layout_rt 四个参数共同决定的, 其详细规则请参考 转换内部过程解读 部分的介绍。
举个例子,有一个使用ImageNet训练的用于分类的原始浮点模型,它只有一个输入节点。 这个节点接受BGR顺序的三通道图片,输入数据排布为NCHW。原始浮点模型设计&训练阶段,验证集推理前做的数据预处理如下:
图像长宽等比scale,短边缩放到256。
center_crop 方法获取224x224大小图像。
按通道减mean。
数据乘以scale系数。
使用地平线转换这个原始浮点模型时, input_type_train 设置 bgr 、 input_layout_train 设置 NCHW 、 input_type_rt 设置 bgr 、 input_layout_rt 设置 NHWC 。
根据 转换内部过程解读 部分介绍的规则, *_quantized_model.onnx接受的输入应该为bgr_128、NCHW排布。 对应到前文的示例代码, your_custom_data_prepare 部分提供的数据处理应该一个这样的过程: