
7.3.1. 基本流程
量化感知训练工具的基本使用流程如下:
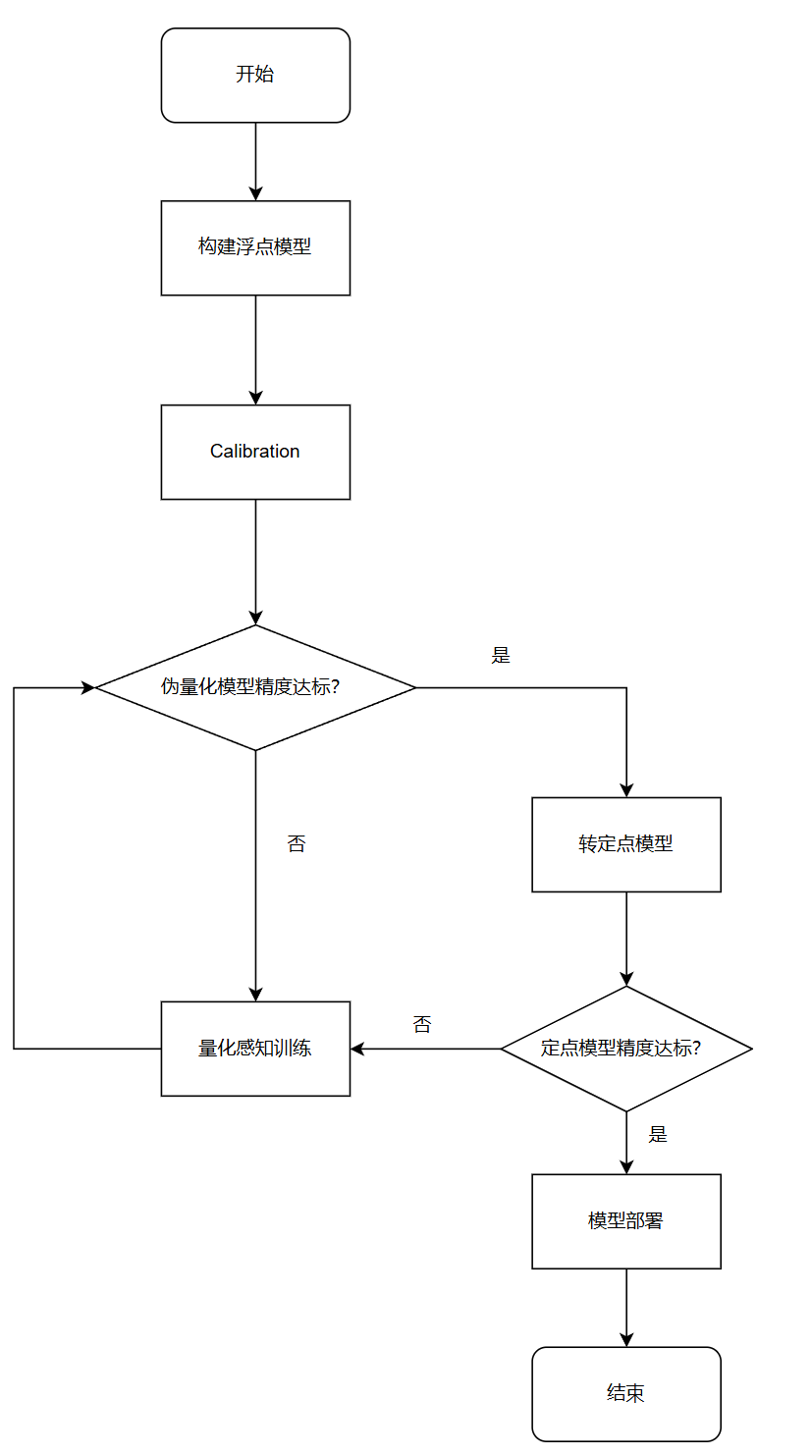
下面以 torchvision 中的 MobileNetV2 模型为例,介绍流程中每个阶段的具体操作。
出于流程展示的执行速度考虑,我们使用了 cifar-10 数据集,而不是 ImageNet-1K 数据集。另外,为了快速展示整体方法和流程,本教程未进行精细地调参提高模型精度,用户实际使用过程中可以根据需求进行调参。
7.3.2. 获取浮点模型
首先,对浮点模型做必要的改造,以支持量化相关操作。模型改造必要的操作有:
在模型输入前插入 QuantStub
在模型输出后插入 DequantStub
改造模型时需要注意:
插入的 QuantStub 和 DequantStub 必须注册为模型的子模块,否则将无法正确处理它们的量化状态
多个输入仅在 scale 相同时可以共享 QuantStub,否则请为每个输入定义单独的 QuantStub
若需要将上板时输入的数据来源指定为 "pyramid",请手动设置对应 QuantStub 的 scale 参数为 1/128
也可以使用 torch.quantization.QuantStub,但是仅有 horizon_plugin_pytorch.quantization.QuantStub 支持通过参数手动固定 scale
改造后的模型可以无缝加载改造前模型的参数,因此若已有训练好的浮点模型,直接加载即可,否则需要正常进行浮点训练。
注意
模型上板时的输入图像数据一般为 centered_yuv444 格式,因此模型训练时需要把图像转换成 centered_yuv444 格式(注意下面代码中对 rgb2centered_yuv 的使用)。
如果无法转换成 centered_yuv444 格式进行模型训练,请参考RGB888 数据部署章节中的介绍,对模型做相应的改造。(注意,该方法可能导致模型精度降低)
本示例中浮点和 QAT 训练的 epoch 较少,仅为说明训练工具使用流程,精度不代表模型最好水平。
7.3.3. Calibration
模型改造完成并完成浮点训练后,便可进行 Calibration。此过程通过在模型中插入 Observer 的方式,在 forward 过程中统计各处的数据分布情况,从而计算出合理的量化参数:
对于部分模型,仅通过 Calibration 便可使精度达到要求,不必进行比较耗时的量化感知训练。
即使模型经过量化校准后无法满足精度要求,此过程也可降低后续量化感知训练的难度,缩短训练时间,提升最终的训练精度。
模型经过 Calibration 后的量化精度若已满足要求,便可直接进行转定点模型的步骤,否则需要进行量化感知训练进一步提升精度。
7.3.4. 量化感知训练
量化感知训练通过在模型中插入伪量化节点的方式,在训练过程中使模型感知到量化带来的影响,在这种情况下对模型参数进行微调,以提升量化后的精度。
7.3.5. 转定点模型
伪量化精度达标后,便可将模型转为定点模型。一般认为定点模型的结果和编译后模型的结果是完全一致的。
注意
定点模型和伪量化模型之间无法做到完全数值一致,所以请以定点模型的精度为准。若定点精度不达标,需要继续进行量化感知训练。
7.3.6. 模型部署
测试定点模型精度并确认符合要求后,便可以进行模型部署的相关流程,包括模型检查、编译、性能测试和可视化。
注意
也可以跳过 Calibration 和量化感知训练中的实际校准和训练过程,先直接进行模型检查,以保证模型中不存在无法编译的操作。
由于编译器只支持 CPU,因此模型和数据必须放在 CPU 上。
根据提示,找到性能结果文件,内容如下: