
10.4.1. 前言
DSP示例包展示了如何在J5上使用dsp进行任务处理。DSP示例包中包含CV示例和NN示例:
CV示例中封装了常见的cv api,并通过Sample介绍了各个api的使用方法,包含BilateralFilter、BoxFilter、Canny、Cornerharris、CvtColor、Dilate、EqualizeHist、Erode、Filter2D、Flip、GaussianBlur、Integral、MedianBlur、PyrDown、PyrUp、Remap、Resize、RoiResize、Rotate、SepFilter2D、Sobel、Threshold、Transpose、warpAffine、WarpPerspective算子。
NN示例中包含quantize、dequantize、softmax、pointpillar和centerpoint前处理算子api,并展示了示例用法。
各个示例主要分为arm侧和dsp侧两部分,其中arm侧负责准备数据然后发起rpc调用,dsp侧负责接收arm侧发来的任务,完成任务计算,将结果发送给arm。
开发者可以体验并基于该示例进行应用开发,降低开发门槛。
10.4.2. 交付物说明
交付物主要包括以下内容:
名称 | 内容 |
|---|---|
vdsp_rpc_sample | 包含示例源代码和运行脚本。 |
10.4.2.1. 示例代码包¶
示例包结构如下所示:
arm:arm侧示例,封装了常用api,主要负责发起RPC调用,接收dsp处理结果。
cv:cv示例,包含了图片处理的cv算子示例。在当前示例中,输入图片input.jpg的stride属性等于width属性的字节长度。
nn:nn示例,包含quantize和dequantize api,自定义算子softmax,pointpillar和centerpoint前处理。
dsp:dsp侧示例,实现了dsp算子功能,主要负责接收arm侧发来的任务,完成softmax等算子的计算,将结果发送给arm。
src:包含quantize和dequantize api,以及自定义算子softmax,pointpillar和centerpoint前处理的dsp侧实现。
script:示例的生成文件及脚本目录。
cv:包含cv示例的可执行文件、输入数据及执行脚本。
nn:包含nn示例的可执行文件、输入数据、模型及执行脚本。
image: DSP镜像目录。
lib: 可执行程序的依赖库目录。
deps:所有示例的依赖文件目录。
aarch64:arm侧的依赖目录。
vdsp:dsp侧的依赖目录。
10.4.3. 环境构建¶
10.4.3.1. 开发板准备¶
拿到开发板后,按照 系统镜像升级 中的说明,升级系统镜像到示例包推荐的系统镜像版本。
确保本地开发机和开发板可以远程连接。
10.4.3.2. 编译¶
10.4.3.2.1. ARM侧编译
编译需要当前环境安装好交叉编译工具gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu。 设置环境变量 LINARO_GCC_ROOT 为交叉编译工具的实际安装位置:
10.4.3.2.1.1. 编译CV示例
执行 vdsp_rpc_sample/arm/cv 目录下的build_arm.sh即可编译真机环境下的可执行程序,可执行程序和对应依赖会自动复制到 vdsp_rpc_sample/script/cv 目录下。
10.4.3.2.1.2. 编译NN示例¶
执行 vdsp_rpc_sample/arm/nn 目录下的build_arm.sh即可编译真机环境下的可执行程序,可执行程序和对应依赖会自动复制到 vdsp_rpc_sample/script/nn 目录下。
10.4.3.2.2. DSP侧编译
可从地平线获取 Xplorer-9.0.17-linux-x64-installer.bin 和 vdsp_vp6_RI4_linux-21.7.tgz 安装包。安装及配置方法请参考 安装DSP工具链及配置核 章节。
执行 vdsp_rpc_sample/dsp 目录下的 build_dsp.sh 脚本即可一键编译dsp镜像到 vdsp_rpc_sample/script/image 目录下。
10.4.4. 示例使用
10.4.4.1. DSP侧
推荐您运行dsp_deploy.sh部署dsp镜像,也可以参考如下命令启动:
准备一块J5开发板,设置dsp镜像名称,可以先通过以下命令确认镜像名称是否需要重设:
若镜像名称不是vdsp0和vdsp1,则重新设置dsp镜像名称,命令为:
停止dsp运行,停止命令为:
停止成功后,将 vdsp_rpc_sample/script/image 目录下编译出来的两个镜像vdsp0和vdsp1拷贝到J5开发板上替换掉 /system/lib/firmware/ 目录下的vdsp0和vdsp1。
注解
1.若dsp核处于stop状态下,执行上述命令会报错,但可以忽略;
2.加密板子需要更换目录的权限之后才能够替换镜像,具体方法可以参照下文中的示例。
重新启动dsp镜像,命令为:
注解
在替换新的dsp镜像前一定要先卸载正在运行的dsp镜像,替换完镜像后最好重新启动系统。
在上述步骤中,若开发板是加密板子则 /system/lib/firmware/ 目录是不允许修改的,此时需要采取其他方法实现替换vdsp镜像的目的,下面介绍两种方法,若用户有其他方法也可自行实施。
方法一,使用mount指令把自定义路径挂载到系统路径。
方法二,修改dsp镜像路径的配置。
10.4.4.2. ARM侧
10.4.4.2.1. 运行CV示例
将 vdsp_rpc_sample/script 目录拷贝到J5开发板上,然后运行 script/cv 目录下的 run_cv_test.sh 脚本,RPC默认以中继模式运行(脚本在$PATH中加入 dsp_relay_server 所在路径)。 脚本会默认执行一遍所有cv算子的示例程序,用户也可以通过追加参数的形式指定需要执行的算子(可以通过在脚本中追加参数help来显示所有可执行算子)。 算子默认读取的图片路径为 data/input.jpg ,输出图片的路径为 output 。
10.4.4.2.2. 运行NN示例¶
将 vdsp_rpc_sample/script 目录拷贝到J5开发板上,然后运行 script/nn 目录下的 run_nn_test.sh 脚本 , RPC默认以中继模式运行(脚本在$PATH加入 dsp_relay_server 所在路径)。 为了测试DNN plugin功能,脚本中添加环境变量 HB_DNN_PLUGIN_PATH ,变量指向libhb_dsp_nn_plugin.so路径,并添加 export HB_DNN_ENABLE_DSP=1 使能DNN将算子派发到DSP上执行。 脚本会执行一次NN示例,包括quantize示例、dequantize示例、softmax示例、pointpillar和centerpoint前处理示例、以及mobilentv1的推理任务,输出top5的分类, 用户也可以通过追加参数的形式指定需要执行的算子(可以通过在脚本中追加参数help来显示所有可执行算子)。 pointpillar和centerpoint前处理算子默认从 data 目录获取点云数据,您可以通过命令行参数来指定点云数据的路径。 处理后的数据将被转储到 output 路径中。
10.4.5. CenterPoint点云前处理介绍
为了更好地帮助您理解DSP示例包提供的 CenterPoint 五维点云前处理,本文从算法原理出发,分析CPU和DSP参考实现,同时对CPU和DSP参考实现进行一致性校验和性能评测。示例包中同时也提供了 PointPillars 四维点云前处理,与 CenterPoint 类似, 两者前处理的主要特点是通过体素化生成柱体( pillars )。本章节主要介绍 CenterPoint 前处理实现,另外用单独的一节介绍 PointPillars 前处理在实现上的不同之处。
10.4.5.1. 原理介绍
本文使用五维 CenterPoint 模型作为示例介绍,其相应的原理和前处理算法实现也可适用于四维的 PointPillars 模型。模型的输入为五维点云数据,最大点数为30万。前处理主要由体素化,特征编码,量化和转置组成。前处理输出 1x5x20x40000(nchw) 的特征图和 1x1x40000x4(nhwc) 的坐标信息。

10.4.5.1.1. 体素化¶
根据输入的五维点云数据的 x , y 坐标计算出柱体的坐标,最大的柱体数目为 40000 ,每个柱体最大支持的点数为 20 。柱体坐标的计算原理如下:
判断点云的 x , y , z 是否在有效的范围内,跳过无效的点云数据。
点云的 x , y 信息可以被视为伪图像,伪图像中的每一个像素对应一个柱体坐标。
输入点云的坐标是无序的,因此需要按照坐标的输入顺序确定柱体坐标,当柱体数超过模型限制的最大值之后,不会生成新的柱体,而是将点写入到最后一个柱体中。
相同坐标的点会放入同一个柱体中,模型限制每一个柱体中点的数目,当超过最大限制时,则直接跳过该点。
体素化的伪代码实现如下所示:
10.4.5.1.2. 特征编码¶
点云数据的特征编码使用如下的公式:
 P0′=(P0−back)/(front−back)P1′=(P1−right)/(left−right)P2′=(P2−bottom)/(top−bottom)P3′=(P3−lower)/(upper−lower)P4′=P4
P0′=(P0−back)/(front−back)P1′=(P1−right)/(left−right)P2′=(P2−bottom)/(top−bottom)P3′=(P3−lower)/(upper−lower)P4′=P4
10.4.5.1.3. 量化¶
量化的 scale 可以通过模型获取,使用以下公式完成量化:
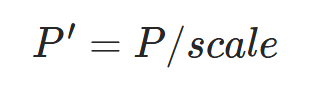
P′=P/scale
10.4.5.1.4. 转置¶
模型输入的特征图 layout 模式为 NCHW ,转置将特征图的 shape 从 1x40000x20x5 转换为 1x5x20x40000。
10.4.5.2. CPU参考实现
CPU参考实现的源码位于 AI Benchmark 中,其前处理基本流程与原理介绍部分保持一致,其中量化合并到特征编码步骤中。
10.4.5.2.1. 体素化¶
10.4.5.2.2. 特征编码 & 量化
10.4.5.2.3. 转置
10.4.5.3. DSP加速思路¶
主要从两个方面考虑算子在DSP上的加速实现,第一是算子的计算部分, J5上的DSP支持 512bit 的 SIMD ,因此将计算部分尽可能向量化可以充分利用DSP的算力。第二是算子的访存部分,J5上的DSP有两个 128kB 的 TCM ,其访存性能接近CPU上的cache,因此将数据尽可能搬移到 TCM上 ,能有效地节约访存的开销。同时DSP也提供向量化的访存指令,也可以提高访存的效率。
10.4.5.3.1. 向量化¶
对于五维模型,可以将计算过程分为5个 cycle ,每个 cycle 计算一个维度,使用 IVP 向量指令完成运算。
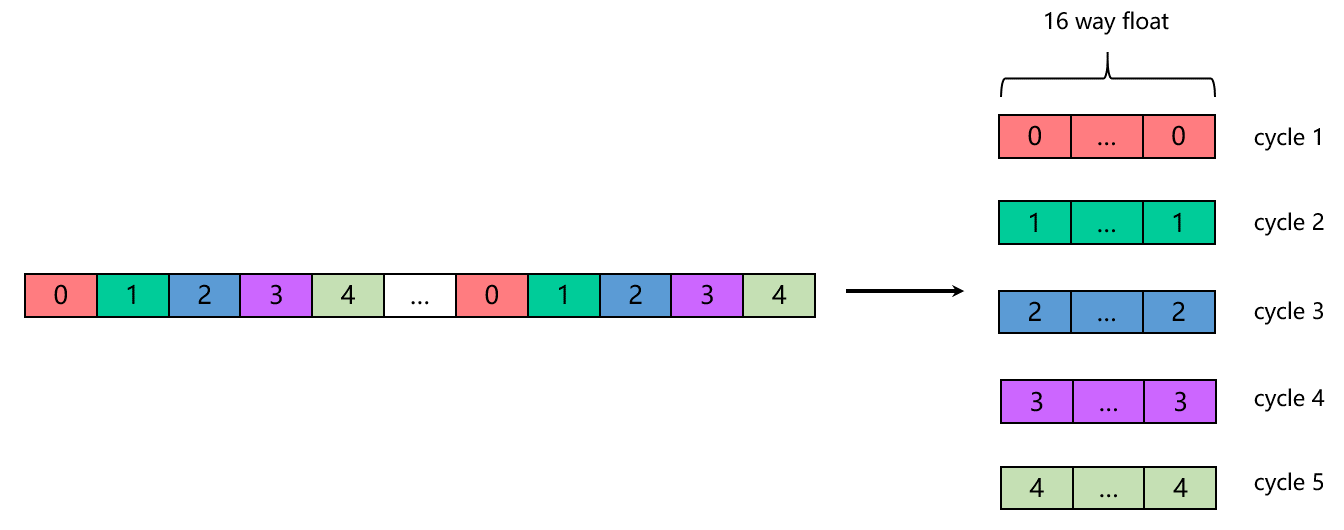
具体到 CenterPoint 点云前处理算法,在计算伪图像的坐标,特征编码以及量化等计算过程,都可以将每个维度独立计算,因此很容易转换成向量化的计算。
10.4.5.3.2. 访存优化¶
点云输入数据从 x , y 维度来看是无序的,导致计算出的柱体坐标和柱体中点的索引也是无序的,从而导致访存是随机而不是效率更高的顺序操作。由于DSP上没有 data cache ,随机访存非常不友好,因此需要充分利用DSP上的 TCM 。DSP上可用的 TCM 只有两个 128kB ,而特征数据输出的地址空间为 40000x20=781.25kB ,远大于 TCM 的内存大小。同时计算体素坐标时,也需要一个伪图像坐标与柱体坐标的查找表,该表所需的内存为 512x512x4=1MB ( 512 为伪图像的宽和高, 4 为柱体坐标所需的字节数),也是远远超出 TCM 的内存大小。考虑到将随机访存搬移到DSP代价太大,因此将前处理算法中的计算和访存进行分离,计算部分放到DSP上,而把部分随机访存放到CPU上执行。 同时为了减少访存的数据量,DSP加速实现调整了CPU实现的步骤,将特征编码和量化提前到计算伪图像坐标之后。通过这样的处理,后续的体素化和转置步骤访存所需的数据量将大大减少。 虽然这会增加更多的计算量,但是通过实际评测可见,减少访存数据量带来的收益会更大,特别是在有效点云数较大的情况下。
10.4.5.3.3. 分块策略
虽然有两个128kB的 TCM ,但是每一个计算周期只使用其中一个,原因主要有以下两个:
需要使用 Pingpong buffer ,减少等待数据拷贝完成的时间
Pingpong buffer 需要位于不同的 TCM 中,减少 data bank conflict
DSP上的计算被拆为两个部分,一个是计算伪图像坐标,特征编码和量化,另一个是转置。
计算伪图像坐标,特征编码和量化
每个计算周期,输入为五维点云数据( float32_t ),输出为伪图像坐标( int32_t ),量化后的 xyzr 维数据( int32_t )以及量化后加 padding 的 t 维数据( int32_t ),输入与输出比为 5:3 ,因此输入与输出的 TCM 内存大小比例也为 5:3 。当前可用于算子的 TCM 内存大小为 103kB ,考虑到内存管理元数据的内存占用和内存对齐, TCM 总共占用 80kB ,其中输入为 50kB ,输出为 30kB 。
转置
每个计算周期,输入为量化后的五维特征数据,输出为量化后的单维度特征数据,输入与输出比为 5:1 。因此输入 TCM 分配 75kB ,输出 TCM 分配为 15kB 。
10.4.5.4. DSP参考优化实现
DSP的 IVP 指令可以参考 Cadence 提供的文档 vdsp_vp6_RI4/html/ISA/NewISAhtml/index.html ,TCM内存管理接口的详细介绍可以参考 Xtensa Vision Tile Manager Library User’s Guide ,IDMA相关接口详细介绍可以参考 Xtensa System Software Reference Manual 。
10.4.5.4.1. 伪图像坐标计算,特征编码和转置(DSP计算部分)¶
伪图像坐标计算与CPU参考实现方法基本一致,主要区别有以下几点:
去掉一维坐标的计算,通过32位的高低16位存储伪图像 x 和 y 坐标(示例模型伪图像的宽高为 512 , 16 位已足够存储),同时以二维坐标作为索引,用于查找对应的柱体坐标。
在过滤无效的点云数据时,使用 mask move 取代条件判断语句。因为在内循环中使用条件判断会明显降低运算性能。
10.4.5.4.2. 体素化(CPU访存部分)¶
处理逻辑和CPU参考实现基本一致,主要有以下几点区别:
使用二维数组查找表,并且直接使用伪图像的 x , y 作为索引。
输出 voxel_data 的索引计算方式不同,因为DSP gather/scatter 不能超出 64kB 的地址空间限制,因此提前按照最终特征数据的 shape 进行计算输出索引。
10.4.5.4.3. 转置
将 AoS 格式的点云转置为 SoA 格式。
10.4.5.5. 一致性校验
分别导出CPU和DSP参考实现的点云前处理输出特征数据和坐标信息到文件,比对文件内容是否一致,如果一致则通过一致性校验。
在 AI Benchmark 中,可以执行完整的全流程精度评测,当前DSP参考实现与CPU参考实现精度完全一致。
提示
如果您不要求DSP实现的精度与CPU实现具有完全一致的精度,那么可以通过优化浮点运算来进一步提升性能。例如,通过将耗时的除法运算替换为乘法运算。
10.4.5.6. 性能评测¶
在 AI Benchmark 中,执行 CenterPoint 模型的延时测试,比较CPU和DSP参考实现的单帧延时。点云前处理的耗时与输入数据的分布,有效点云的数量相关,以下性能测试结果只反映当前测试数据集下的性能。
测试数据集:
单线程单帧延时测试结果:
实现 | avg | max | min |
|---|---|---|---|
CPU参考实现 | 119.374ms | 206.633ms | 57.109ms |
DSP参考实现(方案一) | 23.251ms | 31.437ms | 18.223ms |
DSP参考实现(方案二) | 16.126ms | 17.841ms | 15.042ms |
注解
DSP参考实现(方案二)为本章节描述的先量化输入点云数据的方案,而DSP参考实现(方案一)则是将特征编码和量化置于体素化之后的方案。 为了方便参考,这里列出了两种方案的相关性能评测数据。从数据中可以看成,引入更多的计算量可以有效减少访存数据,从而实现更高的性能收益。
10.4.5.7. PointPillars前处理实现简介¶
PointPillars 四维点云前处理与 CenterPoint 五维点云前处理的基本处理逻辑相同,主要有以下两点区别:
1.点云输入维度不同
2.点云前处理后的输出 layout 不同
针对以上两点差异,以下将分别阐述DSP加速实现上的不同之处:
1.点云输入维度不同
PointPillars 四维点云输入经过量化后,其数据大小正好适配 int32_t 类型,无需像 CenterPoint 那样对第五维量化后的数据进行 padding 操作以适配 int32_t 类型。
第一步计算伪图像坐标,特征编码和量化步骤的输入输出 TCM 大小比例不同。 CenterPoint 为 5:3 , PointPillar 为 2:1 ,输入为四维浮点点云数据( float32_t ),输出为伪图像坐标( int32_t )和量化后的 xyzr 数据( int32_t )
由于维度的差异,对输入点云的 gather 操作所需的 offset 计算不同.
2.点云前处理后的输出 layout 不同
在体素化(CPU访存)步骤中, voxel_data 的 offset 计算方式存在差异.
由于输出 layout 不同,转置部分的输入输出 TCM 大小比例存在差异。 CenterPoint 的比例为 5:1 ,而 PointPillars 的比例为 4:1 。
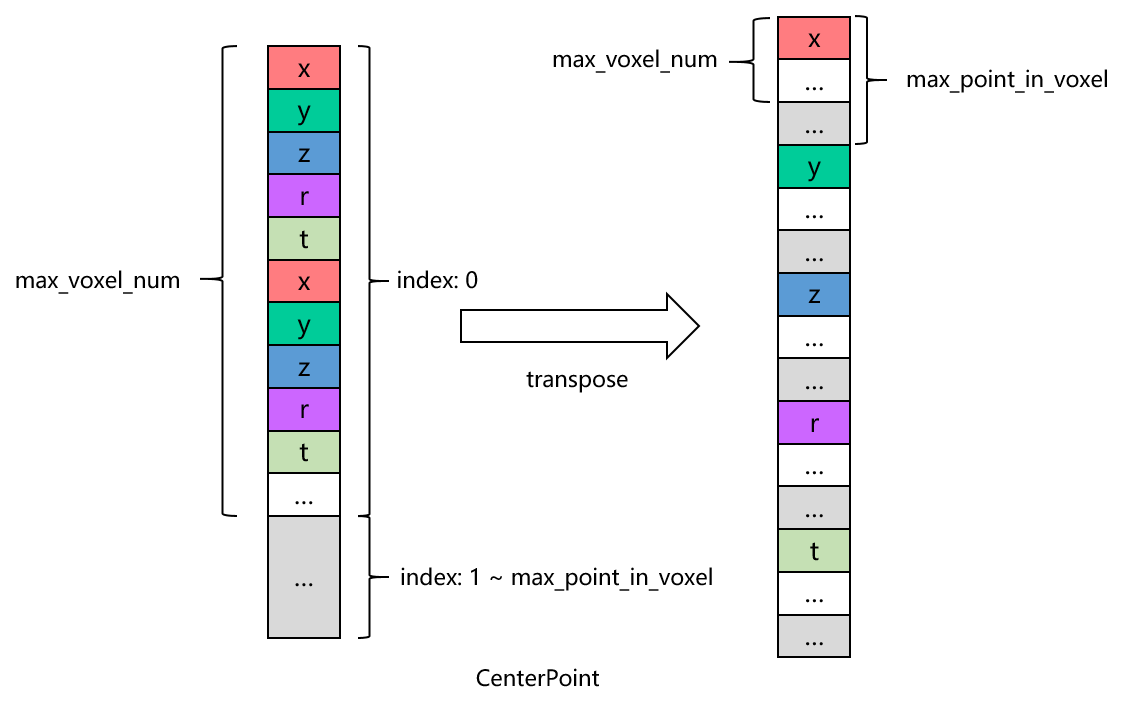
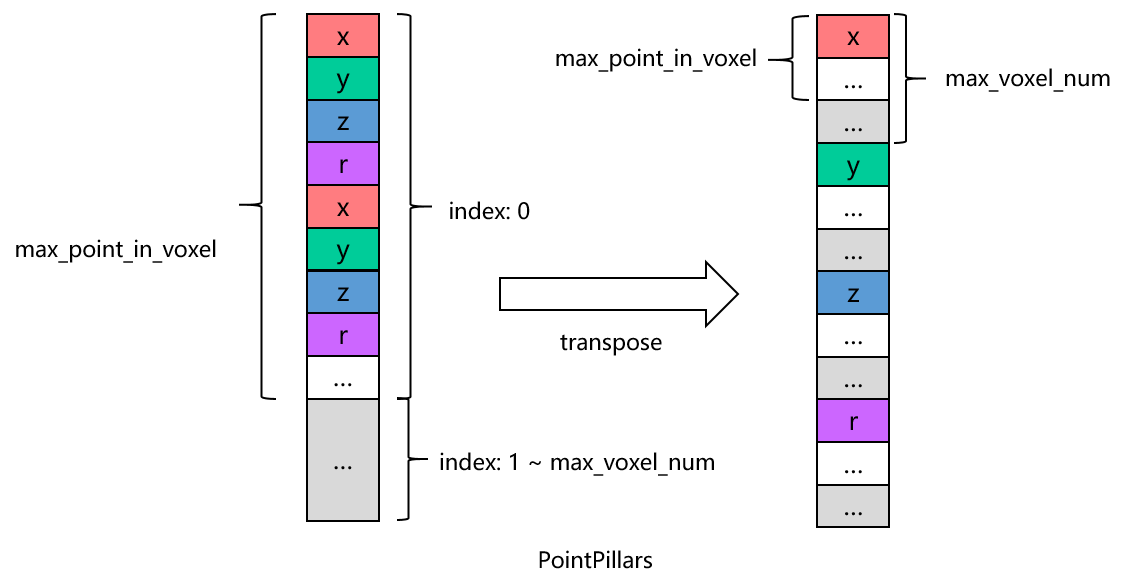
转置的处理逻辑不同,具体的差异参见下图。
CenterPoint:
PointPillars:
注解
根据图示, CenterPoint 和 PointPillars 在 max_point_in_voxel 和 max_voxel_num 的顺序上存在差异,这导致了无效数据的分别不同。 具体来说, PointPillars 的无效数据呈现出较为集中的分布特点,这有助于进行连续处理。 相反, CenterPoint 的无效数据则散布在各个 voxel 之间,呈现出交叉分布的特点。 前处理的参数对算子的实现效率会有一定影响,可以进一步考虑根据不同的参数实现特定的逻辑。